728x90
반응형
SMALL
Broker에 장애가 발생하면 어떻게 될까? 장애가 발생한 Broker의 Partition들은 모두 사용할 수 없게 되는 문제가 발생할 것이다.

계속 하기 전에 다시 한번 복습해보자면,
- Producer가 Write하는 LOG-END-OFFSET과 Consumer Group의 Consumer가 Read하고 처리한 후에 Commit한 CURRENT-OFFSET과의 차이(Consumer Lag)가 발생할 수 있다고 했다.
- 이 상태에서 장애가 나면?
다른 Broker에서 Partition을 새로 만들 수 있으면 장애는 해결될까? 다음과 같이 말이다.
- 고장난 Broker에 있는 파티션들을 다른 멀쩡한 Broker에 새로 만들었다. 해결될 것 같지만 이러한 고민거리가 남는다.
- 기존 메시지는 버릴 것인가? 기존 Offset 정보들을 버릴 것인가?
Replication
위와 같은 문제를 해결하기 위해, Partition을 복제(Replication)하여 다른 Broker상에서 복제물(Replicas)을 만들어서 장애를 미리 대비한다.
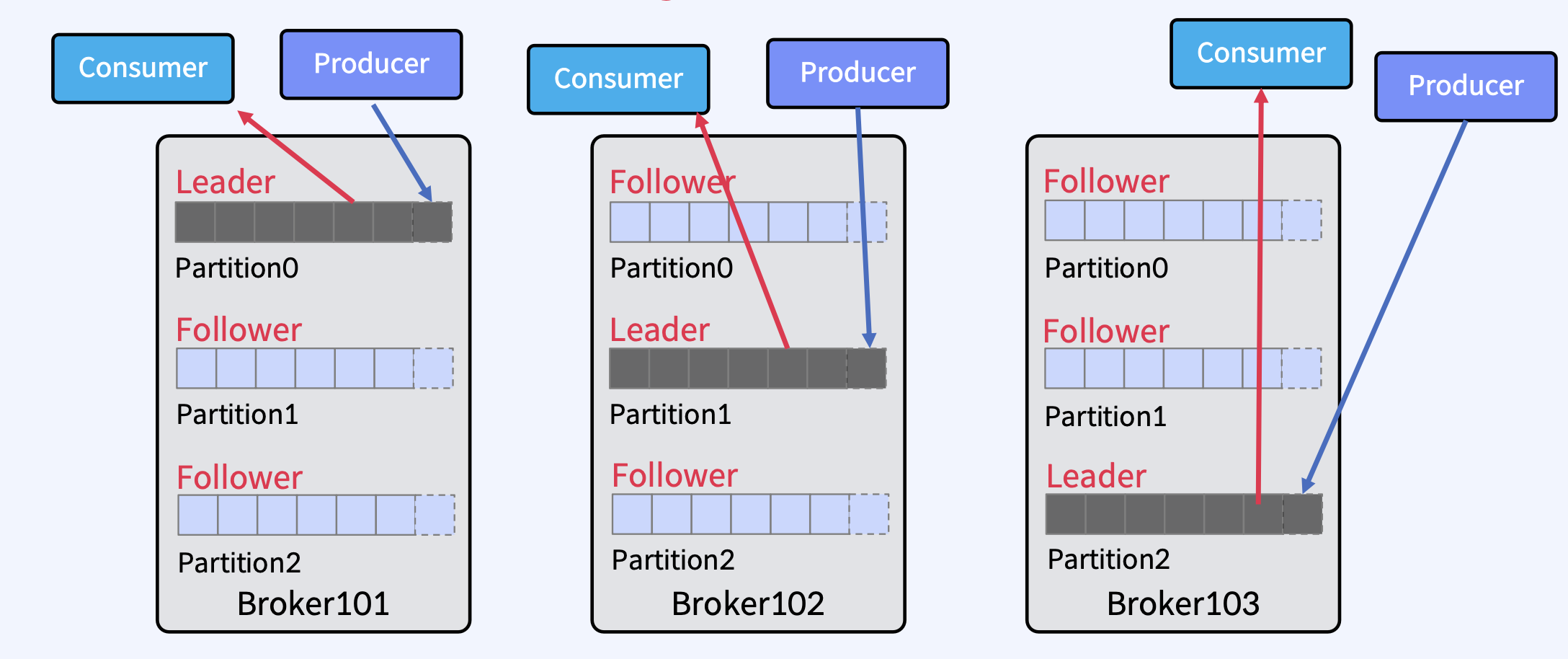
Replicas - Leader Partition, Follower Partition
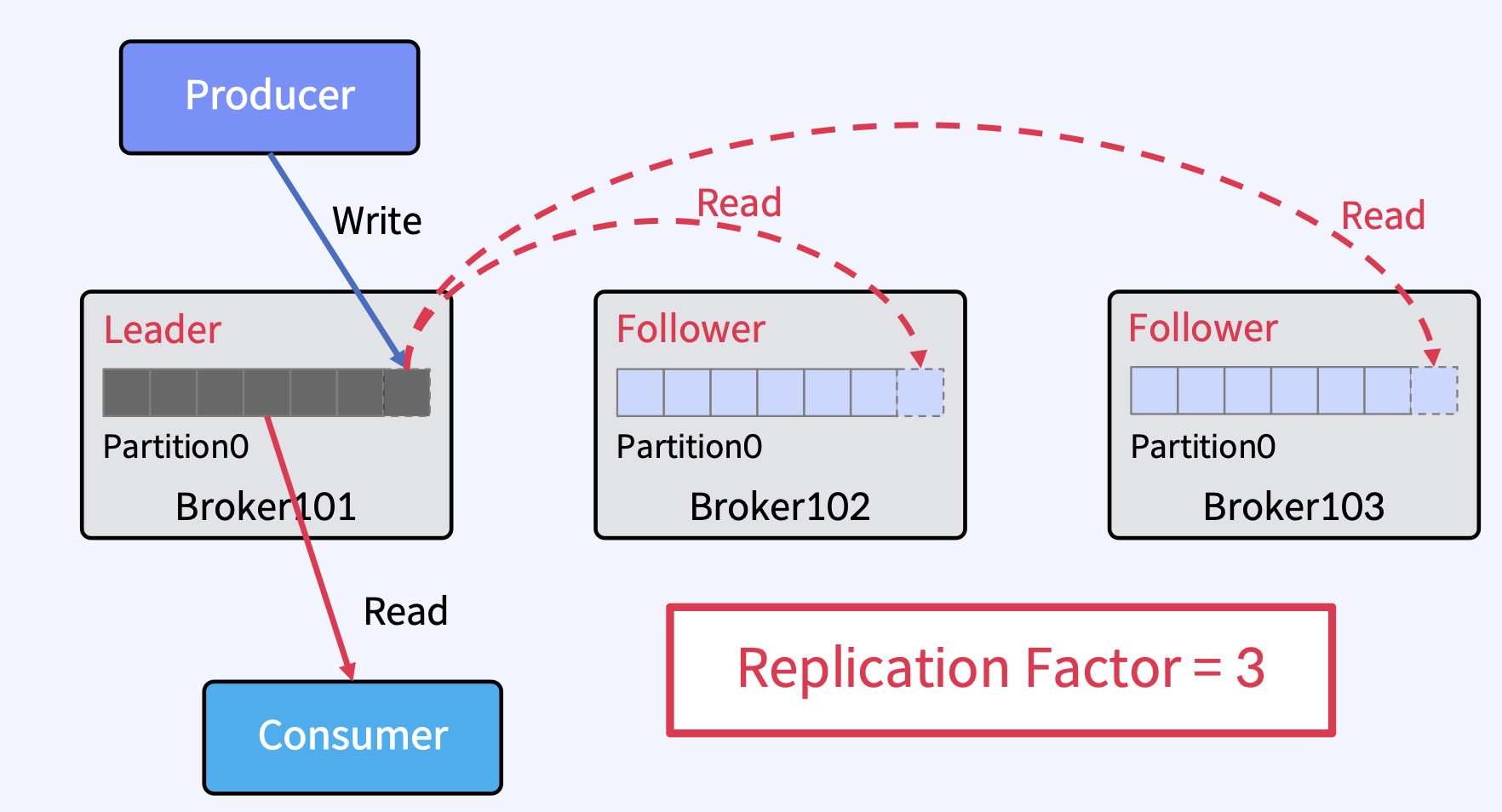
- 위 그림처럼, Leader 1개, Follower 2개로 총 Replicas는 3개가 있다.
- Producer는 Leader에만 Write하고, Consumer는 Leader로부터만 Read한다.
- Follower는 Broker 장애시 안정성을 제공하기 위해서만 존재한다.
- Follower는 Leader의 Commit Log에서 데이터를 가져오기 요청(Fetch Request)으로 복제한다.
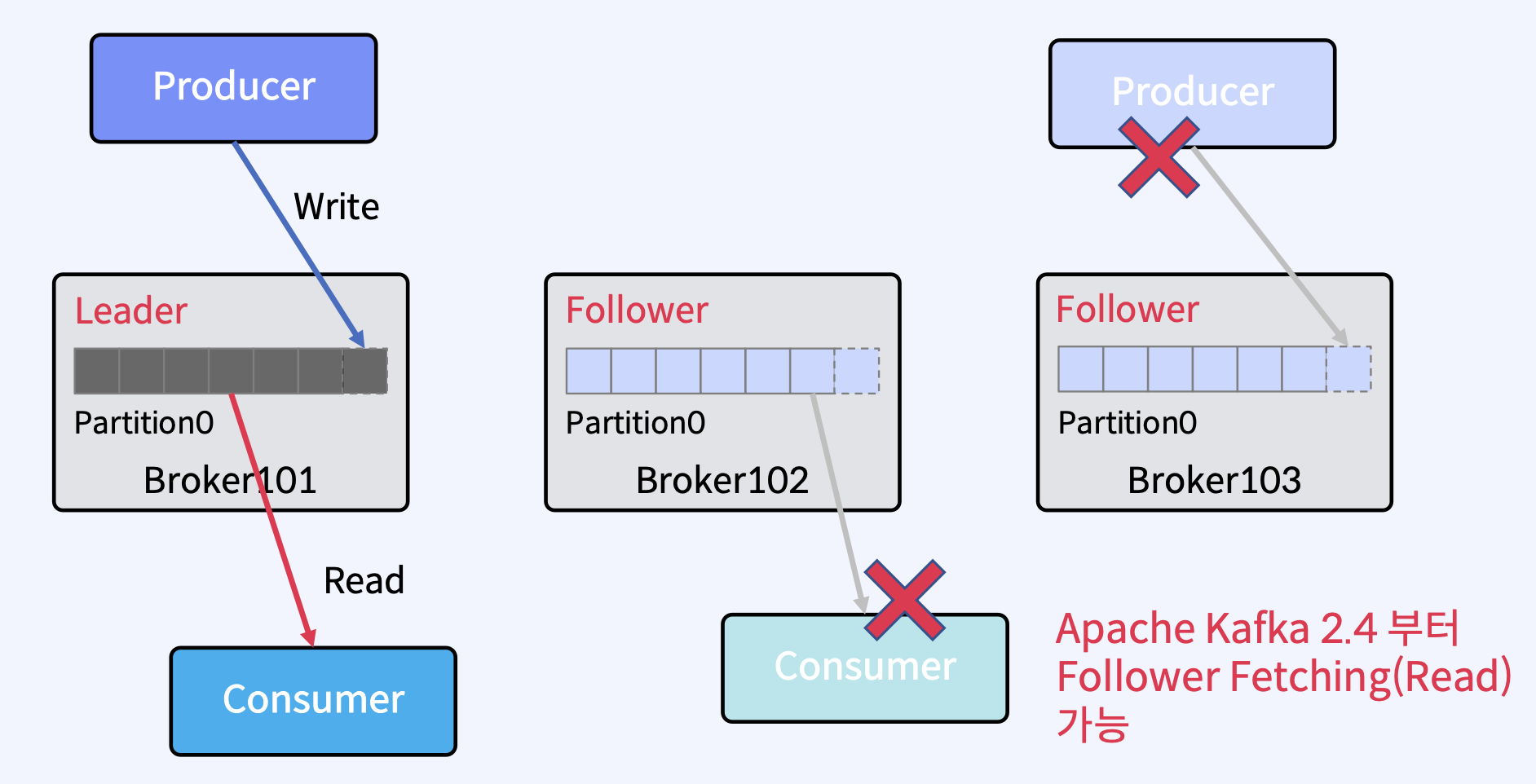
- 물론, 2.4부터 Follower에도 Consumer가 Read할 수 있는 기능이 추가됐지만 기본적으로는 Leader에서만 Read한다.
