전 게시글에서 조회하는 데 걸리는 시간과 비용을 줄이기 위해 populate, virtual을 사용했었다.
또 다른 방법으로는 블로그 내 있는 유저와 코멘트 데이터를 처음부터 nested 하는 것이다.

Blog Schema
위 이미지를 보면 Blog안에 User와 Comments 정보를 가지고 있는데 현재 내 Blog Schema에는 Comments는 아예 포함되어 있지 않고 User는 ObjectId만을 가지는 상태다.
const blogSchema = new Schema<IBlog>(
{
title: { type: String, required: true },
content: { type: String, required: true },
isLive: { type: Boolean, required: true, default: false },
user: { type: Types.ObjectId, required: true, ref: 'user' }
},
{ timestamps: true }
);
이런 스키마를 가지고 있는 경우 블로그의 유저와 코멘트 정보들을 가져오고 싶어 populate()과 virtual()을 사용했는데, 스키마 자체를 원하는 유저와 코멘트 정보 모두 포함시켜 보자.
const blogSchema = new Schema<IBlog>(
{
title: { type: String, required: true },
content: { type: String, required: true },
isLive: { type: Boolean, required: true, default: false },
user: {
_id: { type: Types.ObjectId, required: true, ref: 'user' },
username: { type: String, required: true },
name: {
first: { type: String, required: true },
last: { type: String, required: true },
},
},
comments: [commentSchema],
},
{ timestamps: true }
);바뀐 블로그 스키마는 유저 정보에 필요한 데이터를 더 추가해 주고 코멘트 같은 경우는 코멘트 스키마 자체를 배열에 넣어 블로그를 읽어올 때 원하는 모든 데이터를 한 번에 가져올 수 있게 했다. 이렇게 변경했으니 virtual과 populate은 더 이상 사용할 필요가 없다.
다만, 블로그 스키마를 변경했으니 특정 블로그를 생성하거나 변경할 때 추가적인 작업이 필요해진다. 그러니까 모든 게 다 장단점이 발생하는데 이렇게 블로그 스키마에 원하는 데이터 자체를 Nested 하면 조회는 더 적은 비용이 들지만 생성과 수정에 더 많은 비용이 들어간다. 그러니까 서비스에서 조회를 더 많이 하는지 생성과 수정을 더 많이 하는지 판단하여 적절하게 구조를 만들어 내는 게 중요하다.
확실히 조회 시 응답 속도는 현저히 줄었다. 왜냐하면 populate을 사용해 추가적인 유저나 코멘트 조회를 하지 않아도 되니 한 번의 조회만으로 원하는 모든 데이터를 가져올 수 있기 때문이다.
그럼 이제 생성과 수정 API를 수정해 보자.
Comment Create/Edit API
사실 생성 API는 변경할 많지 않다. Comment를 만들 때 필요한 작업은 그대로 변경할 필요가 없고 코멘트를 만들 때 블로그에 방금 생성한 Comment를 추가만 해주면 된다. 왜냐하면 이제 블로그 스키마에도 코멘트가 존재하니까.
// Create comment by blog id
blogRouter.post('/:blogId/comments', async (req, res) => {
try {
const { blogId } = req.params;
if (!mongoose.isValidObjectId(blogId))
return res.status(400).send({ error: 'Invalid blog id' });
const { content, userId } = req.body;
if (!mongoose.isValidObjectId(userId))
return res.status(400).send({ error: 'Invalid user id' });
if (!content)
return res.status(400).send({ error: 'content must be required' });
const [blog, user] = await Promise.all([
Blog.findOne({ _id: blogId }),
User.findOne({ _id: userId }),
]);
if (!blog || !user)
return res.status(400).send({ error: 'User or Blog does not exist' });
if (!blog.isLive)
return res.status(400).send({ error: 'Blog is not available' });
const comment = new Comment({ content, user, blog });
// 이 부분에서 Blog 업데이트하는 부분이 추가!
await Promise.all([
comment.save(),
Blog.updateOne({ _id: blogId }, { $push: { comments: comment } }),
]);
return res.status(201).send({ comment });
} catch (e: any) {
return res.status(500).send({ error: e.message });
}
});위 코드를 보면 Promise.all() 안에 처리하는 부분 중 이 부분이 추가되었다.
