참고자료
실전! 스프링 데이터 JPA 강의 | 김영한 - 인프런
김영한 | 스프링 데이터 JPA는 기존의 한계를 넘어 마치 마법처럼 리포지토리에 구현 클래스 없이 인터페이스만으로 개발을 완료할 수 있습니다. 그리고 반복 개발해온 기본 CRUD 기능도 모두 제
www.inflearn.com
스프링 데이터 JPA 구현체 분석
그래서 스프링 데이터 JPA 공통 인터페이스의 구현체는 어떻게 생겨먹었을까? 그 부분을 파헤쳐보자!
스프링 데이터 JPA가 제공하는 공통 인터페이스인 JpaRepository를 찾아가보면 이렇게 되어 있다.
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.springframework.data.jpa.repository;
import java.util.List;
import org.springframework.data.domain.Example;
import org.springframework.data.domain.Sort;
import org.springframework.data.repository.ListCrudRepository;
import org.springframework.data.repository.ListPagingAndSortingRepository;
import org.springframework.data.repository.NoRepositoryBean;
import org.springframework.data.repository.query.QueryByExampleExecutor;
@NoRepositoryBean
public interface JpaRepository<T, ID> extends ListCrudRepository<T, ID>, ListPagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
void flush();
<S extends T> S saveAndFlush(S entity);
<S extends T> List<S> saveAllAndFlush(Iterable<S> entities);
/** @deprecated */
@Deprecated
default void deleteInBatch(Iterable<T> entities) {
this.deleteAllInBatch(entities);
}
void deleteAllInBatch(Iterable<T> entities);
void deleteAllByIdInBatch(Iterable<ID> ids);
void deleteAllInBatch();
/** @deprecated */
@Deprecated
T getOne(ID id);
/** @deprecated */
@Deprecated
T getById(ID id);
T getReferenceById(ID id);
<S extends T> List<S> findAll(Example<S> example);
<S extends T> List<S> findAll(Example<S> example, Sort sort);
}- 이 녀석은 그냥 인터페이스고 실제 이 인터페이스를 구현한 구현체가 있다. 물론, 스프링 데이터 JPA가 구현체를 미리 만들어서 제공해준다.
- 그 구현체의 이름은 SimpleJpaRepository이다.
package org.springframework.data.jpa.repository.support;
import ...
@Repository
@Transactional(
readOnly = true
)
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {...}- 클래스가 굉장히 크기 때문에 여기다 그 내용을 다 적을 순 없고 직접 들어가서 확인해 보길 바란다.
- 확인해보면 정말 별 게 없다. 우리가 다 이전에 순수 JPA로 해봤던 코드들이 그대로 여기에도 적용되어 있다.
- 이런것을 보면, 잘 만든 라이브러리의 주인이 우리가 될 수도 있다는 가슴 설레는 기분이 든다.
- 그리고 이렇게 스프링 데이터 JPA가 만들어주는 구현체에 이미 @Repository, @Transactional(readOnly = true)가 들어있기 때문에 JpaRepository를 상속받는 인터페이스를 우리가 만들때 @Repository를 굳이 붙이지 않아도 됐던 것이고, 서비스에 @Transactional을 걸지 않아도 스프링 데이터 JPA를 사용해서 공통 인터페이스를 사용하면 쓰기 작업도 원활히 됐던 것이다. 물론 이 내용은 모두 스프링 데이터 JPA를 사용한다는 가정하에 말이다.
예시로 delete()를 보면 이렇게 생겼다.
@Transactional
public void delete(T entity) {
Assert.notNull(entity, "Entity must not be null");
if (!this.entityInformation.isNew(entity)) {
if (this.entityManager.contains(entity)) {
this.entityManager.remove(entity);
} else {
Class<?> type = ProxyUtils.getUserClass(entity);
T existing = (T)this.entityManager.find(type, this.entityInformation.getId(entity));
if (existing != null) {
this.entityManager.remove(this.entityManager.merge(entity));
}
}
}
}- 뭐 딱히 다른게 없다! 결국은 EntityManager.remove() 호출하는 것이다.