Leader에 장애가 발생하면?
Kafka 클러스터는 Follower 중에서 새로운 Leader를 선출한다. Clients(Producer/Consumer)는 자동으로 새 Leader로 전환하여 Write/Read를 한다.
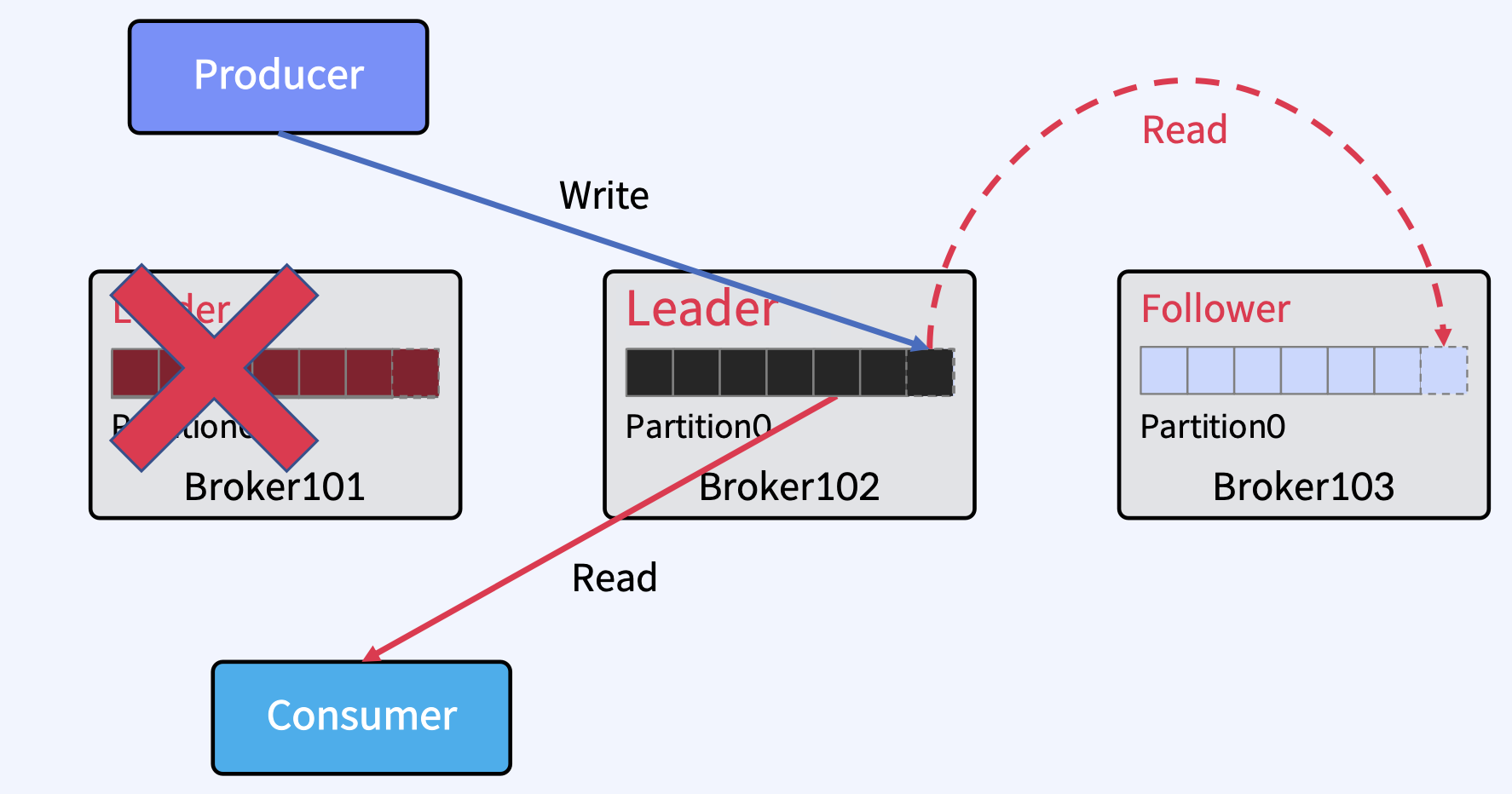
Partition Leader에 대한 자동 분산
하나의 Broker에만 Partition의 Leader들이 몰려 있다면? 여러가지 문제가 발생한다.
