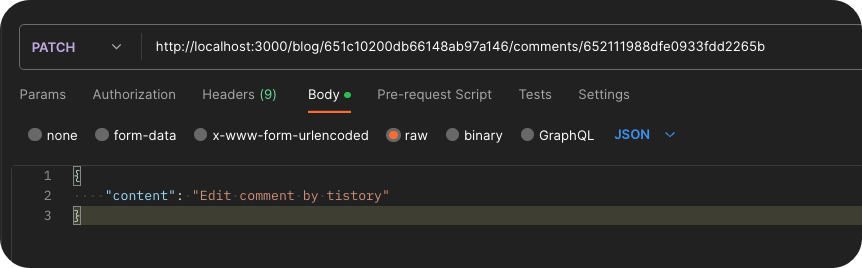
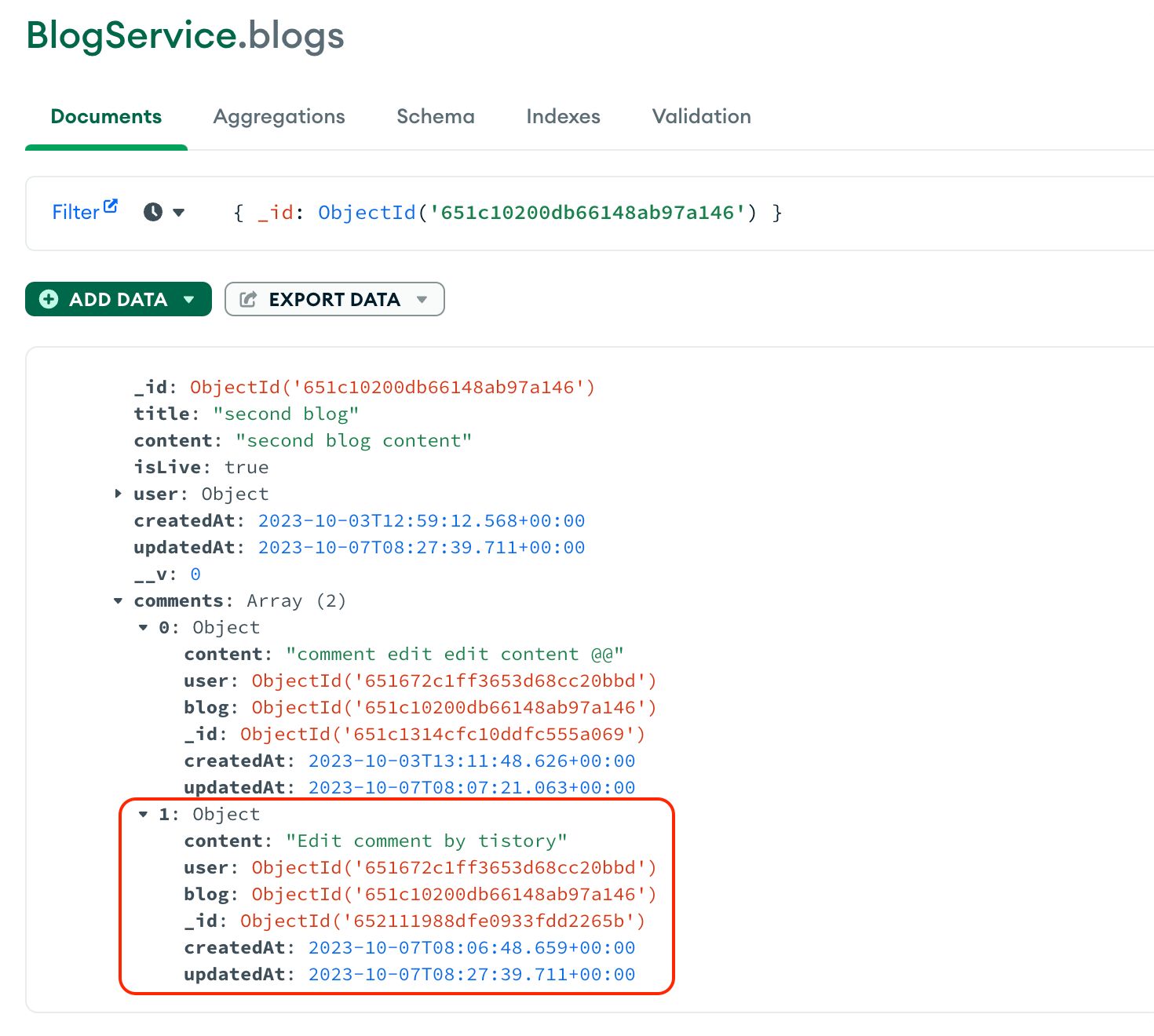
Part 3에서 조회의 응답 속도를 더 개선하기 위해 내장(Nesting)방법을 이용해서 조회 속도를 더 개선했었다.
그러니까 지금까지 배운 방법은 populate, virtual, nesting 이렇게 크게 3가지를 배워서 조회 속도를 개선해 봤는데 데이터가 정말 무수히 많아지면(몇백만개 또는 몇천만개 혹은 그 이상) 데이터를 내장시켜서 가져올 때 속도가 느려질 수 밖에 없다.
이는 내장시킨 데이터 때문이 아니라 스캔하는 방법에 더 가까운데 기본적인 데이터 스캔 방식은 처음부터 가지고 있는 데이터의 마지막까지 하나씩 가져와 데이터를 찾아내는 COLLSCAN(컬렉션 스캔) 이라는 스캔 방식을 취한다. 이게 데이터가 적을땐 거의 아무런 영향을 끼치지 않는다 (컴퓨터의 연산 속도는 정말 빠르기 때문에) 그러나 데이터가 커지면 커질수록 이 차이가 발생하는데 여기서 개선할 수 있는 방법은 IXSCAN(인덱스 스캔)을 사용하는 것이다.

