참고자료
김영한의 실전 자바 - 고급 3편, 람다, 스트림, 함수형 프로그래밍 강의 | 김영한 - 인프런
김영한 | , [사진]국내 개발 분야 누적 수강생 1위,제대로 만든 김영한의 실전 자바[사진][임베딩 영상]단순히 자바 문법을 안다? 이걸로는 안됩니다!전 우아한형제들 기술이사, 누적 수강생 40만
www.inflearn.com
Collectors
스트림이 중간 연산을 거쳐 최종 연산으로써 데이터를 처리할 때, 그 결과물이 필요한 경우가 많다. 대표적으로 "리스트나 맵 같은 자료구조에 담고싶다"거나 "통계 데이터를 내고 싶다"는 식의 요구가 있을 때, 이 최종 연산에 Collectors를 활용한다.
collect연산(예: stream.collect(...))은 반환값을 만들어내는 최종 연산이다. collect(Collector<? super T, A, R> collector)형태를 주로 사용하고, Collectors 클래스 안에 준비된 여러 메서드를 통해서 다양한 수집 방식을 적용할 수 있다.
Collectors의 주요 기능
List 수집
- Collectors.toList()
- Collectors.toUnmodifiableList() : 불변 리스트
Set 수집
- Collectors.toSet()
- Collectors.toCollection(HashSet::new) : 특정 Set 타입으로 모으려면 toCollection 사용
Map 수집
- Collectors.toMap(keyMapper, valueMapper)
- Collectors.toMap(keyMapper, valueMapper, mergeFunction, mapSupplier)
- 중복 키가 발생할 경우, mergeFunction 으로 해결할 수 있고, mapSupplier로 맵 타입을 지정할 수 있다.
그룹화
- Collectors.groupingBy(classifier)
- Collectors.groupingBy(classifier, downstreamCollector)
- 특정 기준 함수(classifier)에 따라 그룹별로 스트림 요소를 묶는다. 각 그룹에 대해 추가로 적용할 다운스트림 컬렉터를 지정할 수 있다.
분할
- Collectors.partitioningBy(predicate)
- Collectors.partitioningBy(predicate, downstreamCollector)
- predicate 결과가 true와 false로 나뉘어, 2개 그룹으로 분할한다.
통계
- Collectors.counting()
- Collectors.summingInt()
- Collectors.averagingInt()
- Collectors.summarizingInt()
- 등
- 요소의 개수, 합계, 평균, 최소, 최대값을 구하거나, IntSummaryStatistics 같은 통계 객체로도 모을 수 있다.
리듀싱
- Collectors.reducing()
- 스트림의 reduce()와 유사하게, Collector 환경에서 요소를 하나로 합치는 연산을 할 수 있다.
문자열 연결
- Collectors.joining(delimiter, prefix, suffix)
- 문자열 스트림을 하나로 합쳐서 연결한다. 구분자(delimiter), 접두사(prefix), 접미사(suffix)등을 붙일 수 있다.
매핑
- Collectors.mapping(mapper, downstream)
- 각 요소를 다른 값으로 변환(mapper)한뒤 다운스트림 컬렉터로 넘긴다.
기본 수집 - 예시 코드
package stream.collectors;
import java.util.List;
import java.util.Set;
import java.util.TreeSet;
import java.util.stream.Stream;
import static java.util.stream.Collectors.*;
public class Collectors1Basic {
public static void main(String[] args) {
// 기본 기능
List<String> list = Stream.of("Java", "Spring", "JPA")
.collect(toList());
System.out.println("list = " + list);
list.set(0, "Python");
System.out.println("list = " + list);
// 수정 불가능 리스트
List<Integer> unmodifiableList = Stream.of(1, 2, 3)
.toList();
System.out.println("unmodifiableList = " + unmodifiableList);
// Set
Set<Integer> set = Stream.of(3, 1, 2, 2, 3, 3, 3)
.collect(toSet());
System.out.println("set = " + set);
// Set 타입 지정
TreeSet<Integer> treeSet = Stream.of(3, 4, 5, 2, 1)
.collect(toCollection(TreeSet::new));
System.out.println("treeSet = " + treeSet);
}
}실행 결과
list = [Java, Spring, JPA]
list = [Python, Spring, JPA]
unmodifiableList = [1, 2, 3]
set = [1, 2, 3]
treeSet = [1, 2, 3, 4, 5]- Collectors.toList()는 수정 가능한 ArrayList로 수집한다.
