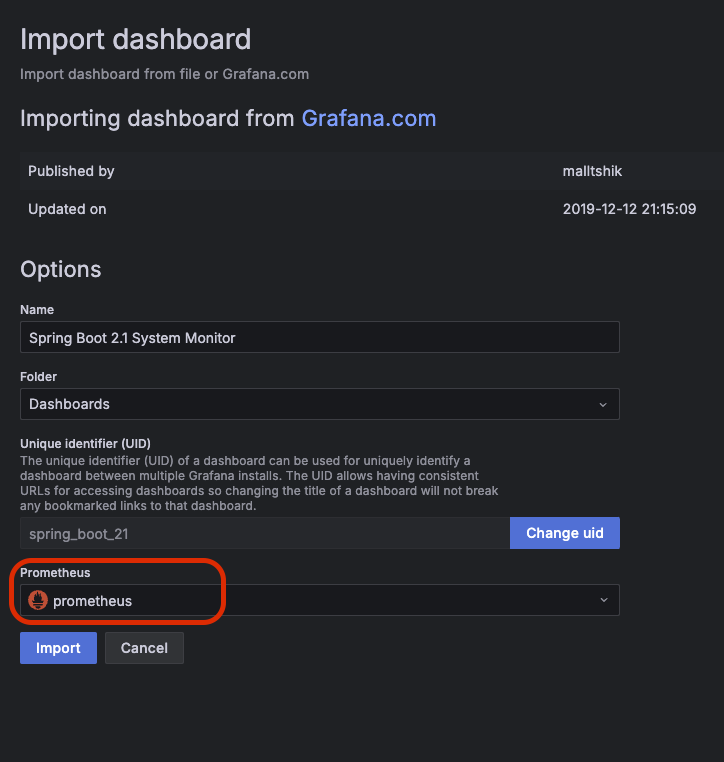
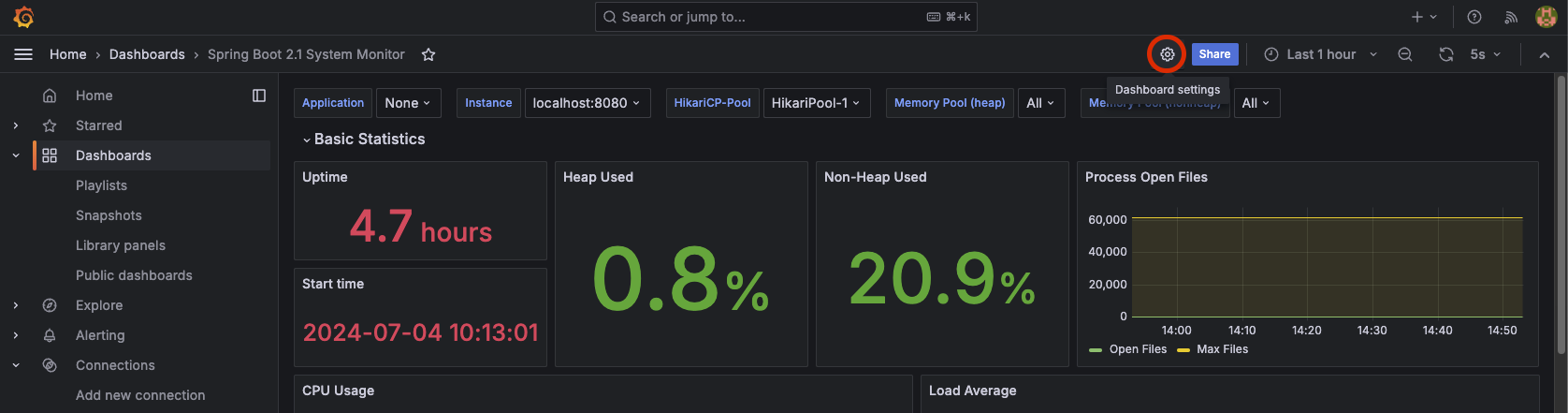
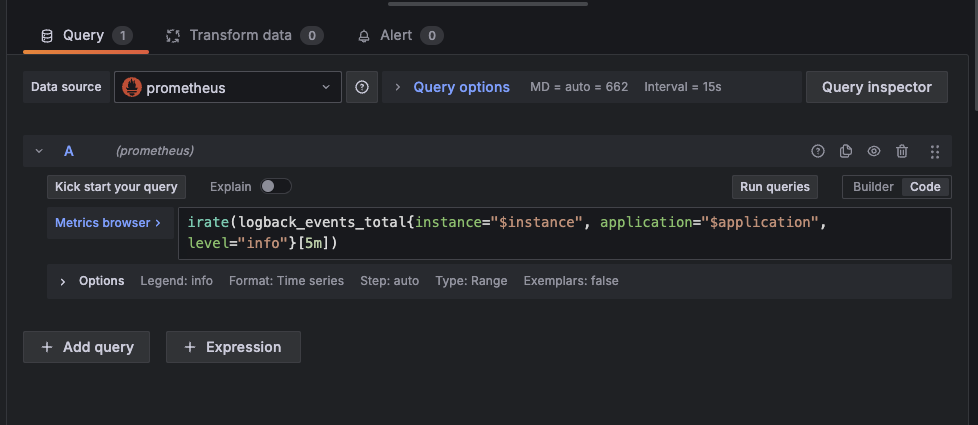
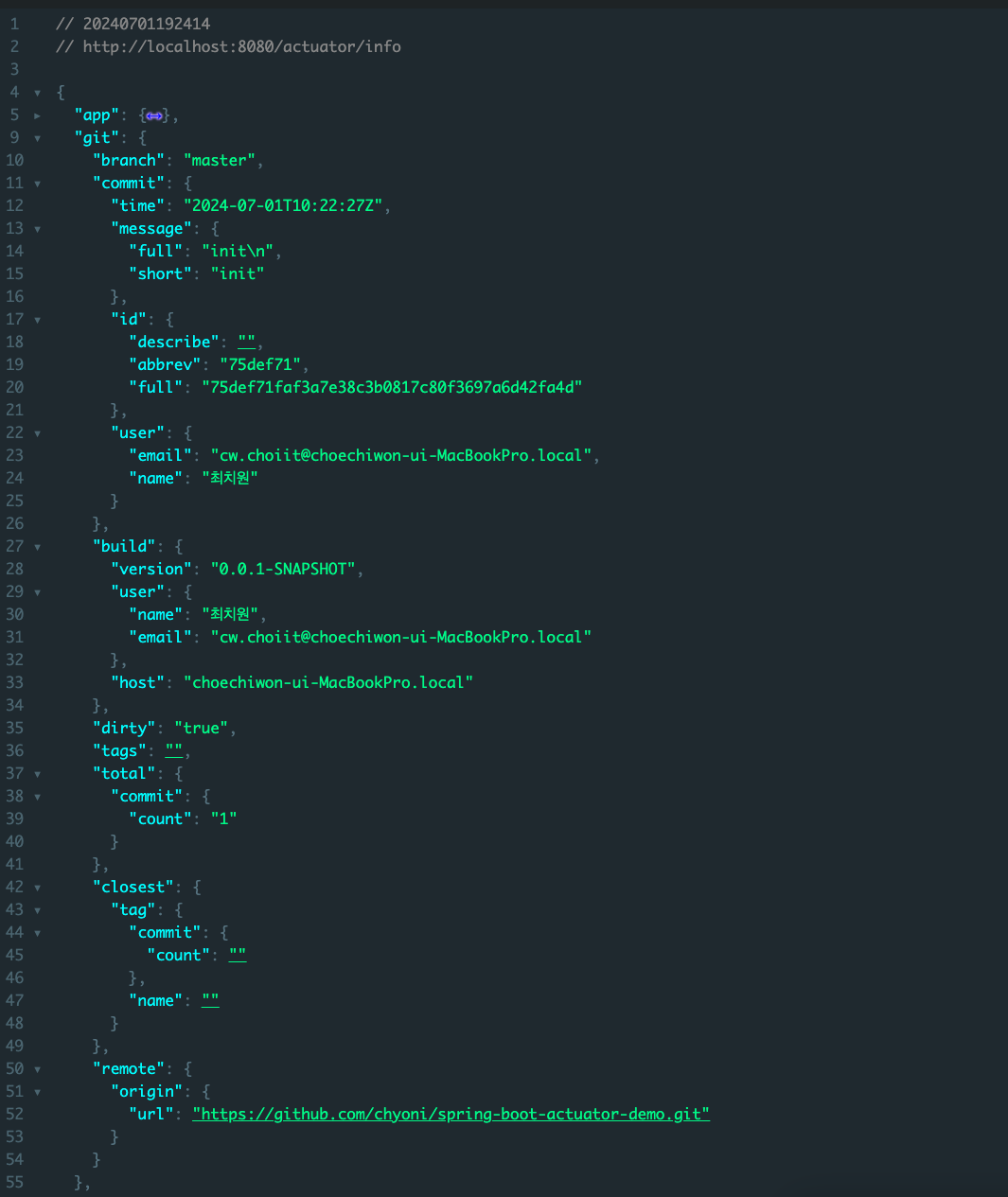