위처럼 특정 Collection에서 age라는 필드에 index를 오름차순으로 걸었을 때를 가정해보자. 만약 그 Collection의 모든 document 중 age가 53인 데이터만 가져오고 싶다는 쿼리를 작성해서 날리면 인덱스 스캔은 위 그림에서 하단 인덱스의 오름차순 데이터를 가지고 데이터를 찾는다. 최초의 시작은 처음부터가 아니라 중간부터 시작해서 중간인 데이터 age:30이 원하는 53인지 판단 후 53보다 작기 때문에 왼쪽 부분은 더 이상 보지 않는다. 그럼 벌써 모든 데이터의 절반이 필터링 된 것이다. 이게 인덱싱 스캔이다. 그리고 찾은 30이 53보다 작기 때문에 우측으로 넘어가서 우측 끝과 30 사이인 53으로 포인터가 넘어간다. 53은 원하는 값이기 때문에 단 두번만에 원하는 데이터를 찾게된다. 이런 방법을 인덱스 스캔이라고 한다.
실제로 데이터가 한 10만개 정도 있을 때 컬렉션 스캔과 인덱스 스캔은 응답의 속도 차이를 보인다. 아래 예시를 보자.
COLLSCAN Vs. IXSCAN
우선 내 DB에 Users라는 컬렉션에는 데이터가 10만개정도가 있다.
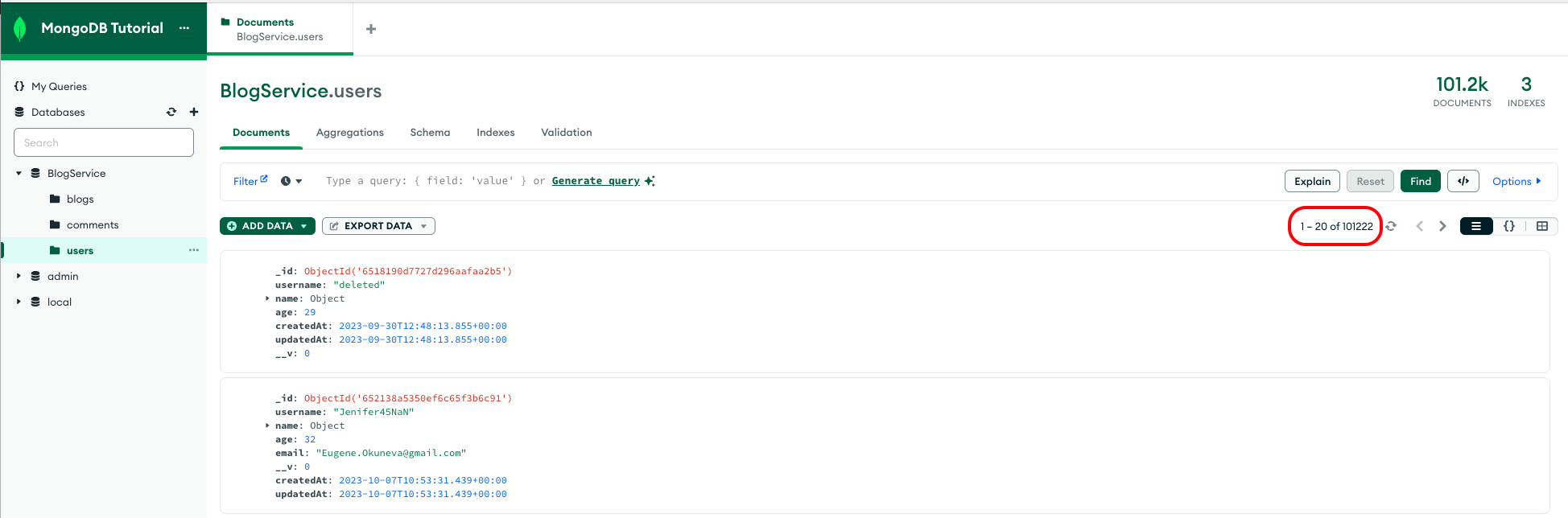
이 상태에서 최초에는 컬렉션 스캔으로 데이터를 가져와보자.
다음과 같이 필터링 조건을 age가 20보다 큰 녀석들로 설정하고, Sort를 age가 오름차순(1) Sort한다는 조건을 걸고 우측 Explain 버튼을 클릭해보자.