- Collectors.toUnmodifiableList()는 자바 10부터 제공하는 불변 리스트를 만들어서 수정할 수 없다.
- Collectors.toSet()은 중복을 제거한 채로 Set에 수집한다.
- Collectors.toCollection(TreeSet::new)처럼 toCollection()을 사용하면 원하는 컬렉션 구현체를 직접 지정할 수 있다.
참고로, Collectors.toUnmodifiableList() 대신 자바 16부터는 Stream.toList()를 바로 호출할 수 있다. 얘는 마찬가지로 불변 리스트를 제공한다.
또한, Collectors를 사용할 때는 static import를 추천한다.
Map 수집
package stream.collectors;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.stream.Stream;
import static java.util.stream.Collectors.toMap;
public class Collectors2Map {
public static void main(String[] args) {
Map<String, Integer> map1 = Stream.of("Apple", "Banana", "Tomato")
.collect(toMap(
name -> name,
String::length
)
);
System.out.println("map1 = " + map1);
// 키 중복 예외 발생 코드
/*Map<String, Integer> map2 = Stream.of("Apple", "Apple", "Banana", "Tomato")
.collect(toMap(
name -> name,
String::length
)
);
System.out.println("map2 = " + map2);*/
// 키 중복 대안 (병합)
Map<String, Integer> map3 = Stream.of("Apple", "Apple", "Banana", "Tomato")
.collect(toMap(
name -> name,
String::length,
(oldValue, newValue) -> oldValue
)
);
System.out.println("map3 = " + map3);
// Map 타입 지정
Map<String, Integer> map4 = Stream.of("Apple", "Apple", "Banana", "Tomato")
.collect(toMap(
name -> name,
String::length,
(oldValue, newValue) -> oldValue,
LinkedHashMap::new
)
);
System.out.println("map4 = " + map4);
}
}실행 결과
map1 = {Apple=5, Tomato=6, Banana=6}
map3 = {Apple=5, Tomato=6, Banana=6}
map4 = {Apple=5, Banana=6, Tomato=6}- Collectors.toMap(keyMapper, valueMapper): 각 요소에 대한 키, 값을 지정해서 Map을 만든다.
- 키가 중복될 경우 IllegalStateException이 발생한다.
- 그래서, 중복의 경우 세번째 인자로 mergeFunction을 넘기는데 위와 같이 사용한다. (oldValue, newValue) -> oldValue. 이렇게 하면 이전에 같은 키로 저장된 값과 이번에 같은 키의 값 중 이전 값으로 처리한다는 의미가 된다. 두 값을 합칠 수도 있다. 이렇게. (oldValue, newValue) -> oldValue + newValue.
- 마지막 인자로 LinkedHashMap::new 같은 걸 넘기면, 결과를 LinkedHashMap으로 얻을 수 있다.
그룹과 분할 수집
package stream.collectors;
import java.util.List;
import java.util.Map;
import static java.util.stream.Collectors.groupingBy;
import static java.util.stream.Collectors.partitioningBy;
public class Collectors3Group {
public static void main(String[] args) {
// 첫 글자 알파벳을 기준으로 그룹화
List<String> names = List.of("Apple", "Avocado", "Banana", "Blueberry", "Cherry");
Map<String, List<String>> grouped = names.stream()
.collect(groupingBy(
name -> name.substring(0, 1)
)
);
System.out.println("grouped = " + grouped);
// 짝수인지 여부로 분할
List<Integer> numbers = List.of(1, 2, 3, 4, 5, 6);
Map<Boolean, List<Integer>> partitioned = numbers.stream()
.collect(partitioningBy(n -> n % 2 == 0));
System.out.println("partitioned = " + partitioned);
}
}실행 결과
grouped = {A=[Apple, Avocado], B=[Banana, Blueberry], C=[Cherry]}
partitioned = {false=[1, 3, 5], true=[2, 4, 6]}- Collectors.groupingBy(...)는 특정 기준(여기서는 첫 글자)에 따라 스트림 요소를 여러 그룹으로 묶는다. 결과는 Map<기준, List<요소>> 형태이다.