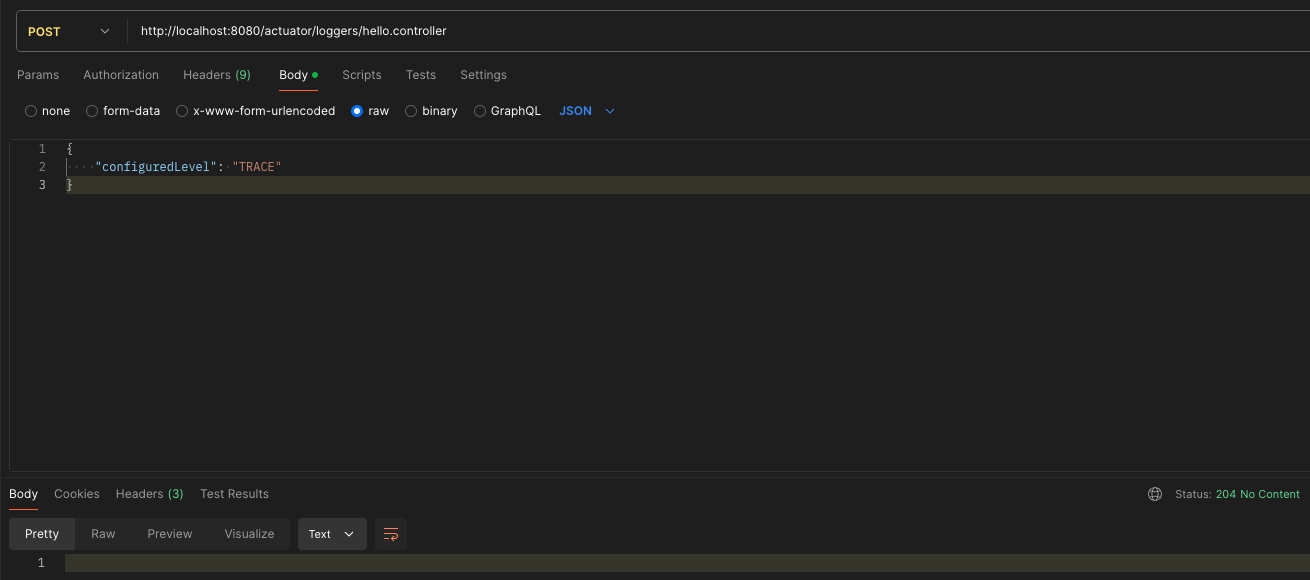
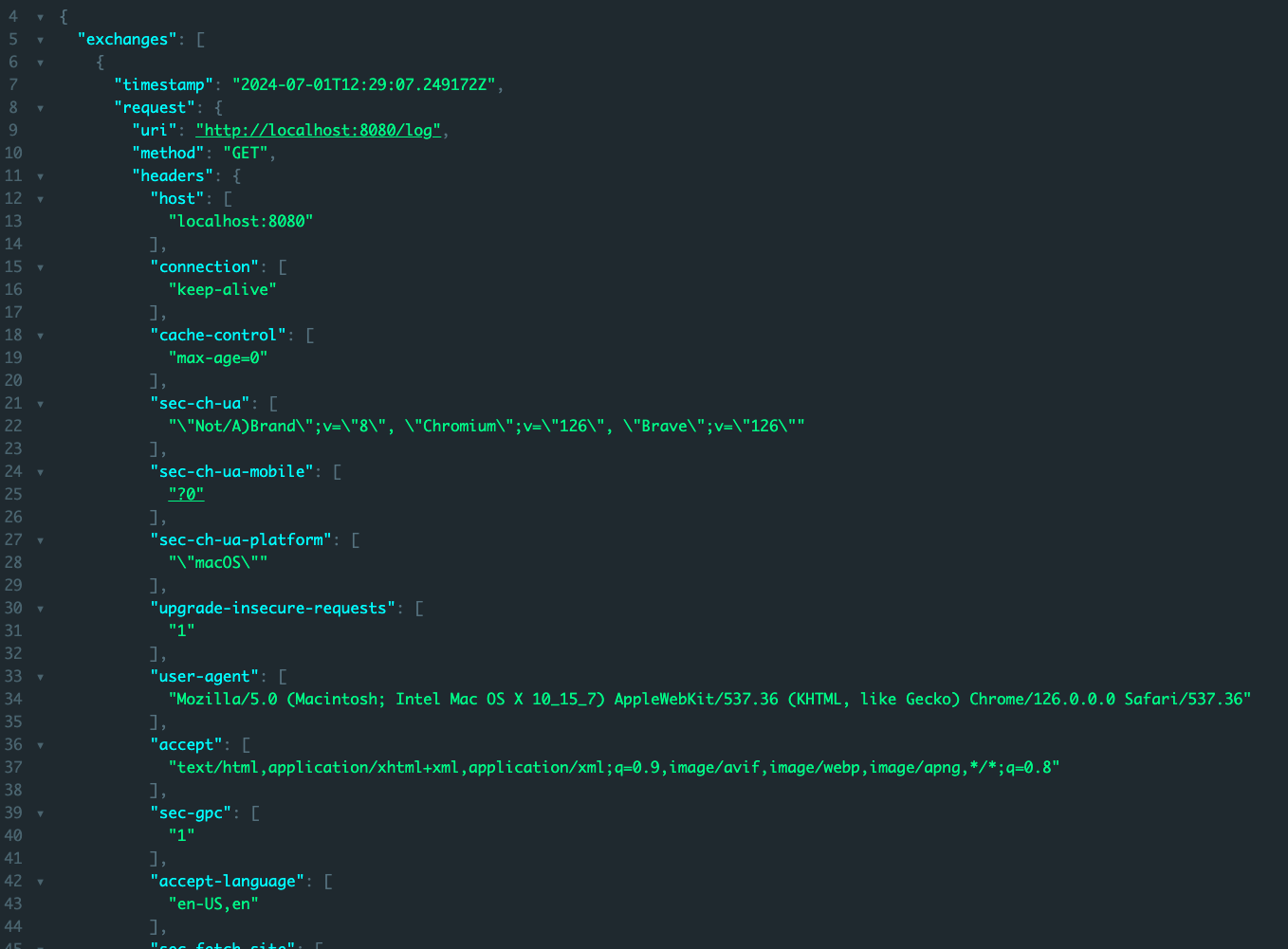
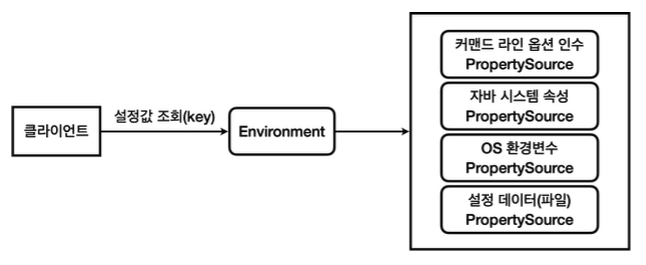
근데 이게 한번 제대로 팍 이해하고 넘어가지 않으면 그놈이 그놈같고 이게 뭔 차인가 싶으니 제대로 딱 정리 한번 하기로 마음 먹었다.