Blog.updateOne({ _id: blogId }, { $push: { comments: comment } }),$push를 사용해서 기존 코멘트들에 새로운(방금 만든) 코멘트를 추가한다.
중요한 변경 사항은 수정이다. 수정 API는 마찬가지로 변경 사항이 많은 것이 아니라 처리하는 방법에 대해서 알아볼 필요가 있다.
우선 변경 사항은 이와 같다.
blogRouter.patch('/:blogId/comments/:commentId', async (req, res) => {
const { commentId } = req.params;
const { content } = req.body;
if (!mongoose.isValidObjectId(commentId))
return res.status(400).send({ error: 'Invalid comment id' });
if (typeof content !== 'string')
return res.status(400).send({ error: 'content is required' });
const [comment] = await Promise.all([
Comment.findOneAndUpdate({ _id: commentId }, { content }, { new: true }),
Blog.updateOne(
{ 'comments._id': commentId },
{ 'comments.$.content': content }
),
]);
return res.send({ comment });
});여기서 코멘트 id를 이용해 코멘트를 찾아서 원하는 값으로 수정한다. 그 후 수정한 코멘트를 블로그에도 반영시켜줘야 한다.
그때 updateOne() 메서드를 사용하는데 첫 번째 인자는 블로그의 어떤 커멘트를 수정할지에 대한 쿼리, 두 번째 인자는 업데이트 사항이다.
첫 번째 인자로 { 'comments._id': commentId }로 들어오는데 comments._id는 MongDB 문법이다. 가지고 있는 코멘트들 중 id가 주어진 commentId와 같은 코멘트를 찾는다. 두 번째 인자로 { 'comments.$.content': content } 이 부분이 중요한데 여기서 '$'가 의미하는 건 첫 번째 인자의 쿼리문으로 찾은 객체를 담고 있다.