그러면 화면창이 하나 뜨는데 거기에는 어떤 데이터를 어떻게 가져와서 얼마나 걸렸는지 자세하게 보여준다.

사진에서 보면 우측 "211ms execution time"라고 보인다. 즉, 모든 처리를 211ms만에 실행했다는 얘기이다. 이제 인덱싱을 걸어서 데이터를 조회해보자.
상단에 보면 Indexes라는 탭이 있다.

인덱스를 새로 생성해보자.

이제 같은 조건으로 쿼리를 실행해보면 다음과 같은 결과를 도출해낸다.

우측 끝에 139ms만에 끝났다는 결과를 얻을 수 있다. 고작 10만개 정도인데도 이런 차이를 보이면 데이터가 많아지면 많아질수록 그 효율성은 더 커질것이다. 이런식으로 인덱싱을 사용해서도 데이터 조회에 응답 속도를 줄여줄 수 있다.
복합 인덱스
이번에는 단일 인덱스가 아니라 복합(여러개) 인덱스를 걸어서 조회해보자.
위에서는 age 하나만 가지고 인덱스를 만들어 스캔했다면 이번엔 username과 같이 인덱스를 걸어서 스캔했을 때 어떤 영향을 끼치는지 알아보자.
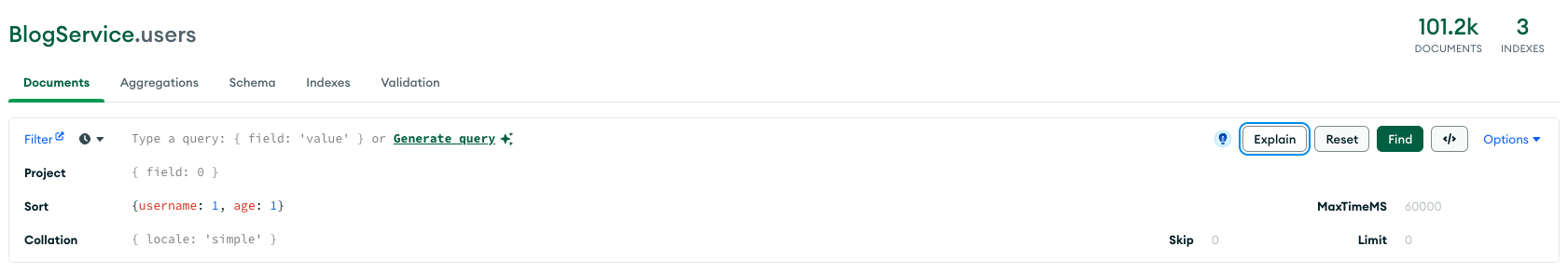
우선, 인덱스를 만들지 않고 username을 오름차순, age를 오름차순으로 정렬하는 쿼리를 실행했을 때 응답 속도를 확인해보자.
위처럼 쿼리를 날려보면 아래와 같은 결과를 얻는다.
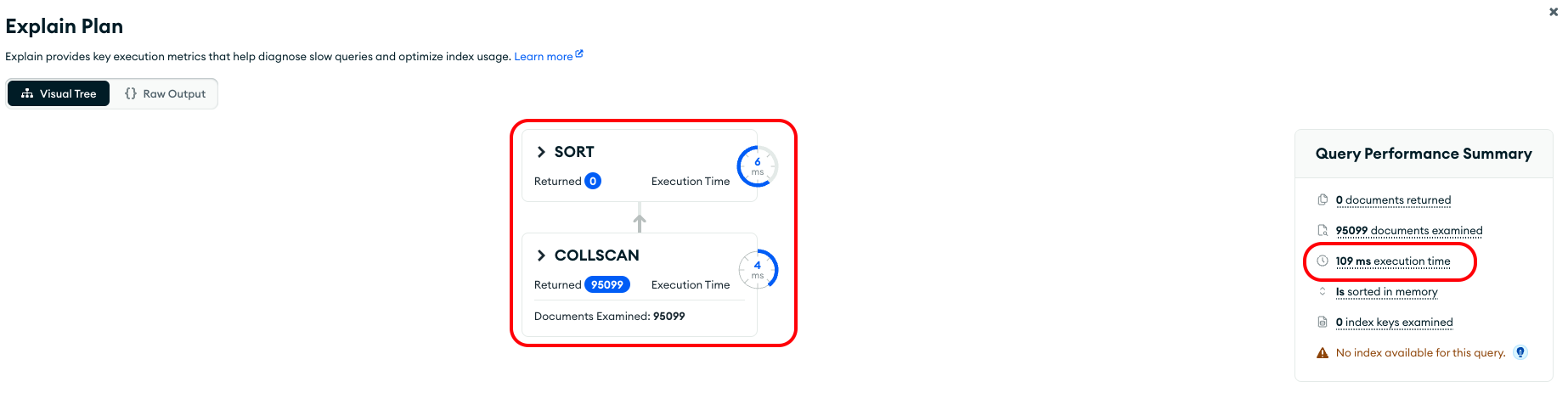
컬렉션 스캔으로 가져온 데이터를 솔팅하는데 총 109ms의 처리 시간이 발생했다. 여기서 인덱스를 걸어보자.
username 오름차순, age 오름차순에 대한 인덱스를 만들어보자.

이렇게 인덱스를 만들고 다시 조회해보자.