우선, 반드시 지켜야할 건 운영 시스템에는 System.out.println()같은 시스템 콘솔을 사용해서 필요한 정보를 출력하지 않고 별도의 로깅 라이브러리를 사용해서 로그를 출력해야 한다. 왜 그럴까? 가장 큰 이유는 불 필요한 로그를 운영 시스템에 찍을 필요가 없는데 이 시스템 콘솔에 찍는건 불 필요한 로그까지 다 남게 되기 때문이다.
여기서 불필요한 로그라는 건? 아마 `TRACE`, `DEBUG` 레벨의 로그일거다. 운영상에 찍지 않고 개발중이거나 디버깅할때 또는 버그를 잡기 위해서 찍어보는 로그. 이게 운영상에 찍히게 되면 로그가 남발이 되니까 빨리 필요한 정보를 캐치하는것도 쉽지 않고, 로그 파일에 지저분하게 남기 때문에 성능도 가독성도 떨어지는 사태가 발생한다.
근데, 시스템 콘솔로 찍는 경우는 이 레벨이란게 없기 때문에 모든 로그가 다 남게 된다. 그리고 가장 최악은 이 시스템 콘솔에 뭔가를 찍을때 연산 작업이 들어간다면 그것이야말로 성능의 가장 불필요한 낭비가 된다. 그래서 운영상에선 System.out.println()이런 시스템 콘솔에 직접 출력하는 것은 안된다.
여기서 말하는 연산 작업이란? 아래 같은 코드를 말한다.
int a = 10;
int b = 5;
System.out.println("a + b: " + (a + b));
참고로, 연산 작업이 아니더라도 그냥 기본적으로 System.out 보다 로그 라이브러리(내부 버퍼링, 멀티 쓰레드 등등)를 사용하는게 더 성능이 좋다.
로깅 라이브러리
스프링 부트를 사용한다면, 스프링 부트 로깅 라이브러리(spring-boot-starter-logging)가 함께 포함된다.
스프링 부트 로깅 라이브러리는 기본으로 다음 로깅 라이브러리를 사용한다.
SLF4J - `https://www.slf4j.org`
Logback - `https://logback.qos.ch`
라이브러리를 두개나 사용하는 건가요? 아니다.
로그 라이브러리는 Logback, Log4J, Log4J2 등 수많은 라이브러리가 있는데 A 프로젝트는 이것, B 프로젝트는 저것 이렇게 프로젝트 또는 회사마다 다 다른 라이브러리를 사용하면 연동의 문제가 생기니 이럴때 항상 뭐다? 인터페이스 - 구현체가 등장한다.
그래서, 인터페이스가 SLF4J고 그 구현체가 Logback, Log4J, Log4J2가 된다. 실무에서는 스프링 부트가 기본으로 제공하는 Logback을 대부분 사용한다. 그럼 어떻게 사용하면 될까?
LogTestController
package net.cwchoiit.springmvc.basic;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class LogTestController {
private final Logger log = LoggerFactory.getLogger(LogTestController.class);
@GetMapping("/logging")
public String logging() {
log.info("LogTestController.logging");
return "ok";
}
}
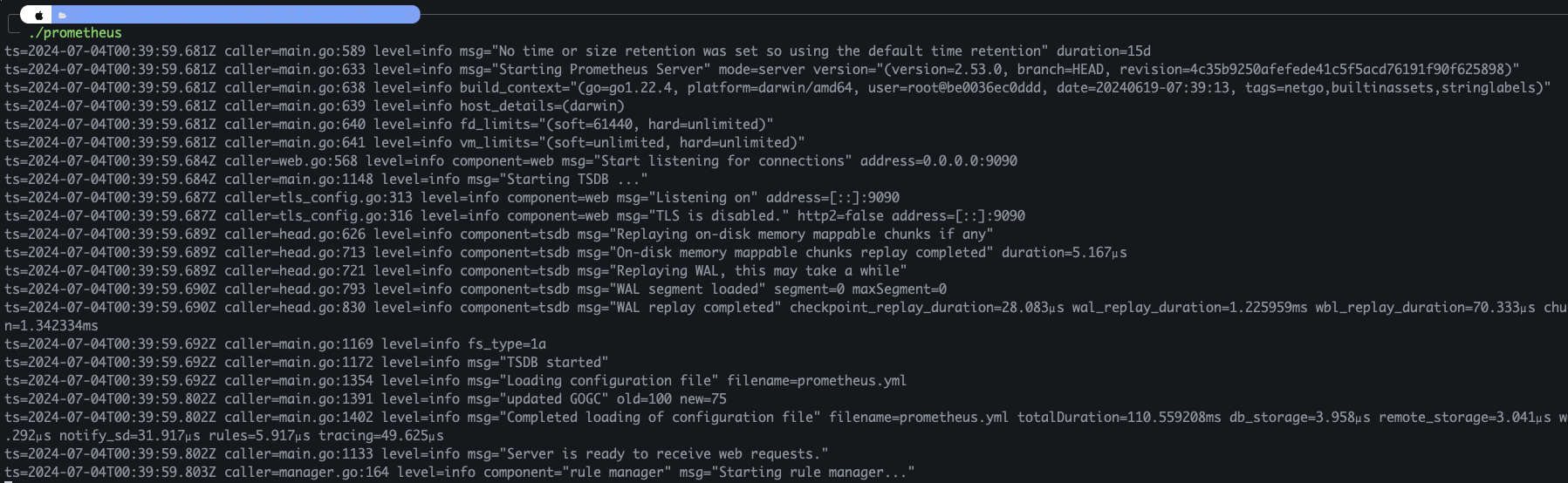
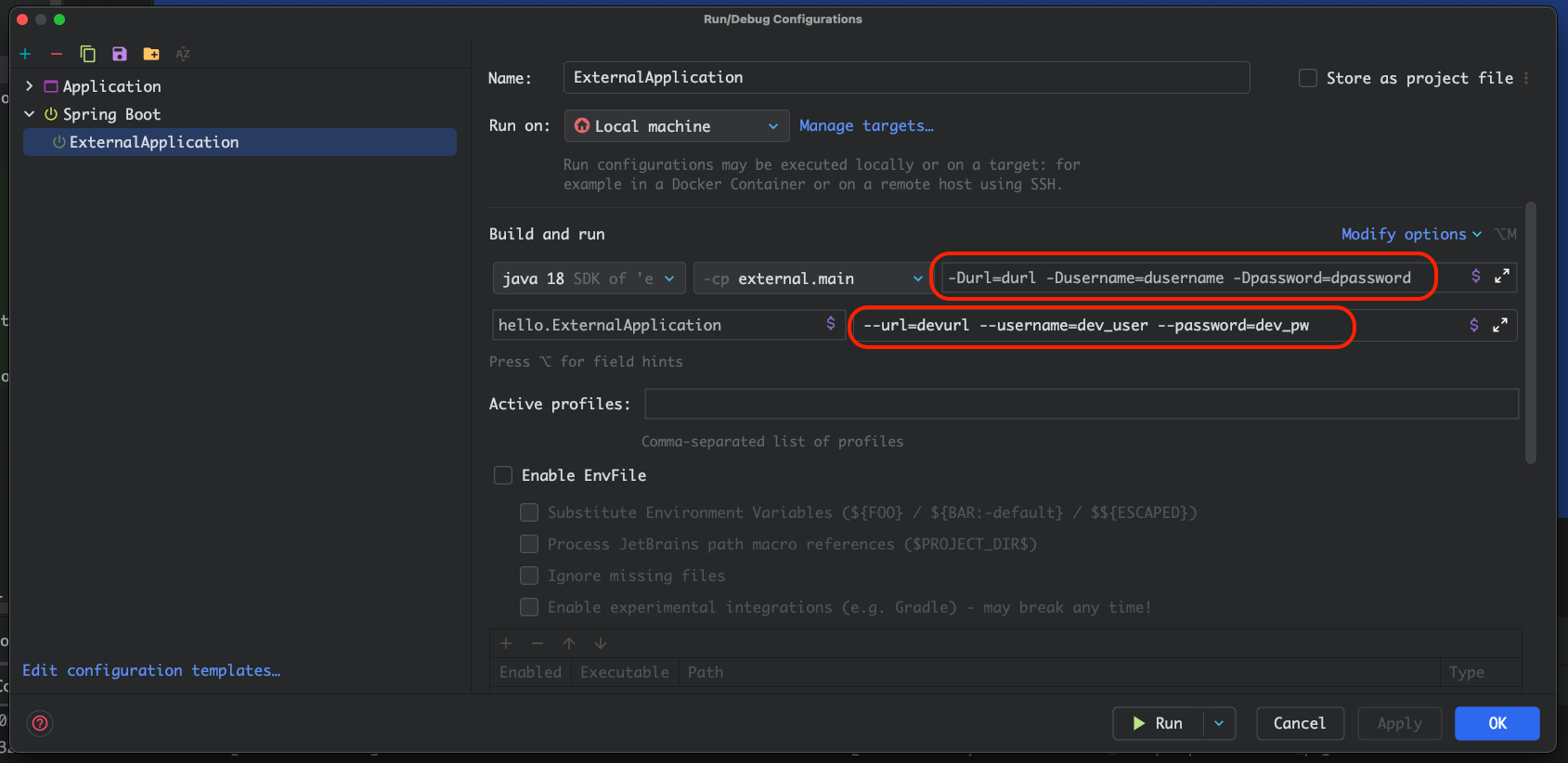
위 코드와 같이 스프링 부트 프로젝트에서 간단한 컨트롤러를 만들었다. 그리고 org.slf4j 패키지에 들어있는 Logger, LoggerFactory를 통해 log 인스턴스를 만들어 낸다. 그리고 log.info()와 같이 찍으면 된다. 그래서 실제로 이 URL로 요청을 날리면 다음과 같이 로그가 찍힌다.