- Collectors.partitioningBy(...)는 단순하게 true와 false 두 그룹으로 나눈다. 예제에서는 짝수(true), 홀수(false)로 분할됐다.
최솟값 최댓값 수집
package stream.collectors;
import java.util.stream.IntStream;
import java.util.stream.Stream;
import static java.util.stream.Collectors.maxBy;
public class Collectors4MinMax {
public static void main(String[] args) {
// 이렇게 사용할 때는 downstream 을 사용할 때 용이
Integer max1 = Stream.of(1, 2, 3)
.collect(maxBy(Integer::compareTo))
.get();
System.out.println("max1 = " + max1);
// 일반적으로는 그냥 max()를 사용하면 더 편리
Integer max2 = Stream.of(1, 2, 3)
.max(Integer::compareTo).get();
System.out.println("max2 = " + max2);
// 기본형 특화 스트림은 매우 간단
int max3 = IntStream.of(1, 2, 3).max().getAsInt();
System.out.println("max3 = " + max3);
}
}실행 결과
max1 = 3
max2 = 3
max3 = 3- Collectors.maxBy(...)이나 Collectors.minBy(...)를 통해 최소, 최댓값을 구할 수 있다. 다만 스트림 자체가 제공하는 max(), min() 메서드를 사용하면 더 간단하다. Collectors가 제공하는 이 기능들은 다운 스트림 컬렉터에서 유용하게 사용할 수 있다.
- 기본형 특화 스트림(IntStream 등)을 쓰면, .max().getAsInt()처럼 바로 기본형으로 결과를 얻을 수 있다.
통계 수집
package stream.collectors;
import java.util.IntSummaryStatistics;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
import java.util.stream.Stream;
import static java.util.stream.Collectors.*;
public class Collectors4Summing {
public static void main(String[] args) {
// 이것도 다운스트림 컬렉터에서 유용하게 사용
Long counting = Stream.of(1, 2, 3)
.collect(counting());
System.out.println("counting = " + counting);
// 일반적으로는 count() 그냥 쓰면 편리
long count = Stream.of(1, 2, 3)
.count();
System.out.println("count = " + count);
System.out.println("-------------------------------");
// 평균 구하기 (averagingInt)
Double average1 = Stream.of(1, 2, 3)
.collect(averagingInt(i -> i));
System.out.println("average1 = " + average1);
// 기본형 특화 스트림으로 변형
double average2 = Stream.of(1, 2, 3)
.mapToInt(i -> i)
.average().getAsDouble();
System.out.println("average2 = " + average2);
// 처음부터 기본형 특화 스트림 사용
double average3 = IntStream.of(1, 2, 3)
.average()
.getAsDouble();
System.out.println("average3 = " + average3);
System.out.println("-------------------------------");
// 통계
IntSummaryStatistics stats = Stream.of("Apple", "Banana", "Tomato")
.collect(summarizingInt(String::length));
System.out.println("stats.getCount() = " + stats.getCount());
System.out.println("stats.getSum() = " + stats.getSum());
System.out.println("stats.getAverage() = " + stats.getAverage());
System.out.println("stats.getMin() = " + stats.getMin());
System.out.println("stats.getMax() = " + stats.getMax());
}
}실행 결과
counting = 3
count = 3
-------------------------------
average1 = 2.0
average2 = 2.0
average3 = 2.0
-------------------------------
stats.getCount() = 3
stats.getSum() = 17
stats.getAverage() = 5.666666666666667
stats.getMin() = 5
stats.getMax() = 6- Collectors.counting()은 요소 개수를 구한다.
- Collectors.averagingInt()는 요소들의 평균을 구한다.
- Collectors.summarizingInt()는 합계, 최솟값, 최댓값, 평균 등 다양한 통계 정보를 담은 IntSummaryStatistics 객체를 얻는다.
- 자주 쓰이는 통계 메서드로 Collectors.summingInt(), Collectors.maxBy(), Collectors.minBy(), Collectors.counting() 등이 있다.
- Collectors의 일부 기능은 스트림에서 직접 제공하는 기능과 중복된다. Collectors의 기능들은 뒤에서 설명할 다운 스트림 컬렉터에서 유용하게 사용할 수 있다.