자자, 그리고 변경 감지를 사용해야 한다는 말을 하면서 데이터를 저장하는게 아니라 변경 시에는 save()를 호출하는 게 아니라고 여러번 얘기했는데 이 save() 코드도 보자. 진짜 뭐가 없다.
@Transactional
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null");
if (this.entityInformation.isNew(entity)) {
this.entityManager.persist(entity);
return entity;
} else {
return (S)this.entityManager.merge(entity);
}
}- 자, 엔티티가 새로운 엔티티라면 persist()를 호출하고 그렇지 않다면(데이터를 변경하는 거라면) merge()를 호출하고 있다. 이렇기에 데이터를 변경 시 save()를 호출하는 게 아니라 변경감지를 사용해야 한다고 말하는 것이다. 변경감지를 사용해야 하는 이유는 크게 3가지가 있다.
- 어차피 merge()도 결국엔 영속성 컨텍스트에 올려서 데이터를 변경한 다음 변경감지로 데이터를 바꾼다.
- 위 1번에 따르면, merge()를 호출하면 영속성 컨텍스트에 올린다고 했는데 그럼 데이터베이스에서 해당 데이터를 조회하는 과정이 일어나는 것 아닌가? 맞다. 데이터베이스에 이 변경하려는 데이터의 레코드가 있는지 확인하기 위해 조회 쿼리가 나간다.
- 조회한 데이터에 전달한 변경할 데이터를 담은 엔티티의 모든 값으로 덮어씌운다. null이 있었다면? null로 덮어씌운다.
데이터를 변경할 때 save() 호출하지 말자. 절대!!
새로운 엔티티를 구별하는 방법
바로 위에서 본 save() 메서드에서, 새로운 엔티티라면 persist()를 호출하고, 그게 아니라면 (즉, 데이터베이스에 이미 저장된 데이터라면) merge()를 호출하는 것을 보았다. 그런데 말이다. 새로운 엔티티인지 어떻게 판단할까?
이 내용이 꽤나 중요하기 때문에 집중해야 한다. 우선 결론부터 말하면 이렇다.
새로운 엔티티를 판단하는 기본 전략
- 식별자(PK)가 객체(Long과 같은)타입일 때 null이라면 새로운 엔티티라고 판단
- 식별자(PK)가 자바 기본 타입(long)일 때 0이라면 새로운 엔티티라고 판단
이게 무슨말인지 코드를 통해서 조금 더 자세히 알아보자.
Item
package cwchoiit.datajpa.entity;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.Id;
@Entity
public class Item {
@Id
@GeneratedValue
private Long id;
}- 아주 간단한 엔티티 하나를 만든다. 식별자 필드 딱 하나만 있으면 된다.
- 주의 깊게 볼 부분은 @GeneratedValue와 Long 타입이다.
- @GeneratedValue는 사용하는 데이터베이스에게 PK 생성을 위임하는 방식인데 이렇게 하면 EntityManager.persist()를 호출했을 때는 아직 데이터베이스에 저장하기 전이기 때문에 이 Id값이 없다. 즉 null이다.
그리고, 테스트 코드를 작성해서 save()를 호출해보자!
ItemTest
package cwchoiit.datajpa.entity;
import cwchoiit.datajpa.repository.springdatajpa.ItemRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class ItemTest {
@Autowired
private ItemRepository itemRepository;
@Test
void isNew() {
itemRepository.save(new Item());
}
}- 이렇게 했을 때 아까 위에서 본 SimpleJpaRepository의 save()는 어떻게 동작할까?
- 한번 디버깅을 해보자.