- 특정 Broker에만 Clients(Producer/Consumer)로 인해 부하 집중
- 해당 Broker가 고장나면 모든 Partition에 대해서 Leader를 다 재선출
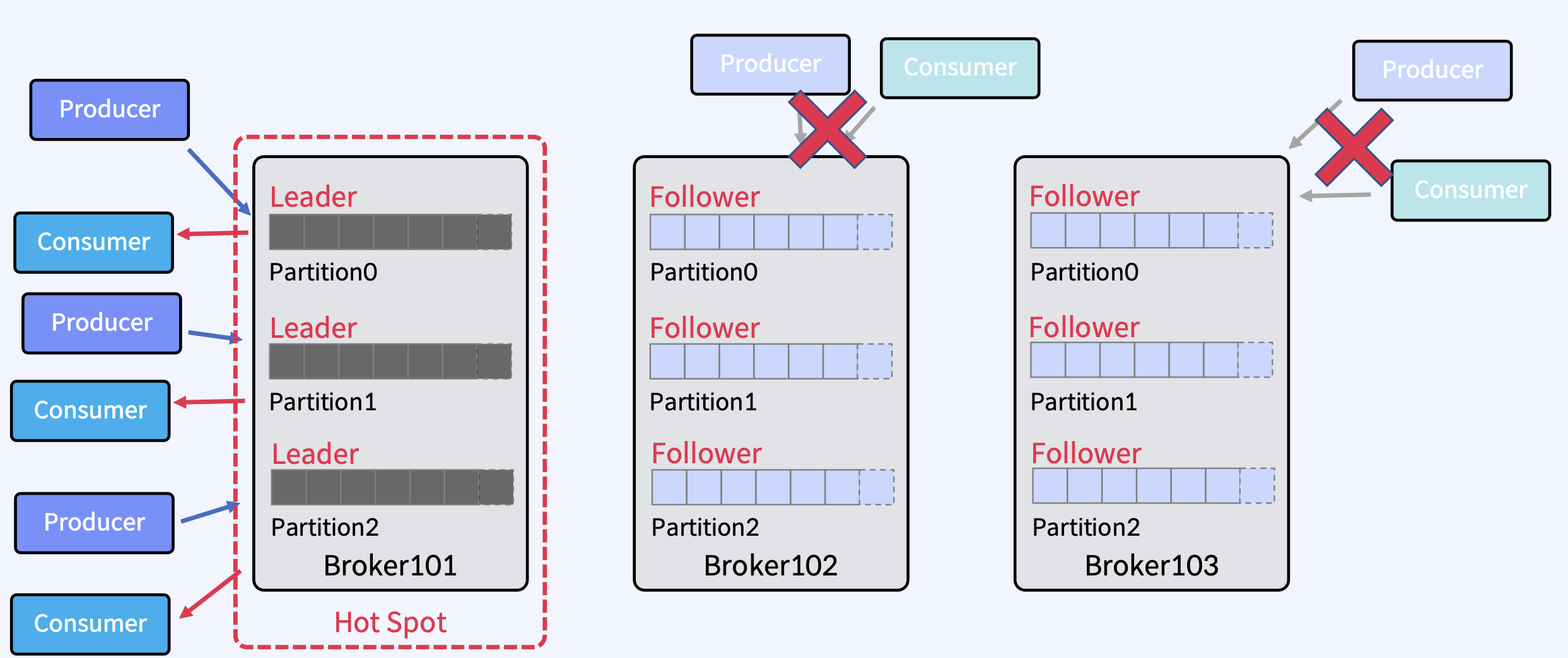
- 이러한 문제가 있기 때문에 기본적으로 Leader를 골고루 분산하는 옵션이 켜져있다.
- auto.leader.rebalance.enable (기본값 enable)
- leader.imbalance.check.interval.seconds (기본값 300 sec)
- leader.imbalance.per.broker.percentage (기본값 10)
- 그래서 이와 같은 골고루 Leader를 분산하여 Broker에 저장된다.