리듀싱 수집
package stream.collectors;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
import static java.util.stream.Collectors.*;
import static java.util.stream.Collectors.reducing;
public class Collectors5Reducing {
public static void main(String[] args) {
List<String> names = List.of("a", "b", "c", "d");
// 컬렉션의 reducing은 주로 다운스트림에 사용
String joined1 = names.stream()
.collect(reducing(
(s1, s2) -> s1 + ", " + s2)
)
.get();
System.out.println("joined1 = " + joined1);
Optional<String> reduce = names.stream()
.reduce((s1, s2) -> s1 + ", " + s2);
System.out.println("reduce.get() = " + reduce.get());
String joined2 = names.stream()
.collect(joining(", ", "[", "]"));
System.out.println("joined2 = " + joined2);
}
}실행 결과
joined1 = a, b, c, d
reduce.get() = a, b, c, d
joined2 = [a, b, c, d]- Collectors.reducing(...)은 최종적으로 하나의 값으로 요소들을 합치는 방식을 지정한다. 여기서는 문자열들을 ',' 로 이어붙였다.
- 스트림 자체의 reduce(...)와 유사한 기능이다.
- 문자열을 이어 붙일 때는 Collectors.joining()이나 String.join()을 쓰는게 더 간편하다.
다운 스트림 컬렉터
다운 스트림 컬렉터가 필요한 이유
- groupingBy(...)를 사용하면 일단 요소가 그룹별로 묶이지만, 그룹 내 요소를 구체적으로 어떻게 처리할지는 기본적으로 Collectors.toList()만 적용된다.
- 그런데, 실무에서는 "그룹별 총합, 평균, 최대/최소값, 매핑된 결과, 통계"등을 바로 얻고 싶을 때가 많다.
- 예를 들어, "학년별로 학생들을 그룹화한 뒤, 각 학년 그룹에서 평균 점수를 구하고 싶다"는 상황에서는 단순히 List<Student>로 끝나는 게 아니라, 그룹 내 학생들의 점수를 합산하고 평균을 내는 동작이 더 필요하다.
- 이처럼, 그룹화된 이후 각 그룹 내부에서 추가적인 연산 또는 결과물(예: 평균, 합계, 최댓값, 최솟값, 통계, 다른 타입으로 변환 등)을 정의하는 역할을 하는 것이 바로 다운 스트림 컬렉터이다.
- 이때, 다운 스트림 컬렉터를 활용하면, "그룹 내부"를 다시 한번 모으거나 집계하여 원하는 결과를 얻을 수 있다.
- 예: groupingBy(분류함수, counting()) → 그룹별 개수
- 예: groupingBy(분류함수, summingInt(Student::getScore)) → 그룹별 점수 합계
- 예: groupingBy(분류함수, mapping(Student::getName, toList())) → 그룹별 학생 이름 리스트
그림 예시
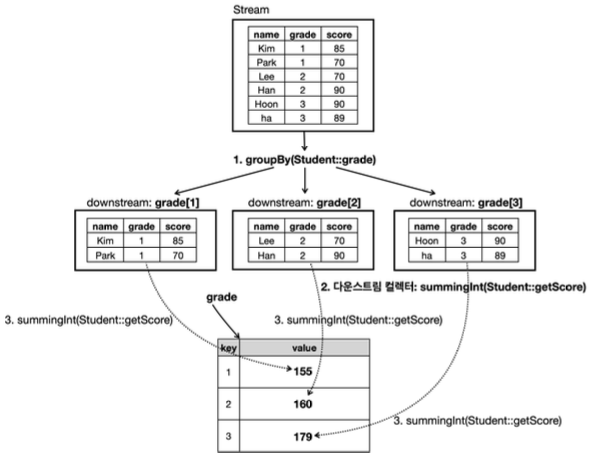
- 각 학년별로 그룹화한 뒤, 그룹화한 학년별 점수의 합을 구하는 방법
다운 스트림 컬렉터의 종류
| Collector | 사용 메서드 예시 | 설명 | 예시 반환 타입 |
| counting() | Collectors.counting() | 그룹 내(혹은 스트림 내) 요소들의 개수를 센다. | Long |
| summingInt() 등 | Collectors.summingInt(...), Collectors.summingLong(...) |
그룹 내 요소들의 특정 정수형 속성을 모두 합산한다. | Integer, Long 등 |
| averagingInt() 등 | Collectors.averagingInt(...), Collectors.averagingDouble(...) |
그룹 내 요소들의 특정 속성 평균값을 구한다. | Double |
| minBy(), maxBy() | Collectors.minBy(Comparator), Collectors.maxBy(Comparator) |
그룹 내 최소, 최댓값을 구한다. | Optional<T> |
| summarizingInt() 등 | Collectors.summarizingInt(...), Collectors.summarizingLong(...) |
개수, 합계, 평균, 최소, 최댓값을 동시에 구할 수 있는 SummaryStatistics 객체를 반환한다. | IntSummaryStatistics 등 |
| mapping() | Collectors.mapping(변환함수, 다운스트림) | 각 요소를 다른 값으로 변환한 뒤, 변환된 값들을 다시 다른 Collector로 수집할 수 있게 한다. | 다운스트림 반환 타입에 따라 달라짐 |
| collectingAndThen() | Collectors.collectingAndThen(다른 컬렉터, 변환 함수) | 다운 스트림 컬렉터의 결과를 최종적으로 한번 더 가공(후처리)할 수 있다. | 후처리 후의 타입 |