인덱스를 만들어 조회해보면 IXSCAN이라고 나온다. 제대로 인덱스를 이용해 스캔하고 있다.
그럼 반대로 age를 먼저 입력해보자. { age: 1, username: 1 }
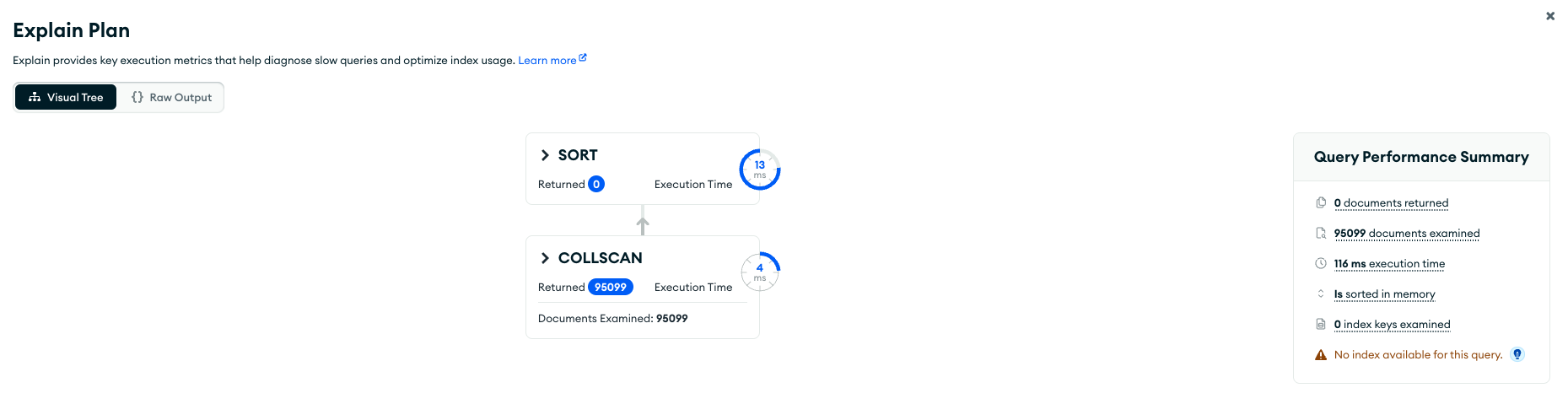
신기하게 이번에는 컬렉션 스캔을 수행했고. 우측에 이용가능한 인덱스가 없다고 표시된다. 왜 그럴까 ?
복합 인덱스는 인덱스를 만들 때 필드의 순서가 영향이 있게 된다. 따라서 인덱스를 만들 때 필드의 순서가 중요하다.
이번에는 하나는 오름차순 하나는 내림차순으로 만들어보자.
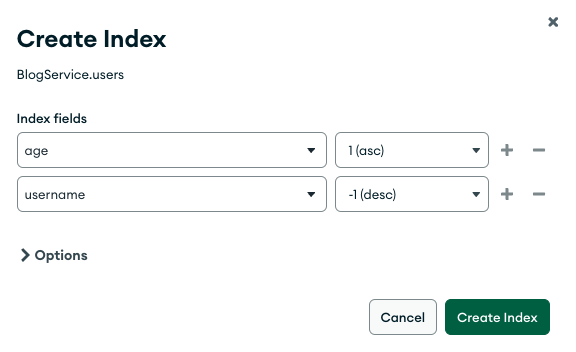
이렇게 age를 오름차순 username을 내림차순으로 설정하고 인덱스를 만들었고 이와 같은 조회를 해보자.

당연히 IXSCAN을 한다. 합리적이다. 이번에는 반대로 age를 내림차순 username을 오름차순으로 조회해보자.
이것또한 인덱스 스캔을 했다. 왜 그럴까? 위에서는 필드의 순서가 중요하다고 했는데 이런 인덱스는 만든적이 없지만 인덱스 스캔을 했다.