우선 시스템 콘솔에 직접 찍는거보다 훨씬 많은 정보를 보여준다. 시간, 로그레벨, 쓰레드 정보, 패키지+클래스, 로그 내용까지.
근데 로그의 진가는 이것이 아니라 다음과 같은 것이다.
LogTestController
package net.cwchoiit.springmvc.basic;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class LogTestController {
private final Logger log = LoggerFactory.getLogger(LogTestController.class);
@GetMapping("/logging")
public String logging() {
log.trace("trace");
log.debug("debug");
log.info("info");
log.warn("warn");
log.error("error");
return "ok";
}
}
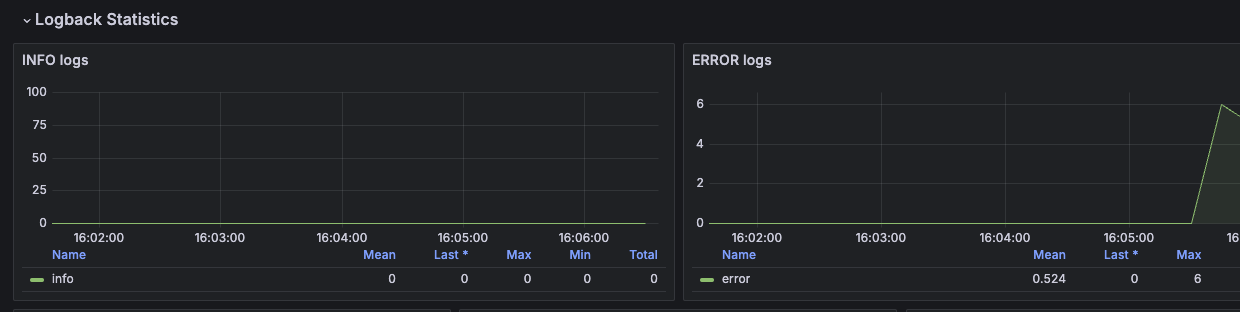
내가 모든 레벨에 대해서 로그를 출력하면 다음과 같은 결과를 얻는다.
어? TRACE, DEBUG 레벨은 안 찍혔다. 이게 로그의 진가이다. 내가 설정한 레벨부터 상위 레벨까지만 로그를 찍어주기 때문에 불필요한 로그를 남기지 않게 된다. 그럼 이 레벨은 어떻게 조정할까?
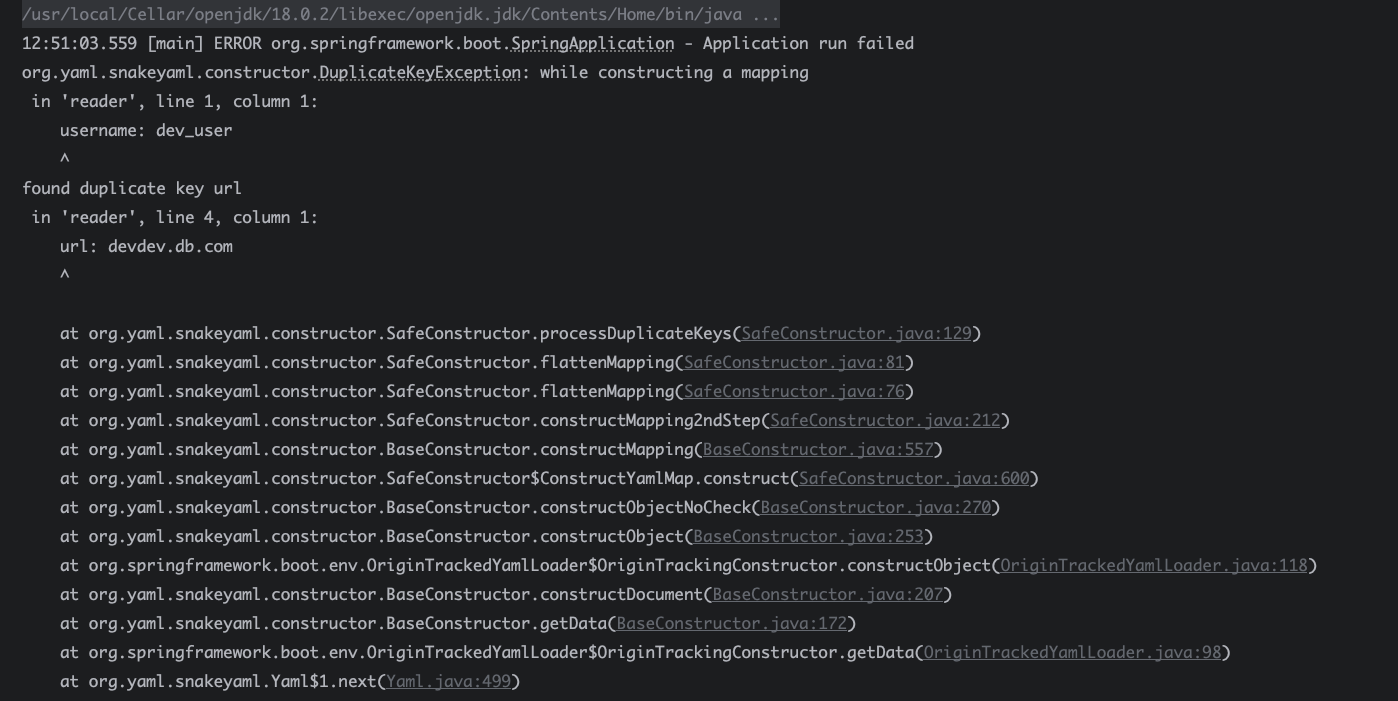
바로, application.yml 파일에서 지정하면 된다.
logging:
level:
net.cwchoiit.springmvc: DEBUG
이렇게 로그 레벨을 패키지별로 지정할 수 있다. 근데 아 이거 귀찮고 나는 모든 패키지가 다 DEBUG 레벨이면 좋겠어! 하면 이렇게 하면 된다.
application.yml
logging:
level:
root: DEBUG
근데 이러면 아예 프로젝트 자체 레벨을 바꾸는 거라 프로젝트 내 모든 라이브러리들 안에 찍은 로그들도 이 레벨에 맞춰 출력되기 때문에 내가 찍지도 않은 여러 로그들이 찍힐건데 여튼 방법은 이렇다. (기본값은 INFO)
참고로 로그 레벨은 다음과 같다.