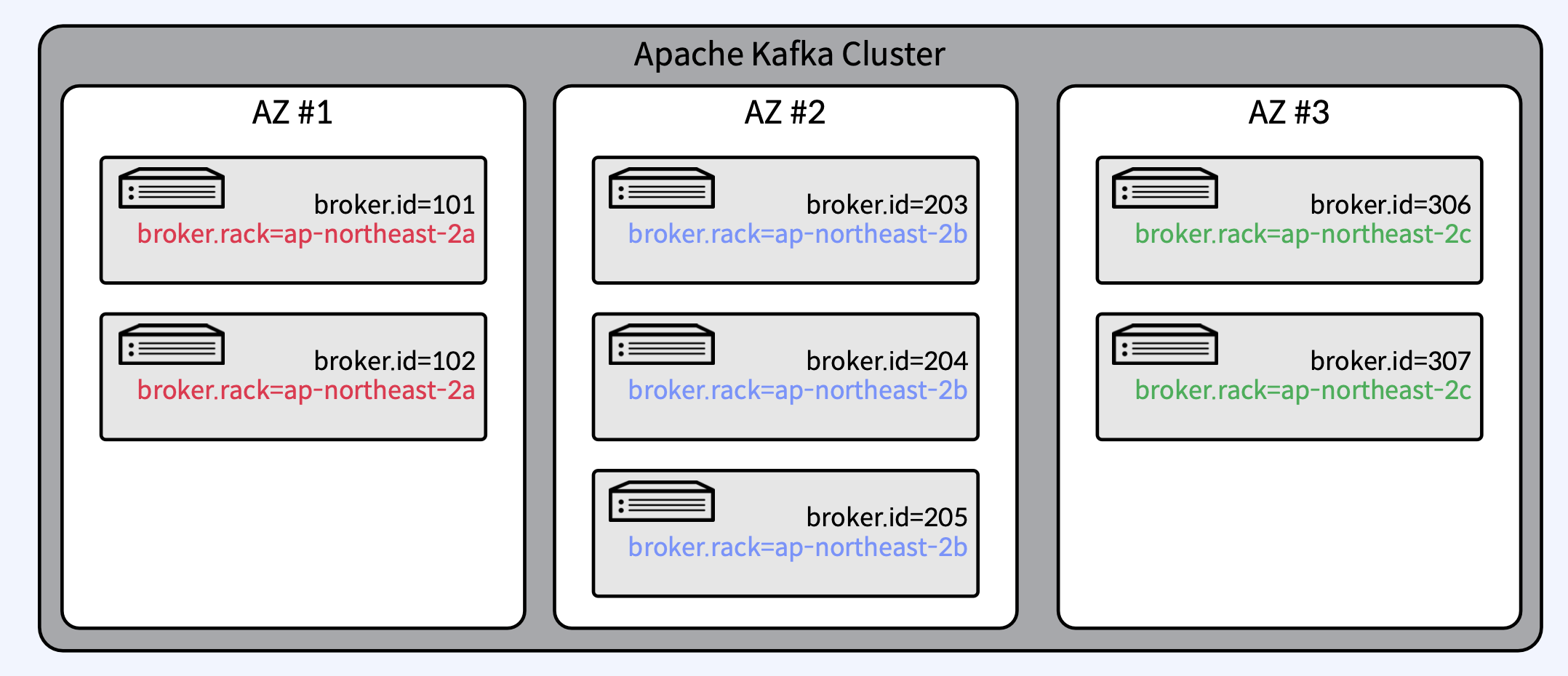
Rack Awareness
- 동일한 Rack 혹은 Available Zone 상의 Broker들에 동일한 "rack name" 지정
- 복제본 (Replica-Leader/Follower)은 최대한 Rack 간에 균형을 유지하여 Rack 장애 대비
- Topic 생성 시 또는 Auto Data Balancer/Self Balancing Cluster 동작 때만 실행
In-Sync Replicas (ISR)
Leader 장애시 Leader를 선출하는데 사용된다. In-Sync Replicas(ISR)는 High Water Mark라고 하는 지점까지 동일한 Replicas(Leader와 Follower 모두)의 목록이다. Leader에 장애가 발생하면 ISR중에서 새 Leader를 선출한다.

- 보면, replica.lag.max.messages=4 라는 옵션으로 설정되면 4개 이상으로 메시지(데이터)가 차이가 나는 Replica는 OSR(Out-of-Sync Follower)이라고 간주한다.
- 그리고, 그 범위 안에 들어오는 Replica는 ISR이라고 간주한다. 보면 Broker102에 있는 Follower는 2개밖에 차이가 나지 않기 때문에 ISR로 간주된다.
- 저 High Water Mark는 무엇이냐? Leader에 Producer가 데이터를 생산을 쭉 해나가면, Follower들은 Fetch Request를 통해 Leader의 데이터를 계속 복제하려 할 것이다. 이때, 모든 Follower들(ISR에 속한)이 전부 다 복제한 지점까지를 High Water Mark라고 한다.
그런데 이 replica.lag.max.messages로 ISR을 판단할 때 어떤 문제가 있을 수 있냐면,
- 메시지가 항상 일정한 비율로 Kafka로 들어올 때는 지연되는 경우가 없을것이므로 ISR들이 정상적으로 동작한다.
- 그런데 갑자기 메시지 유입량이 늘어난다면 예를 들어, 원래는 초당 3개의 메시지만 들어왔는데 갑자기 초당 20개의 메시지가 들어오면 20개의 차이가 갑자기 나니까 replica.lag.max.messages를 4로 설정하면 지연으로 판단하고 OSR로 상태를 변경시킨다.
- 그런데 실제 Follower들은 정상적으로 동작하고 단지 잠깐 지연만 발생했을 뿐인데 OSR로 판단하게 되는 문제가 발생한다. 이로 인해 운영중에 불필요한 에러 발생 및 그로 인해 불필요한 Retry를 유발하므로써 좋지 않은 상태가 된다)
그래서, replica.lag.time.max.ms로 판단해야 한다.
- Follower가 Leader로 Fetch 요청을 보내는 Interval을 체크
- 예) replica.lag.time.max.ms = 10000 이라면 Follower가 Leader로 Fetch 요청을 10000ms 내에만 요청하면 정상으로 판단
ISR은 Leader가 관리한다.
- Follower가 너무 느리면, Leader는 ISR에서 Follower를 제거하고, 변경 사항에 대한 메타데이터를 Controller가 받아 처리한다.
- 여기서 Controller란?
- Kafka Cluster 내의 Broker 중에 하나가 Controller가 된다.
- Controller는 Leader와 Replica 정보를 Cluster내의 다른 Broker들에게 전달한다.