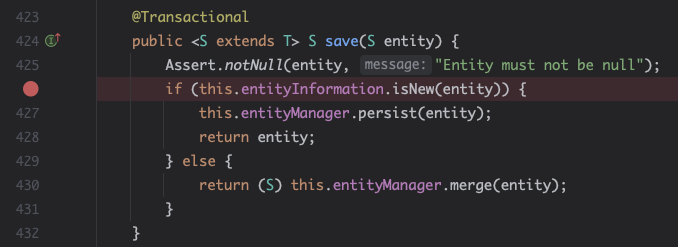
- 이 isNew(entity)는 어떤 판단을 할까?

- 우선 브레이크 포인트에 걸렸을 때는 다음과 같이 당연히 id값은 null이다. 아직 데이터베이스에 저장하기 전이니까 말이다.
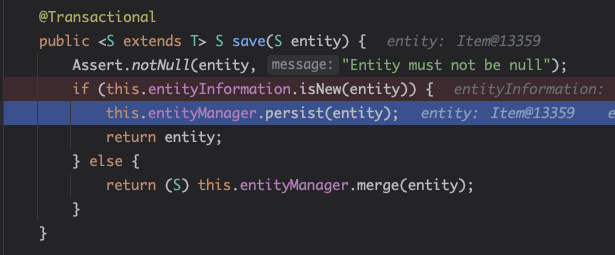
- 그래서 persist()를 호출하는 코드를 그대로 수행하게 된다.
- 이처럼, 식별자가 객체(Long)일 때는 null인 경우 새로운 엔티티라고 판단한다.
- 그러면 자바 기본 타입인 long같은 경우 값을 세팅 안하면 0이 기본값이라서 0일때 새로운 엔티티라고 판단한다고 했던것이다.
아니, 근데 이건 너무 쉬운데 왜 이 내용이 중요하다고 했을까? 지금의 경우는 식별자를 @GeneratedValue로 설정했을 때 이야기다. 만약, 이 방식을 사용하지 않고 개발자가 직접 아이디를 세팅한다고 한다면 어떻게 될까? 그러니까 엔티티를 다음과 같이 작성하는 것이다.
Item
package cwchoiit.datajpa.entity;
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import lombok.AccessLevel;
import lombok.AllArgsConstructor;
import lombok.NoArgsConstructor;
@Entity
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Item {
@Id
private Long id;
}- @Id만 사용해서 직접 식별자 값을 할당하는 경우에는 당연히 이미 식별자 값이 있는 상태로 save()를 호출한다. 아래 코드처럼 말이다.
@Test
void isNew() {
itemRepository.save(new Item(1L));
}- 와.. 이러면 객체값인데 null이 아니게 된다. 어떻게 될까? 디버깅 해서 다시 한번 돌려보자.
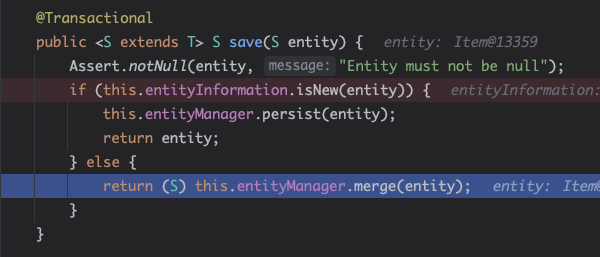
- 디버깅해서 직접 확인해보면 알겠지만, merge(entity)로 가버린다.
- merge()를 호출한다는 건 일단 무조건 데이터베이스에 해당 값이 있다고 간주한다. 그렇기에 merge()는 무조건 이 값을 가져오기 위해 데이터베이스에 조회를 하게 된다. 실제로 그런지는 쿼리 나가는 것을 보면 알 수 있다.