인덱스는 대칭 구조를 갖는다고 생각하면 된다. 만약 인덱스를 { age: 1, username: -1 }로 만들었을 때 여기에 -1을 곱해보면 { age: -1, username: 1 }이 되는데 이 또한 인덱스 스캔으로 동작한다. 그래서 대칭 구조로도 인덱스를 사용할 수 있다고 알아둬야겠다.
그리고 위 결과에서도 알 수 있듯 인덱스 스캔이 더 오래걸리기도 한다. 이는 인덱스를 사용할 때 인덱스가 걸린 필드의 분포도가 영향을 끼치는데 인덱스를 만든 필드의 분포도가 커지면 커질수록 인덱스 스캔은 속도가 오래걸린다. 그래서 인덱스를 남발하는 건 절대 좋은게 아니다. 또한 인덱스를 만들면 인덱스를 생성하는데 들어가는 비용이 꽤나 크기 때문에 메모리를 차지하는데 이 또한 무시할 수 없다. 아래 그림을 보면

101200개의 Documents의 토탈 사이즈보다, Index 5개의 토탈 사이즈가 더 크다. 이 정도로 인덱스는 크기를 많이 차지하는데 크기만 차지하는 문제를 가지고 있는것이 아니고 이렇게 되면 인덱스를 통해 READ하는 속도는 낮출 수 있을지 몰라도 CREATE하는 속도가 올라간다. 데이터를 만들 때 역시 인덱스를 걸어주기 때문이고 인덱스가 많아지면 많아질수록 구조는 복잡해지기 때문이다.
그래서 인덱스를 남발하는건 절대 좋은게 아니라고 할 수 있다. 상황과 처한 상태에 맞게 적절히 사용해야한다.
참고로 텍스트를 인덱스로 사용할 수 있다. 예를 들어, 블로그의 title 같은 텍스트를 인덱스를 걸고 싶으면 아래처럼 하면 된다.
const blogSchema = new Schema<IBlog>(
{
title: { type: String, required: true },
content: { type: String, required: true },
isLive: { type: Boolean, required: true, default: false },
user: {
_id: { type: Types.ObjectId, required: true, ref: 'user' },
username: { type: String, required: true },
name: {
first: { type: String, required: true },
last: { type: String, required: true },
},
},
comments: [commentSchema],
},
{ timestamps: true }
);
blogSchema.index({ title: 'text' });이렇게 index()를 사용해서 추가해주면 되는데, 만약 blog의 title뿐 아니라 content도 인덱스로 만들고 싶다면 이처럼 동일한 방법으로는 할 수 없다. 왜냐하면 text 기반의 인덱스는 하나만 만들 수 있기 때문이다. 이럴 땐 복합 인덱스를 사용해야한다.
const blogSchema = new Schema<IBlog>(
{
title: { type: String, required: true },
content: { type: String, required: true },
isLive: { type: Boolean, required: true, default: false },
user: {
_id: { type: Types.ObjectId, required: true, ref: 'user' },
username: { type: String, required: true },
name: {
first: { type: String, required: true },
last: { type: String, required: true },
},
},
comments: [commentSchema],
},
{ timestamps: true }
);
blogSchema.index({ title: 'text', content: 'text' });저렇게 title과 content 모두 text로 search할 때 인덱스를 만들어내고 싶으면 복합 인덱스를 사용하면 된다.
마무리
컬렉션 스캔과 인덱스 스캔을 비교해 보았는데 무조건적으로 인덱스 스캔이 좋은것은 아니다. 만약 데이터가 적은 경우, 오히려 인덱스 스캔이 컬렉션 스캔보다 오래걸릴 수 있다. 위에서 언급했던 것처럼 컴퓨터의 연산 속도는 굉장히 빠르기 때문에 백개, 천개정도는 네트워크 속도를 제외하면 거의 차이가 없는데 여기서 인덱싱을 사용하면 오히려 불필요한 과정을 거칠 수 있어진다. 즉, 항상 그렇듯 상황과 상태를 고려해서 구조를 깔아야 한다는 것을 또 한번 느끼고 마무리.
'Typescript' 카테고리의 다른 글
| [Typescript/MongoDB] Part 3. MongoDB: Nesting (0) | 2023.10.05 |
|---|---|
| [Typescript/MongoDB] Part 2. MongoDB: populate, virtual (0) | 2023.10.03 |
| [Typescript/MongoDB] Part 1. Typescript with MongoDB (3) | 2023.09.30 |