- Controller가 Leader 장애 시 Leader Election을 수행
- Controller가 장애가 나면 다른 Active Broker들 중에서 재선출
Consumer 관련 Position들
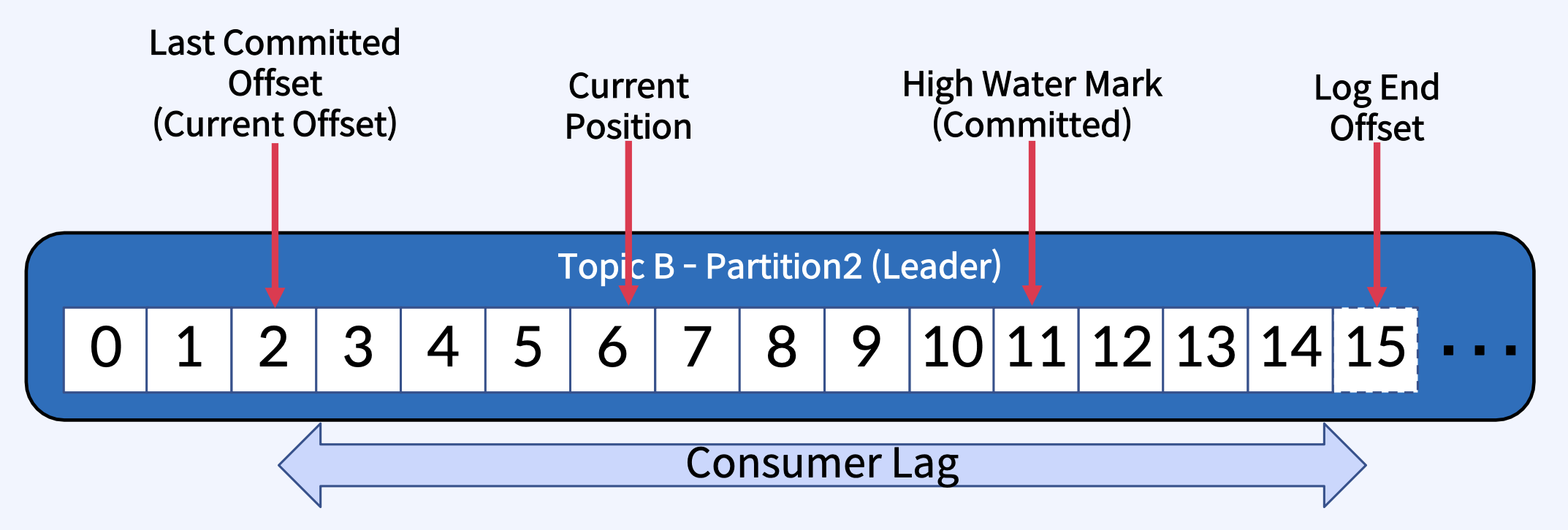
- Last Committed Offset(Current Offset): Consumer가 최종 Commit한 Offset
- Current Position: Consumer가 읽어간 위치(처리 중, Commit 전). 그러니까, 마지막으로 커밋한 지점은 2인데 Consumer가 데이터를 지금 현재 읽는중이고 2부터 6까지 읽고 있는 중이라고 생각하면 된다.
- High Water Mark(Committed): ISR간에 복제된 Offset.
- Log End Offset: Producer가 메시지를 보내서 저장된 로그의 맨 끝 Offset
High Water Mark(Committed)의 의미
- ISR 목록의 모든 Replicas가 메시지를 성공적으로 가져오면 Committed.
- Consumer는 Committed 메시지만 읽을 수 있다. (위 그림에서는 0 ~ 11번 메시지까지)
- Leader는 메시지를 Commit할 시기를 결정한다.
- Committed 메시지는 모든 Follower에서 동일한 Offset을 갖도록 보장한다. (모든 Replicas들이 0번 메시지는 0번 메시지를 가르키고, 10번 메시지는 10번 메시지를 가르키고, 11번 메시지는 11번 메시지를 가르킨다는 의미)