| reducing() | Collectors.reducing(초기값, 변환 함수, 누적 함수), Collectors.reducing(누적 함수) |
스트림의 recuce()와 유사하게, 그룹 내 요소들을 하나로 합치는 로직을 정의할 수 있다. | 누적 로직에 따라 달라짐 |
| toList(), toSet() | Collectors.toList(), Collectors.toSet() |
그룹 내(혹은 스트림 내) 요소를 리스트나 집합으로 수집한다. toCollection(...)으로 구현체 지정 가능 | List<T>, Set<T> |
다운 스트림 컬렉터 예제 1
package stream.collectors;
public class Student {
private String name;
private int grade;
private int score;
public Student(String name, int grade, int score) {
this.name = name;
this.grade = grade;
this.score = score;
}
public String getName() {
return name;
}
public int getGrade() {
return grade;
}
public int getScore() {
return score;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", grade=" + grade +
", score=" + score +
'}';
}
}
package stream.collectors;
import java.util.List;
import java.util.Map;
import static java.util.stream.Collectors.*;
public class DownStreamMain1 {
public static void main(String[] args) {
List<Student> students = List.of(
new Student("Kim", 1, 85),
new Student("Park", 1, 70),
new Student("Lee", 2, 70),
new Student("Han", 2, 90),
new Student("Hoon", 3, 90),
new Student("Ha", 3, 89)
);
// 1단계: Grade 별로 그룹화
Map<Integer, List<Student>> collect1_1 = students.stream()
.collect(groupingBy(
Student::getGrade,
toList()
)
);
System.out.println("collect1_1 = " + collect1_1);
// 1단계: 다운 스트림에서 toList() 생략 가능
Map<Integer, List<Student>> collect1_2 = students.stream()
.collect(groupingBy(Student::getGrade));
System.out.println("collect1_2 = " + collect1_2);
// 2단계: 학년별로 학생들의 이름을 출력
Map<Integer, List<String>> collect2 = students.stream()
.collect(groupingBy(
Student::getGrade,
mapping( // 다운스트림 1: 학생 -> 이름 변환
Student::getName,
toList() // 다운스트림 2: 변환된 값을 List 로 수집
)
)
);
System.out.println("collect2 = " + collect2);
// 3단계: 학년별로 학생들의 수를 출력
Map<Integer, Long> collect3 = students.stream()
.collect(groupingBy(
Student::getGrade,
counting()
)
);
System.out.println("collect3 = " + collect3);
// 4단계: 학년별로 학생들의 평균 성적 출력
Map<Integer, Double> collect4 = students.stream()
.collect(groupingBy(
Student::getGrade,
averagingDouble(Student::getScore)
)
);
System.out.println("collect4 = " + collect4);
}
}실행 결과
collect1_1 = {1=[Student{name='Kim', grade=1, score=85}, Student{name='Park', grade=1, score=70}], 2=[Student{name='Lee', grade=2, score=70}, Student{name='Han', grade=2, score=90}], 3=[Student{name='Hoon', grade=3, score=90}, Student{name='Ha', grade=3, score=89}]}
collect1_2 = {1=[Student{name='Kim', grade=1, score=85}, Student{name='Park', grade=1, score=70}], 2=[Student{name='Lee', grade=2, score=70}, Student{name='Han', grade=2, score=90}], 3=[Student{name='Hoon', grade=3, score=90}, Student{name='Ha', grade=3, score=89}]}