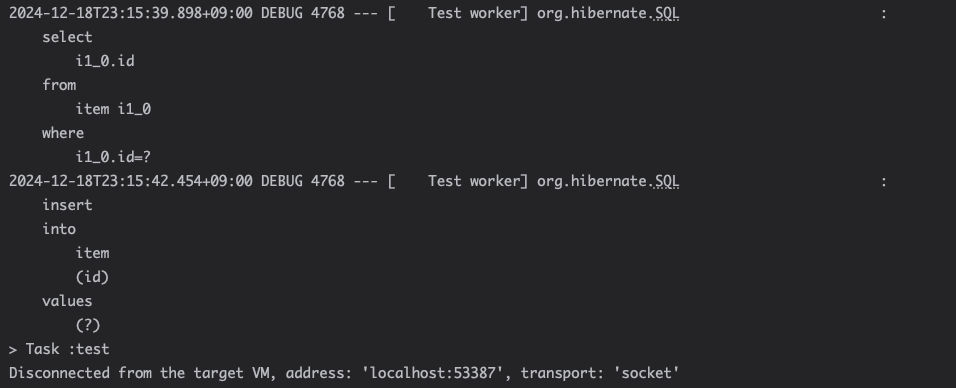
- SELECT 쿼리가 보이는가? SELECT를 했는데 해당 값이 없으니까, "아 뭐야? 없잖아?" 하고 새로운 엔티티라고 판단을 여기서나마 해서 INSERT를 하게 된다.
- 이게 어떤 문제냐? 당연히 너무나 비효율적이다. 이러면 이제 모든 새 엔티티를 만들때마다 이 조회 쿼리가 무의미하게 나가는데 이 조회라는 건 꽤나 성능에 영향을 끼치는 작업이다.
- 이건 논외지만 변경을 할때 무조건 변경 감지를 사용하자. 보다시피 merge()는 해당 데이터를 데이터베이스에서 조회하는 작업을 무조건 거치게 된다.
다시 주제로 돌아와서, 이 경우에 그러면 어떻게 하면 될까? Persistable 인터페이스를 구현해서 판단 로직을 변경할 수 있는 기능을 제공한다.
Persistable 구현
package cwchoiit.datajpa.entity;
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import lombok.AccessLevel;
import lombok.AllArgsConstructor;
import lombok.NoArgsConstructor;
import org.springframework.data.domain.Persistable;
@Entity
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Item implements Persistable<Long> {
@Id
private Long id;
@Override
public Long getId() {
return id;
}
@Override
public boolean isNew() {
return false;
}
}- Persistable<PK의 타입>을 구현하면, 다음 두가지 메서드를 구현해야 한다. getId(), isNew().
- 여기서 isNew를 직접 구현해서 새로운 엔티티에 대한 판단 로직을 작성하면 되는데 어떻게 하면 좋을까?
- 아래와 같은 기가막힌 방법이 있다.
package cwchoiit.datajpa.entity;
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import lombok.AccessLevel;
import lombok.AllArgsConstructor;
import lombok.NoArgsConstructor;
import org.springframework.data.domain.Persistable;
@Entity
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Item extends BaseEntity implements Persistable<Long>{
@Id
private Long id;
@Override
public Long getId() {
return id;
}
@Override
public boolean isNew() {
return getCreatedDate() == null;
}
}- Auditing에 대해 공부할 때 BaseEntity를 만들고 그 안에 createdDate 필드를 직접 만들어 넣는게 아니라 스프링 데이터 JPA의 Auditing 기능을 사용해서 자동으로 세팅하게 설정했다.
- 결국 새로운 엔티티인 경우엔 이 createdDate값이 null이고 새로운 엔티티가 아니라면 이 값은 무조건 null이 아니게 된다.
- 이 필드의 값을 사용해서 @GeneratedValue를 사용하지 않았을 때도 정상적으로 새 엔티티를 판단해서 merge()를 호출하는 무식한 짓을 하지 않아도 된다.
- 테스트 코드로 이제 다시 테스트 해보자.
- 이제는 persist(entity)를 호출하는 라인으로 넘어가는 것을 볼 수 있다.
'Spring Data JPA' 카테고리의 다른 글
| Spring Data JPA (2) (0) | 2024.12.12 |
|---|---|
| Spring Data JPA (1) (0) | 2024.12.12 |