- 즉, 어떤 Replica가 Leader인지에 관계없이 모든 Consumer는 해당 Offset에서 같은 데이터를 볼 수 있다. (Leader, Follower 상관없이 0번 메시지는 모두 다 동일한 0번 메시지라는 것을 말함)
- Broker가 다시 시작할 때 Committed 메시지 목록을 유지하도록 하기 위해, Broker의 모든 Partition에 대한 마지막 Committed Offset은 replication-offset-checkpoint라는 파일에 기록됨
Message Commit 과정
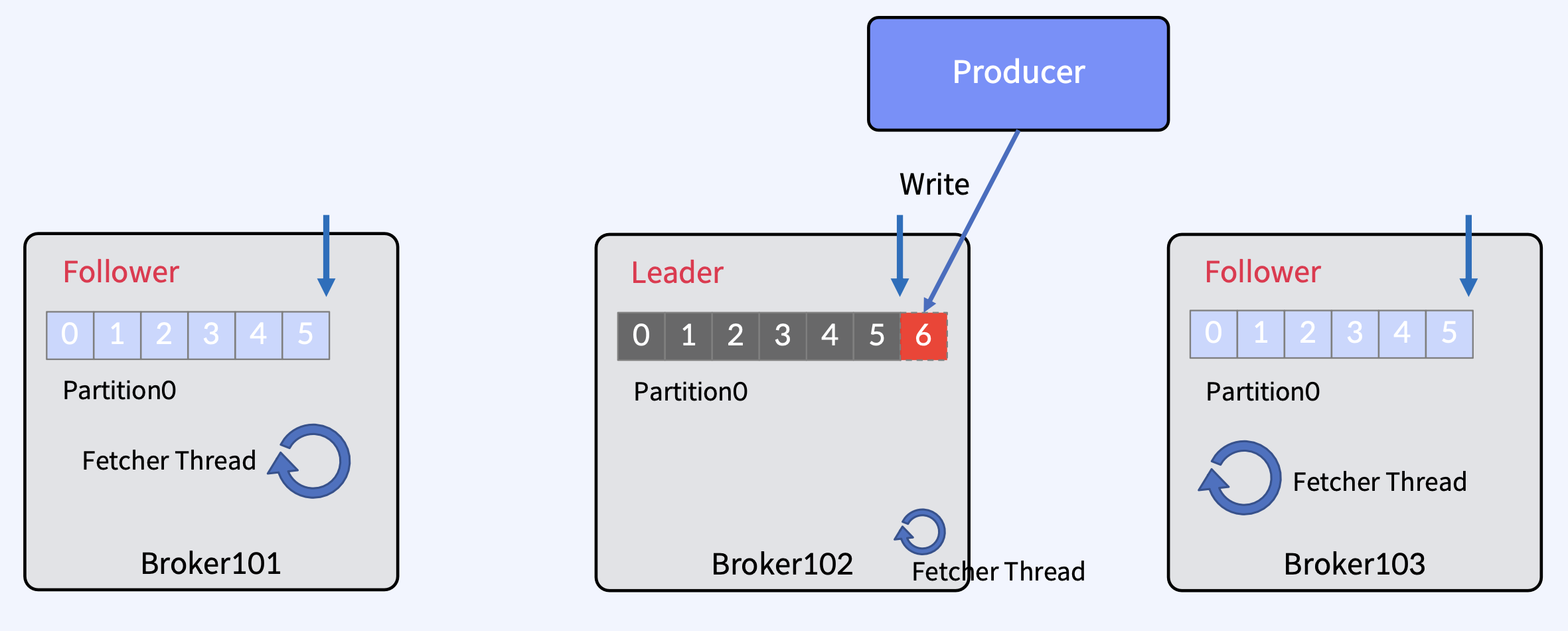
- Offset 5까지 복제가 완료된 상태에서, Producer가 메시지를 보내면 Leader가 offset 6에 새 메시지를 추가
- Fetcher Thread는 모든 브로커에 존재하고, 각 브로커에 모든 Follwer들이 본인의 Leader에 메시지를 가져오기 요청을 보낼 때 사용
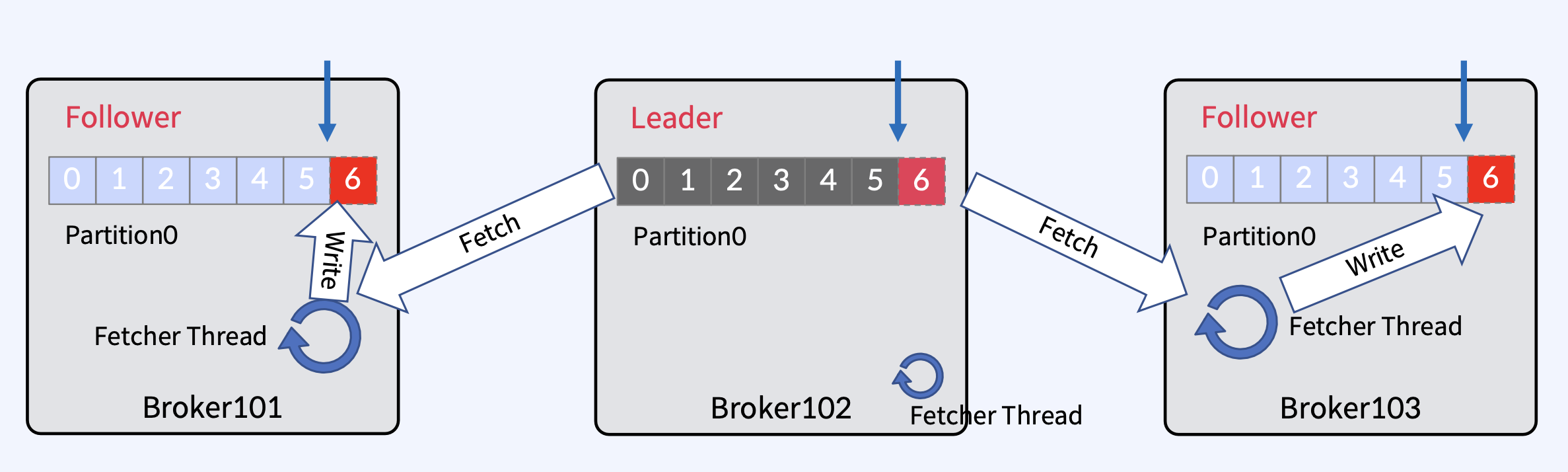
- 각 Follower들의 Fetcher Thread가 독립적으로 fetch를 수행하고, 가져온 메시지를 offset 6에 메시지를 write
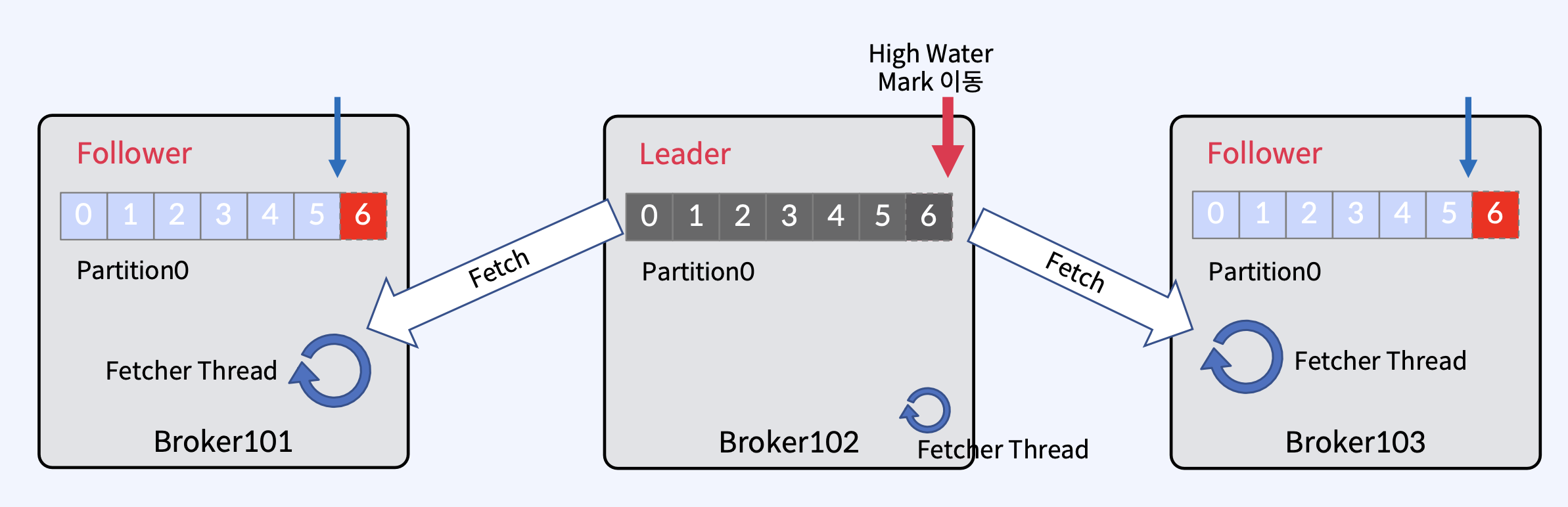
- 이 상태에서 각 Follwer들의 Fetcher Thread가 또 독립적으로 fetch를 수행하고 null을 받는데, null을 Leader가 준다는 것은 Leader가 모든 Follwer들에게 현재 내가 가진 모든 데이터를 다 정상적으로 줬음을 의미하므로, High Water Mark를 이동시킨다.