TRACE
DEBUG
INFO
WARN
ERROR
아래로 내려갈수록 더 심각도가 높은것이고 위처럼 DEBUG로 로그 레벨을 설정하면 DEBUG, INFO, WARN, ERROR 로그가 찍히게 된다. 그래서 운영 시스템에서 만약 TRACE로 로그 레벨을 설정하면 큰일이 난다 큰일이! 로그 폭탄을 맞게 된다. 그래서 레벨을 설정할 수 있는 것이다 환경에 따라.
예를 들면, 로컬 환경은 TRACE로, 개발 서버에선 DEBUG로, 운영 서버에선 INFO로 이렇게 설정해서 각 서버 환경에 맞게 필요한 로그만 찍으면 보기도 좋고, 불필요한 정보도 남지 않고 성능에도 도움이 된다. 근데 System.out.println() 같은 건 그런게 없다. 그래서 사용하면 안된다.
그리고 또 다른 장점은, 이 시스템 콘솔에 직접 출력하는 건 결국 콘솔에만 남기 때문에 보존이 불가능하지만 로그는 원한다면 설정을 통해 파일로 남길수도 있다. 그리고 파일로 남길 때는 일별로 남기는게 가능하고 특정 용량 이상이 되면 로그를 분할 할수도 있기 때문에 장점만 있다.
중요!
로그를 찍을때도 이렇게 찍을 수가 있다.
String name = "cwchoiit";
log.trace("your name = " + name);
절대로 이렇게 찍으면 안된다. 반드시 다음과 같이 찍어야 한다.
String name = "cwchoiit";
log.trace("your name = {}", name);
왜 그럴까? 만약 내가 설정한 로그 레벨이 DEBUG라면, 이 TRACE 레벨의 로그는 출력되지 않을 것이다. 근데 출력을 하지 않는데도 불구하고 + 연산이 실행된다. 즉, 사용도 안 하는데 메모리와 CPU를 사용하게 된다는 것이다. 그리고 저렇게 연산을 하게 되면
"your name = cwchoiit"
라는 문자열이 만들어지는데 이걸 또 가지고 있는다. (물론 이후에 GC에 의해 사용 안되면 정리되긴 한다) 그럼 가지고 있는 동안 또 메모리를 사용하는 것이다. 그래서 절대로 저렇게 사용하면 안된다.
"그럼 이 방식은 메모리와 CPU 안 사용해요?"
String name = "cwchoiit";
log.trace("your name = {}", name);
사용하지 않는다. 왜냐하면, 로그 레벨이 DEBUG이기 때문에 이 log.trace()라는 메서드는 호출되지 않는다. 호출이 안되고 파라미터로 넘기는 코드만 있을 뿐이라서 호출되지 않으면 메모리도 CPU도 사용되지 않기 때문에 아무런 문제가 일어나지 않는다.
이제 Spring MVC는 어떤걸 편리하게 해주고 어떤 효율성이 있는지 하나씩 파악해보자. 우선 그 전에 Welcome 페이지가 하나 있으면 편리할 거 같아서 Welcome 페이지를 만들자. 근데! Welcome 페이지를 만들기 전에 프로젝트가 있어야 한다. 스프링 프로젝트를 만들자.
여기로 가서 스프링 프로젝트를 만들면 된다. Dependencies는 Lombok, Spring Web, Thymeleaf 세 가지를 선택하자.
참고로, src/main/resources/static/index.html 경로에 있는 index.html 파일이 스프링 웹의 기본 Welcome 페이지가 된다.
src/main/resources/static/index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<ul>
<li>로그 출력
<ul>
<li><a href="/log-test">로그 테스트</a></li>
</ul>
</li>
<!-- -->
<li>요청 매핑
<ul>
<li><a href="/hello-basic">hello-basic</a></li>
<li><a href="/mapping-get-v1">HTTP 메서드 매핑</a></li>
<li><a href="/mapping-get-v2">HTTP 메서드 매핑 축약</a></li>
<li><a href="/mapping/userA">경로 변수</a></li>
<li><a href="/mapping/users/userA/orders/100">경로 변수 다중</a></li>
<li><a href="/mapping-param?mode=debug">특정 파라미터 조건 매핑</a></li>
<li><a href="/mapping-header">특정 헤더 조건 매핑(POST MAN 필요)</a></li>
<li><a href="/mapping-consume">미디어 타입 조건 매핑 Content-Type(POST MAN 필요)</a></li>
<li><a href="/mapping-produce">미디어 타입 조건 매핑 Accept(POST MAN 필요)</a></li>
</ul>
</li>
<li>요청 매핑 - API 예시
<ul>
<li>POST MAN 필요</li>
</ul>
</li>
<li>HTTP 요청 기본
<ul>
<li><a href="/headers">기본, 헤더 조회</a></li>
</ul>
</li>
<li>HTTP 요청 파라미터
<ul>
<li><a href="/request-param-v1?username=hello&age=20">요청 파라미터 v1</a></li>
<li><a href="/request-param-v2?username=hello&age=20">요청 파라미터 v2</a></li>
<li><a href="/request-param-v3?username=hello&age=20">요청 파라미터 v3</a></li>
<li><a href="/request-param-v4?username=hello&age=20">요청 파라미터 v4</a></li>
<li><a href="/request-param-required?username=hello&age=20">요청 파라미터 필수</a></li>
<li><a href="/request-param-default?username=hello&age=20">요청 파라미터 기본 값</a></li>
<li><a href="/request-param-map?username=hello&age=20">요청 파라미터 MAP</a></li>
<li><a href="/model-attribute-v1?username=hello&age=20">요청 파라미터 @ModelAttribute v1</a></li>
<li><a href="/model-attribute-v2?username=hello&age=20">요청 파라미터 @ModelAttribute v2</a></li>
</ul>
</li>
<li>HTTP 요청 메시지
<ul>
<li>POST MAN</li>
</ul>
</li>
<li>HTTP 응답 - 정적 리소스, 뷰 템플릿
<ul>
<li><a href="/basic/hello-form.html">정적 리소스</a></li>
<li><a href="/response-view-v1">뷰 템플릿 v1</a></li>
<li><a href="/response-view-v2">뷰 템플릿 v2</a></li>
</ul>
</li>
<li>HTTP 응답 - HTTP API, 메시지 바디에 직접 입력
<ul>
<li><a href="/response-body-string-v1">HTTP API String v1</a></li>
<li><a href="/response-body-string-v2">HTTP API String v2</a></li>
<li><a href="/response-body-string-v3">HTTP API String v3</a></li>
<li><a href="/response-body-json-v1">HTTP API Json v1</a></li>
<li><a href="/response-body-json-v2">HTTP API Json v2</a></li>
</ul>
</li>
</ul>
</body>
</html>
이렇게 파일 하나를 만들어 두고 서버를 재실행한 후 `localhost:8080`으로 접속하면 이 페이지가 보일것이다.
이제 요청 매핑부터 하나하나 살펴보자.
요청 매핑
우선 아주 간단한 요청 매핑 하나를 만들어보자.
MappingController
package net.cwchoiit.springmvc.requestmapping;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@Slf4j
@RestController
public class MappingController {
@RequestMapping("/hello-basic")
public String hello() {
log.debug("hello!");
return "Hello Basic";
}
}
여기서 @RestController는 @Controller랑 무엇이 다르냐? @Controller는 메서드의 반환값이 String이면 해당 값이 뷰의 이름이 된다. 그래서 해당 이름으로 된 뷰를 찾아 뷰가 렌더링된다. 근데 @RestController를 사용하면 반환값으로 뷰를 찾는게 아니라 HTTP 메시지 바디에 바로 입력한다. 따라서 실행 결과로 "Hello Basic"이라는 메시지를 응답으로 받을 수가 있다. 이게 @ResponseBody와 관련이 있는데 뒤에 더 자세히 설명한다.
@RequestMapping("/hello-basic")은 URL이 `/hello-basic`으로 요청이 들어오면 이 메서드가 실행되도록 한다.
참고로, `/hello-basic`과 `/hello-basic/`은 다른 URL이다. 그러므로 당연히 스프링도 서로 다르게 인식한다.