collect2 = {1=[Kim, Park], 2=[Lee, Han], 3=[Hoon, Ha]}
collect3 = {1=2, 2=2, 3=2}
collect4 = {1=77.5, 2=80.0, 3=89.5}
다운 스트림 컬렉터 예제 2
package stream.collectors;
import java.util.Comparator;
import java.util.List;
import java.util.Map;
import java.util.Optional;
import static java.util.stream.Collectors.*;
public class DownStreamMain2 {
public static void main(String[] args) {
List<Student> students = List.of(
new Student("Kim", 1, 85),
new Student("Park", 1, 70),
new Student("Lee", 2, 70),
new Student("Han", 2, 90),
new Student("Hoon", 3, 90),
new Student("Ha", 3, 89)
);
// 1단계: 학년별로 학생들을 그룹화해라.
Map<Integer, List<Student>> collect1 = students.stream()
.collect(groupingBy(Student::getGrade));
System.out.println("collect1 = " + collect1);
// 2단계: 학년별로 가장 점수가 높은 학생을 구해라. reducing 사용
Map<Integer, Optional<Student>> collect2 = students.stream()
.collect(groupingBy(
Student::getGrade,
reducing((s1, s2) -> s1.getScore() > s2.getScore() ? s1 : s2)
)
);
System.out.println("collect2 = " + collect2);
// 3단계: 학년별로 가장 점수가 높은 학생을 구해라. maxBy 사용
Map<Integer, Optional<Student>> collect3 = students.stream()
.collect(groupingBy(
Student::getGrade,
maxBy(Comparator.comparing(Student::getScore))
)
);
System.out.println("collect3 = " + collect3);
// 4단계: 학년별로 가장 점수가 높은 학생의 이름을 구해라 (collectingAndThen + maxBy)
Map<Integer, String> collect4 = students.stream()
.collect(groupingBy(
Student::getGrade,
collectingAndThen(
maxBy(Comparator.comparing(Student::getScore)),
sO -> sO.map(Student::getName).orElse(null)
)
)
);
System.out.println("collect4 = " + collect4);
}
}실행 결과
collect1 = {1=[Student{name='Kim', grade=1, score=85}, Student{name='Park', grade=1, score=70}], 2=[Student{name='Lee', grade=2, score=70}, Student{name='Han', grade=2, score=90}], 3=[Student{name='Hoon', grade=3, score=90}, Student{name='Ha', grade=3, score=89}]}
collect2 = {1=Optional[Student{name='Kim', grade=1, score=85}], 2=Optional[Student{name='Han', grade=2, score=90}], 3=Optional[Student{name='Hoon', grade=3, score=90}]}
collect3 = {1=Optional[Student{name='Kim', grade=1, score=85}], 2=Optional[Student{name='Han', grade=2, score=90}], 3=Optional[Student{name='Hoon', grade=3, score=90}]}
collect4 = {1=Kim, 2=Han, 3=Hoon}
정리
다운 스트림 컬렉터를이해하면, groupingBy(...)나 partitioningBy(...)로 그룹화, 분할을 한 뒤 내부 요소를 어떻게 가공하고 수집할지 자유롭게 설계할 수 있다.
'JAVA의 가장 기본이 되는 내용' 카테고리의 다른 글
| 즉시 평가와 지연 평가 (0) | 2025.04.01 |
|---|---|
| Optional - 값 획득, 값 처리 방식 (0) | 2025.04.01 |
| 기본형 특화 스트림(IntStream 등) (0) | 2025.03.31 |
| takeWhile, dropWhile, flatMap - Stream API (0) | 2025.03.31 |
| 람다 vs 익명 클래스 (0) | 2025.03.30 |