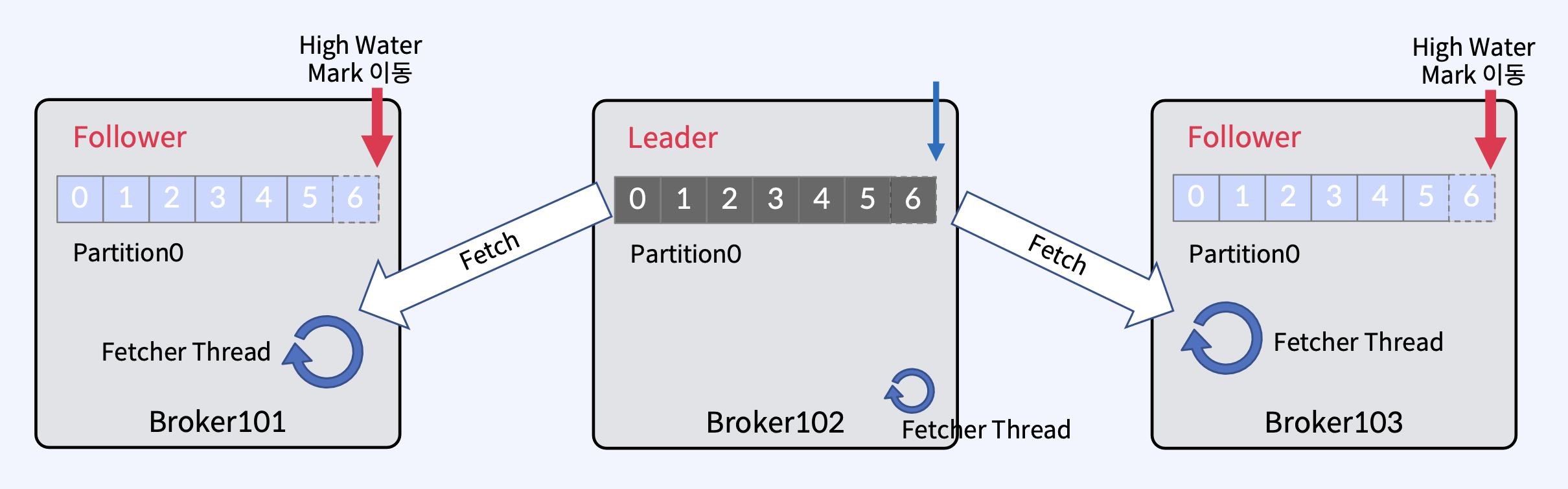
- 각 Follower들의 Fetcher Thread가 독립적으로 또 다시 fetch를 수행하고, High Water Mark를 받는다. 받은 High Water Mark로 이동한다.
정리하자면
- Partition을 복제(Replication)하여 다른 Broker 상에서 복제물(Replicas)을 만들어서 장애를 미리 대비함
- Replicas - Leader Partition, Follower Partition
- Producer는 Leader에만 Write하고, Consumer는 Leader로부터만 Read한다.
- Follower는 Leader의 Commit Log에서 데이터를 가져오기 요청(Fetch Request)으로 복제
- 복제본(Replicas-Leader/Follower)은 최대한 Rack 간에 균형을 유지하여 Rack 장애 대비하는 Rack Awareness 기능이 있다.
- In-Sync Replicas(ISR)는 High Water Mark 라고 하는 지점까지 동일한 Replicas(Leader, Follower)의 목록
- High Water Mark(Committed)는 ISR(Leader-Follower)간에 복제된 Offset
- Consumer는 Committed 메시지만 읽을 수 있다.
- Kafka Cluster 내의 Broker 중 하나가 Controller가 된다.
728x90
반응형
LIST
'Apache Kafka' 카테고리의 다른 글
| p8. Replica Failure (0) | 2025.03.15 |
|---|---|
| p7. Acks, Batch, Page Cache, Flush (0) | 2025.03.15 |
| p5. Consumer (0) | 2025.03.15 |
| p4. Producer (0) | 2025.03.15 |
| p3. Broker (0) | 2025.03.15 |