그리고 이렇게 @RequestMapping으로만 해놓으면 GET, POST, PUT, DELETE 다 가능하다. 그래서 이를 딱 지정하기 위해 다음과 같은 애노테이션을 사용할 수 있다.
@GetMapping("/mapping-get-v2")
public String mappingGetV2() {
log.debug("mappingGetV2!");
return "ok";
}
@GetMapping 애노테이션을 사용하면, GET Method만 허용한다.
이렇게 사용하면 되는데 그리고 99%는 이렇게만 사용할텐데 아래같이 사용해도 가능하긴 하다.
URL 형식에 `{userId}` 이렇게 중괄호가 있으면 이게 PathVariable이다. 즉, URL로부터 특정 값을 userId라는 키로 받아온다는 의미가 된다. 그래서 만약 `/mapping/userA` 이렇게 요청했다고 하면 userId는 userA가 된다. 그리고 파라미터 이름이 PathVariable과 같다면 다음과 같이 더 축약할 수 있다.
위 코드를 보면 파라미터에서 굉장히 이것 저것 많이 받을 수 있게 되어 있다. HttpServletRequest, HttpServletResponse, HttpMethod, Locale, @RequestHeader, @RequestHeader("host"), @CookieValue까지.
@RequestHeader로 MultiValueMap으로 가져오는 경우는 헤더 정보 전체를 가져오는 것이다. 근데 왜 MultiValueMap이냐? 그나저나 MultiValueMap은 뭘까? 이건 원래 Map은 키가 유일무이 해야 한다. 근데 헤더는 같은키로 여러 데이터가 들어올 수 있다. 그래서 같은 키라고 할지라도 그 값들 모두 다 가져올 수 있는 방법인 MultiValueMap을 사용한다.
이번엔 HTTP 요청 시 전송하는 쿼리 파라미터, HTML Form으로 전송하는 데이터를 어떻게 받는지 알아볼 차례다.
우선 가장 기본적인 서블릿에서 어떻게 받는지 다시 상기시키자.
RequestParamController
package net.cwchoiit.springmvc.request;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
@Slf4j
@RestController
public class RequestParamController {
@RequestMapping("/request-param-v1")
public void requestParamV1(HttpServletRequest request, HttpServletResponse response) throws IOException {
String username = request.getParameter("username");
int age = Integer.parseInt(request.getParameter("age"));
log.info("username = {}, age = {}", username, age);
response.getWriter().write("ok");
}
}
서블릿은 이렇게 파라미터로 HttpServletRequest, HttpServletResponse 객체를 받을 수 있고, 그 객체를 통해 데이터를 받아올 수 있다. 테스트 해보면 아주 잘 받아온다.
HTTP 요청 - 쿼리 파라미터받은 데이터 로그로 찍은 결과
근데 이렇게 전송할 때 전달하는 데이터의 생김새가 HTML Form이나 쿼리 파라미터나 동일하다.
`username=cwchoi&age=10`둘 다 이렇게 들어오기 때문에 동일한 방식으로 데이터를 받을 수가 있다.
실제로 그런지 HTML Form을 만들어보자. 간단하게 `src/main/resources/static`이 경로에 만들자. 이 경로는 스프링 부트는 기본이 다 외부로 내보내게 되어 있는 파일들만 모아놓은 곳이기 때문에 그냥 여기에 파일을 만들면 기본적으로 외부에서 접근이 가능하다.
원하는 쿼리 파라미터 또는 HTML Form 데이터의 키를 @RequestParam("") 안에 적는다. 그럼 그 값을 찾아서 변수에 넣어준다.
근데, 만약 변수명과 쿼리 파라미터의 키가 같은 이름으로 된다면 생략 가능하다. 다음 코드처럼.
@ResponseBody
@RequestMapping("/request-param-v3")
public String requestParamV3(@RequestParam String username,
@RequestParam int age) {
log.info("V3 username = {}, age = {}", username, age);
return "ok";
}
둘 다 아주 잘 받아온다. 그나저나, 저 @ResponseBody 애노테이션은 뭐냐면 만약 클래스 레벨에 @RestController가 아니라 @Controller라면 메서드가 String 타입으로 반환하는 메서드일때 기본적으로 뷰의 이름으로 판단하고 뷰를 찾는다.
그래서 스프링한테 알려주는 것이다. "이건 뷰의 이름이 아니라 너가 응답 메시지로 반환할 값이야!"라고.
근데 귀찮게 애노테이션을 하나 더 붙이기가 싫다면 그냥 @RestController를 사용하면 된다.
다시 돌아와서, 사람의 욕심은 끝이 없어서 @RequestParam 마저도 생략할 수 있다. 다음 코드처럼.
@ResponseBody
@RequestMapping("/request-param-v4")
public String requestParamV4(String username, int age) {
log.info("V4 username = {}, age = {}", username, age);
return "ok";
}
물론 이 경우도 당연히 파라미터 이름과 쿼리 파라미터의 키가 동일한 이름이어야 한다.
근데, 나는 @RequestParam 애노테이션을 붙이는 걸 선호한다. 그래야 한 눈에 바로 파악이 쉽기 때문에.
그런데 이 쿼리 파라미터는 기본적으로 무조건 있어야 동작한다. 요청하는 쪽에서 보내지 않으면 에러 화면이 보일것이다. 근데 이 필수라는 옵션을 변경할 수도 있다.
@ResponseBody
@RequestMapping("/request-param-required")
public String requestParamRequired(@RequestParam(required = false) String username,
@RequestParam(required = false) int age) {
log.info("Required username = {}, age = {}", username, age);
return "ok";
}
이 코드처럼 "required = false"를 주게 되면 이 쿼리 파라미터를 요청 시 던지지 않아도 동작한다. 근데 주의할 점이 있다. `age`와 같이 Primitive Type인 경우 `null`이라는 값을 받을 수 없기 때문에 쿼리 파라미터를 주지 않으면 에러가 발생한다. 그래서 `age`가 필수값이 아니고 싶다면 Integer로 받아야 한다. 아래처럼.
뭐 파라미터 하나하나 다 나열하기 귀찮다하면 이렇게 Map으로 받아오면 된다. 근데 난 개인적으로 좋아하지 않는다.
그리고 더 나아가서 MultiValueMap도 사용할 수 있다. 만약, 쿼리 파라미터의 키가 같은데 값이 여러개가 들어갈 수 있는 경우 MultiValueMap을 사용해야 한다. 이런 URL : `/request-param-map?userId=1&userId=2` 근데 이런 경우는 거의 없다.
이런식으로 요청 시 쿼리 파라미터와 HTML Form 데이터를 간단하게 받아올 수 있다. (아직 바디에 JSON으로 데이터 보내는 경우는 어떤식으로 처리하는지 작성 안했다) 그럼 이렇게 받아온 데이터를 실제 업무에서는 당연히 객체로 변환하고 사용할 것이다 일반적으로. 그런 경우에 어떻게 하면 될까? 스프링이 이것도 간단하게 도와준다.
HTTP 요청 파라미터 - @ModelAttribute
실제 개발을 하면 요청 파라미터를 받아서 필요한 객체를 만들고 그 객체에 값을 넣어주어야 한다. 우선 DTO를 먼저 만들어보고 말해보자.
HelloData
package net.cwchoiit.springmvc.basic;
import lombok.*;
@Data
@AllArgsConstructor
public class HelloData {
private String username;
private int age;
}
가장 단순하고 원초적인 방법은 이렇게 사용할 것이다.
@ResponseBody
@RequestMapping("/model-attribute-v1")
public String modelAttributeV1(@RequestParam String username, @RequestParam int age) {
HelloData helloData = new HelloData(username, age);
log.info("helloData = {}", helloData);
return "ok";
}
그럼 헷갈릴 수 있다. 어떤게 @RequestParam을 생략한거고 어떤게 @ModelAttribute를 생략한 것인지. 스프링은 Primitive Type, Primitive Type의 Wrapper(String, Integer, ..) 클래스를 파라미터로 받을땐 @RequestParam을 생략한다고 간주한다. 그리고 직접 만든 객체처럼 HelloData이런 것들을 @ModelAttribute로 간주한다.