공식 문서가 말하기를, Array Update Operators 중 하나인 $는 배열의 특정 원소를 나타내며 명시적으로 배열의 인덱스를 나타내지 않고 업데이트시킬 수 있다. 그래서 db.collection.updateOne() 또는 db.collection.findAndModify() operation을 할 때 사용할 수 있으며 이 $가 나타내는 건 쿼리에 매치되는 첫 번째 원소를 대체한다.
이렇게 수정한 후 실제로 테스트해보자.
Comment Update
우선 특정 블로그의 코멘트가 무엇이 있는지 확인해 보자.
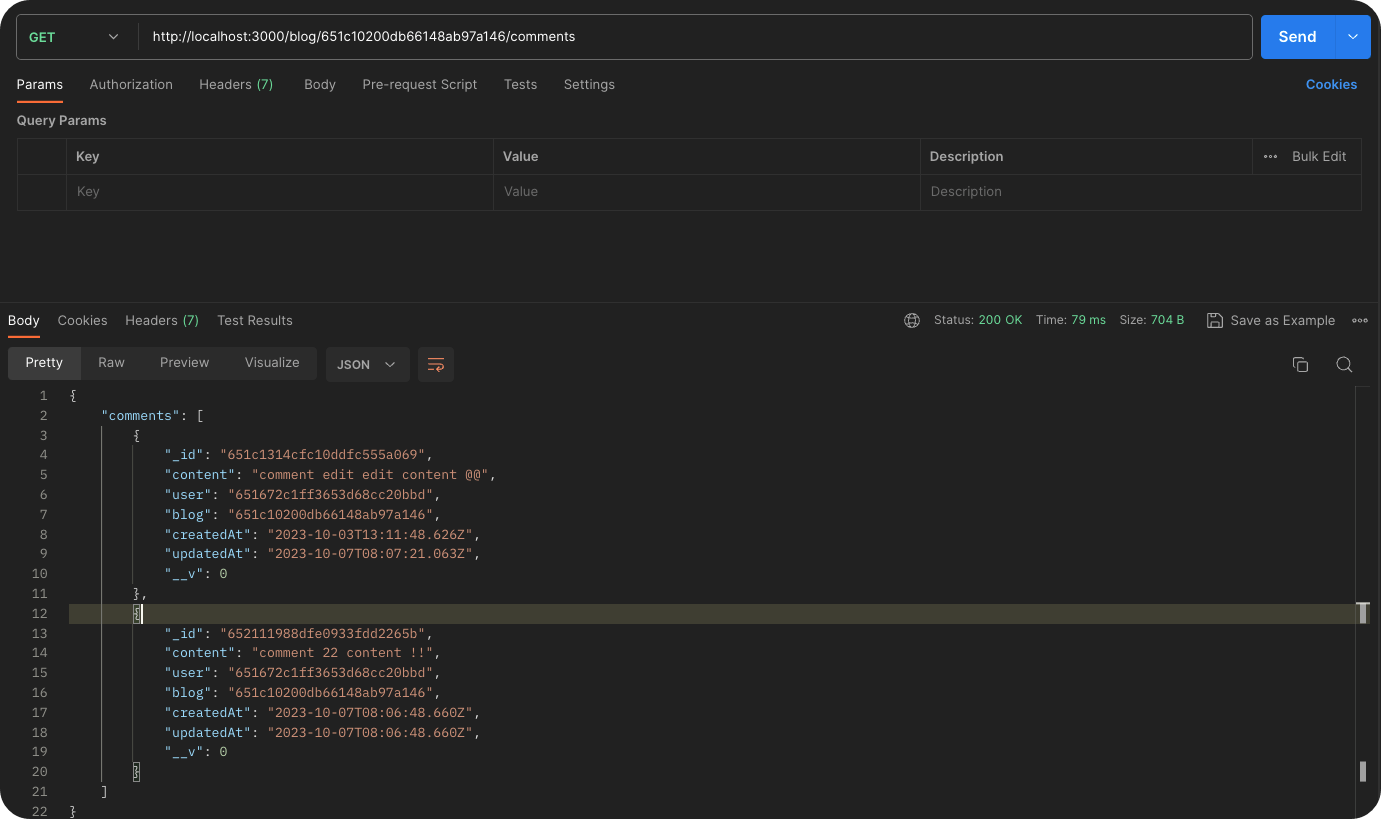
Blog id가 651c10200db66148ab97a146인 blog의 comments가 2개 존재하는 걸 확인했고 그중 하나인652111988dfe0933fdd2265b 이 녀석을 수정해 보자.
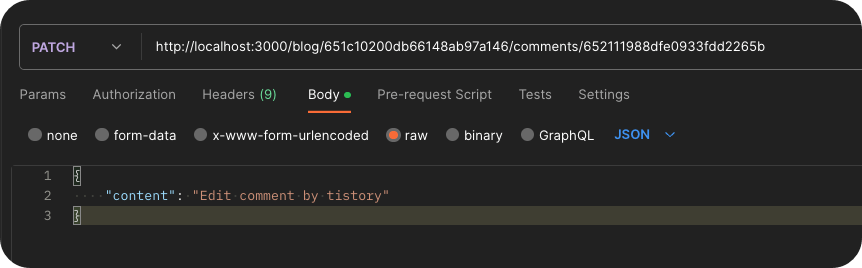
위 사진과 같이 request.body 값에 content 데이터를 추가하고 요청해 보면 다음과 같은 결과를 응답받는다.

정상적으로 코멘트가 수정되었고 우리가 원하는 코멘트만 수정된 건지 확인해 보자.

MongoDB Compass를 통해 확인한 결과 우리가 수정하고자 하는 코멘트가 잘 수정된 모습이다.
그리고 조회를 해보자. 조회를 했을 때 populate, virtual을 이용하는 것보다 더 빠른 속도로 응답하는 것을 확인할 수 있다.
마무리
이번 포스팅에서는 MongoDB를 사용할 때 원하는 데이터를 nested 하여 가져오는 방법을 알아보았다.
이는 조회(Read)할 때 비용을 줄여주는 대신 생성과 수정하는 Create/Update 부분에서 조금 더 비용이 발생한다.
이를 통해 모든 것을 다 만족시키는 코드는 존재하지 않는 것을 또 한 번 느꼈으며 언제나 trade-off가 발생할 수 있다는 것을 배웠다.
그러니 서비스의 특성과 상태를 잘 고려해서 어떻게 구조를 만들어 나갈지 검토하는 게 중요한듯하다.
'Typescript' 카테고리의 다른 글
| [Typescript/MongoDB] Part 4. MongoDB: Indexing (0) | 2023.10.09 |
|---|---|
| [Typescript/MongoDB] Part 2. MongoDB: populate, virtual (0) | 2023.10.03 |
| [Typescript/MongoDB] Part 1. Typescript with MongoDB (3) | 2023.09.30 |