주의할 점은, 요청에서 파라미터를 받았을 때 파라미터가 username, age라면 이 프로퍼티의 Setter를 먼저 찾는다. 만약 Setter가 없다면 final필드로 된 전체 파라미터를 받는 생성자를 찾는다. 이 두가지가 다 없으면 바인딩 되지 않는다.
또한, 위에서 말한것처럼 HelloData와 같은 직접 만든 객체를 @ModelAttribute로 간주한다 했는데 여기서 Argument Resolver는 제외이다. Argument Resolver라는 건 예를 들어 HttpServletRequest, HttpServletResponse 이런것들을 말한다.
지금까지는 요청 파라미터를 받는 방법에 대해 알아보았다. 이제 파라미터가 아니라 메시지(요청 바디에 넣는 데이터)는 어떻게 처리하는지 알아보자.
HTTP 요청 메시지
메시지는 크게 세 가지로 받을 수 있다.
단순 텍스트
JSON
XML
XML은 요즘은 거의 사용하는 추세가 아니기 때문에 따로 다루지 않는다. 그럼 요청 시 바디에 단순 텍스트 또는 JSON을 던져서 보낼 때 어떻게 받는지 하나씩 알아보자.
HttpServletRequest, HttpServletResponse 객체를 파라미터로 받아서, InputStream을 얻어온다. 그리고 그 안에 있는 데이터를 String으로 받아오면 끝난다. 근데 스프링이 파라미터로 받을 수 있는 것들 중에 InputStream과 Writer가 있다. 굳이 HttpServletRequest, HttpServletResponse 전체를 다 받을 필요 없이 딱 필요한것만 받는 방법이 된다.
근데 당연히 여기서 끝날 스프링이 아니다. 그냥 이 과정 자체를 아예 자동화 해준다. 그래서 무엇을 받을 수 있냐? 다음과 같이 HttpEntity를 받을 수 있다.
@PostMapping("/request-body-string-v3")
public HttpEntity<String> requestBodyStringV3(HttpEntity<String> httpEntity) {
String body = httpEntity.getBody();
log.info("body: {}", body);
return new HttpEntity<>("ok");
}
내가 HttpEntity<String> 이라고 선언을 하면 자동으로 바디에 있는 값을 String으로 변환해서 넣어준다.
그리고 반환도 마찬가지로 HttpEntity<String>이라고 반환을 하면 응답 메시지에 내가 넣을 데이터를 문자열로 받아 반환해준다.
그리고 이 HttpEntity를 상속받는 좀 더 구체적인 객체가 있다. 바로 RequestEntity, ResponseEntity
@PostMapping("/request-body-string-v3-2")
public ResponseEntity<String> requestBodyStringV3_2(RequestEntity<String> requestEntity) {
String body = requestEntity.getBody();
log.info("body: {}", body);
return new ResponseEntity<>("ok", HttpStatus.CREATED);
}
ResponseEntity는 이렇게 상태 코드도 넣어줄 수 있다.
그러나, 애노테이션 기반이 대세로 자리잡은 지금 당연히 이것도 애노테이션이 있다.
@PostMapping("/request-body-string-v4")
public ResponseEntity<String> requestBodyStringV4(@RequestBody String messageBody) {
log.info("body: {}", messageBody);
return new ResponseEntity<>("ok", HttpStatus.CREATED);
}
이렇게 @RequestBody라고 해주면 끝난다. 알아서 요청 바디의 데이터를 내가 선언한 타입(String)으로 변환해서 넣어준다.
이 방식이 가장 많이 사용되고 실제로 편리한 방식이다.
참고로 @RequestBody는 @RequestParam, @ModelAttribute와는 아무런 관련이 없다. @RequestParam, @ModelAttribute는 요청 파라미터를 받아오는 방법들 중 하나이다. 반면, @RequestBody 요청 바디를 받아오는 방법이다. 절대 구분!
이렇게 요청 바디의 단순 메시지를 받아오는 방법을 알아봤다. 거의 95%는 JSON으로 데이터를 주고 받는다. 그래서 이제 알아볼 JSON을 받아오는 방법에 집중해보자!
우선 단순 텍스트를 어떤 특정 객체로 변환하기 위해 사용되는 라이브러리인 ObjectMapper를 새로 만들자. 당연히 이 ObjectMapper는 실제 개발에서는 여러 설정이 곁들어진 상태로 빈으로 등록해서 여기저기서 주입되는 방식으로 사용될테지만 지금은 그런 경우는 아니니까.
그리고 서블릿에서 했던것처럼 HttpServletRequest, HttpServletResponse 객체를 받아서 InputStream을 가져와서 스트링으로 변환한다. 그리고 변환된 문자열을 ObjectMapper를 통해 객체로 변환한다.
그 다음은 @RequestBody 애노테이션을 사용해서 좀 더 편리하게 문자열로 가져오는 방법이다.
이게 이제 가장 최신 방식이고 편리한 방식이다. 그리고 주의할점은 이 @RequestBody를 통해서 요청 바디의 데이터를 특정 객체로 변환할 때는 @RequestBody를 생략할 수 없다! 왜냐하면 이미 @ModelAttribute에서 생략 가능하기 때문에 @RequestBody를 생략해버리면 @ModelAttribute처럼 동작하게 된다. 즉, 파라미터에서 데이터를 찾게 된다는 말이다. 그래서 안된다!
참고로, 이렇게 @RequestBody 애노테이션으로 JSON을 특정 객체로 변환해 주려면 반드시 요청 헤더에 Content-Type이 `application/json`이어야 한다. 이래야만 이후에 다룰 HTTP 메시지 컨버터가 "아 이 값이 지금 JSON이고 이런 객체로 변환하길 원하는구나!?"로 이해하고 바꿔주기 때문이다.
그리고 HttpEntity로도 받을 수 있다. 단순 텍스트가 가능했듯 이 특정 객체도 HttpEntity를 사용해 받아올 수 있다.
@ResponseBody
@PostMapping("/request-body-json-v2-1")
public String requestBodyJsonV2_1(HttpEntity<HelloData> httpEntity) {
HelloData body = httpEntity.getBody();
log.info("helloData: {}", body);
return "ok";
}
근데 그러려면 이렇게 getBody()를 호출해야 하는 번거로움 때문에 거의 사용하지 않는다.
그래서 요청 바디에 JSON을 태울 때 어떻게 받아오는지도 알아보았다. 결국 단순 텍스트든 JSON이든 @RequestBody를 통해 깔끔하고 쉽게 받아올 수가 있다. 이제 요청 관련 처리를 쭉 알아봤으니 응답 관련 처리를 쭉 알아보자!
HTTP 응답 - 정적 리소스, 뷰 템플릿
스프링에서 응답 데이터를 만드는 방법은 크게 세가지이다.
정적 리소스 예) 웹 브라우저에 정적인 HTML, CSS, JS를 제공할 때는 정적 리소스를 사용한다.
뷰 템플릿 예) 웹 브라우저에 동적인 HTML을 제공할 때는 뷰 템플릿을 사용한다.
HTTP 메시지 예) HTTP API를 제공하는 경우에는 HTML이 아니라 데이터를 전달해야 하므로, HTTP 메시지 바디에 JSON과 같은 형식으로 데이터를 실어 보낸다
물론 실제로 이 파일을 열었을 때 저 두줄이 보이는게 아니라 자동으로 등록해준다는 의미이다. 그리고 저 값을 변경하고 싶을때만 이 파일을 수정하면 된다. 여기서 `classpath`는 `src/main/resources`를 말한다.
아마 Thymeleaf와 스프링 부트를 사용하는 것은 이후에도 해 볼 것이기 때문에 이 정도로만 하고 가장 중요한(?) HTTP API에 대한 응답 처리를 알아보자!
HTTP 응답 - HTTP API
HTTP API를 제공하는 경우에는 HTML이 아니라 데이터를 전달해야 하므로, HTTP 메시지 바디에 JSON과 같은 형식으로 데이터를 실어 보낸다.
참고로, HTML이나 뷰 템플릿을 사용해도 HTTP 응답 메시지 바디에 HTML 데이터가 담겨서 전달된다. 여기서 설명하는 내용은 정적 리소스나 뷰 템플릿을 거치지 않고, 직접 HTTP 응답 메시지를 전달하는 경우를 말한다.
말로 장황하게 설명할 것 없이 바로 코드로 들어가자.
ResponseBodyController
package net.cwchoiit.springmvc.response;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import lombok.extern.slf4j.Slf4j;
import net.cwchoiit.springmvc.basic.HelloData;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.ResponseStatus;
import java.io.IOException;
@Slf4j
@Controller
public class ResponseBodyController {
@GetMapping("/response-body-string-v1")
public void responseBodyStringV1(HttpServletRequest req, HttpServletResponse resp) throws IOException {
resp.getWriter().write("ok");
}
@GetMapping("/response-body-string-v2")
public ResponseEntity<String> responseBodyStringV2() {
return new ResponseEntity<>("ok", HttpStatus.OK);
}
@ResponseBody
@GetMapping("/response-body-string-v3")
public String responseBodyStringV3() {
return "ok";
}
@GetMapping("/response-body-json-v1")
public ResponseEntity<HelloData> responseBodyJsonV1() {
HelloData helloData = new HelloData();
helloData.setUsername("A");
helloData.setAge(30);
return new ResponseEntity<>(helloData, HttpStatus.OK);
}
@ResponseStatus(HttpStatus.OK)
@ResponseBody
@GetMapping("/response-body-json-v2")
public HelloData responseBodyJsonV2() {
HelloData helloData = new HelloData();
helloData.setUsername("B");
helloData.setAge(30);
return helloData;
}
}
단순 스트링의 경우
첫번째 메서드의 경우, 간단하게 서블릿 방식을 사용해서 파라미터로 들어온 HttpServletResponse 객체의 Writer를 사용해서 응답 메시지를 보낸다.
두번째 메서드의 경우, ResponseEntity를 반환타입으로 주면 알아서 HTTP 응답 바디에 메시지를 넣어 보내고 상태 코드도 설정할 수 있다.
세번째 메서드의 경우, 그냥 단순 String을 반환하는 경우 뷰 논리 이름이 기본이지만 @ResponseBody 애노테이션이 붙었기 때문에 반환값 자체가 응답 바디에 넣어지는 값이 된다.
JSON의 경우
네번째 메서드의 경우, 반환값으로 ResponseEntity<HelloData>로 지정했다. 이 말은 응답 메시지에 HelloData 타입의 데이터를 실어 내보내겠다는 의미가 되고 상태 코드도 지정할 수 있게 된다.
다섯번째 메서드의 경우, 반환값이 HelloData이다. 이 경우도 이 HelloData 객체가 응답 메시지에 들어간다. 그러나 이 경우 상태 코드를 지정하지 못하기 때문에 @ResponseStatus(HttpStatus.OK) 애노테이션을 사용해서 상태코드를 추가해준다.
근데 이렇게 계속 @ResponseBody 애노테이션을 붙이기가 상당히 귀찮다. 그리고 실제로 개발을 해보면 이렇게 사용하지도 않는다.
이 @ResponseBody + @Controller가 합쳐진 애노테이션이 바로 @RestController이다.
그래서 @RestController가 클래스 레벨에 붙고, 단순 String을 반환하는 메서드가 있다면 이 메서드는 무조건 응답 바디에 반환값을 넣는다는 의미다. 뷰를 찾는게 아니라.
ResponseBodyController - @RestController 사용
package net.cwchoiit.springmvc.response;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import lombok.extern.slf4j.Slf4j;
import net.cwchoiit.springmvc.basic.HelloData;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.ResponseStatus;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
@Slf4j
@RestController
public class ResponseBodyController {
@GetMapping("/response-body-string-v1")
public void responseBodyStringV1(HttpServletRequest req, HttpServletResponse resp) throws IOException {
resp.getWriter().write("ok");
}
@GetMapping("/response-body-string-v2")
public ResponseEntity<String> responseBodyStringV2() {
return new ResponseEntity<>("ok", HttpStatus.OK);
}
@GetMapping("/response-body-string-v3")
public String responseBodyStringV3() {
return "ok";
}
@GetMapping("/response-body-json-v1")
public ResponseEntity<HelloData> responseBodyJsonV1() {
HelloData helloData = new HelloData();
helloData.setUsername("A");
helloData.setAge(30);
return new ResponseEntity<>(helloData, HttpStatus.OK);
}
@ResponseStatus(HttpStatus.OK)
@GetMapping("/response-body-json-v2")
public HelloData responseBodyJsonV2() {
HelloData helloData = new HelloData();
helloData.setUsername("B");
helloData.setAge(30);
return helloData;
}
}
HTTP 메시지 컨버터
이제 HTML을 생성해서 응답하는게 아니라 HTTP API처럼 JSON 데이터를 HTTP 메시지 바디에서 직접 읽거나 쓰는 경우 그래서 그것을 반환할 때 HTTP 메시지 컨버터를 사용하면 편리하다. 원래는 어떻게 했나? 원래는 서블릿 방식으로 HttpServletResponse 객체를 받아와서 response.getWriter().write("OK"); 이런식으로 Writer를 가져왔었다. 이건 쓰기 방식이고 읽을땐? HttpServletRequest 객체를 받아와서 InputStream을 받아와서 데이터를 읽어왔다. 매우매우 불편하다.
스프링 부트는 다양한 메시지 컨버터를 제공하는데, 대상 클래스 타입과 미디어 타입 둘을 체크해서 사용여부를 결정한다. 만약 만족하지 않으면 다음 메시지 컨버터로 우선순위가 넘어간다.
몇가지 주요한 메시지 컨버터를 알아보자.
ByteArrayHttpMessageConverter: byte[]데이터를 처리한다.
클래스 타입: byte[], 미디어타입: */*
요청 예) @RequestBody byte[] data
응답 예) @ResponseBody, return byte[]; 쓰기 미디어 타입 application/octet-stream
StringHttpMessageConverter: String 문자로 데이터를 처리한다.
클래스 타입: String, 미디어타입: */*
요청 예) @RequestBody String data
응답 예) @ResponseBody, return "ok"; 쓰기 미디어 타입 text/plain
MappingJackson2HttpMessageConverter: JSON 관련 데이터 처리
클래스 타입: 객체 또는 HashMap, 미디어 타입: application/json
요청 예) @RequestBody HelloData data
응답 예) @ResponseBody, return data; 쓰기 미디어타입: application/json
그러니까, 쉽게 생각해서 이전에 요청 바디의 메시지를 가져올땐 HttpServletRequest 객체를 파라미터로 받아서 객체의 InputStream을 가져왔다. InputStream으로부터 데이터를 꺼내오는 작업을 했었는데 이 작업의 자동화를 해준 애노테이션이 @RequestBody 애노테이션이었다. 그럼 이 @RequestBody 애노테이션이 어떻게 이 작업을 해주는 것인가?에 대한 비밀이 이 HttpMessageConverter가 되는것이다.
첫번째로, ByteArrayHttpMessageConverter에게 읽을 수 있는 데이터인지 물어본다. (canRead())
ByteArrayHttpMessageConverter 이 녀석은 클래스 타입이 byte[]여야 하고, 미디어 타입은 */*여야 한다. 클래스 타입이 HelloData이기 때문에 넘어가게 된다.
두번째로, StringHttpMessageConverter에게 읽을 수 있는 데이터인지 물어본다. (canRead())
StringHttpMessageConverter 이 녀석은 클래스 타입이 String 이어야 하고 미디어 타입은 */*여야 한다. 클래스 타입이 HelloData이기 때문에 넘어가게 된다.
세번째로, MappingJackson2HttpMessageConverter에게 읽을 수 있는 데이터인지 물어본다. (canRead())
MappingJackson2HttpMessageConverter 이 녀석은 클래스 타입이 객체 또는 HashMap 이어야 하고, 미디어 타입이 application/json이어야 한다. 우선, HelloData는 객체라서 조건을 만족하고, 요청 시 Content-Type을 application/json으로 보냈기 때문에 미디어타입도 만족한다. 그럼 이 MappingJackson2HttpMessageConverter 녀석이 이 데이터를 가지고 HelloData 객체의 각 프로퍼티에 데이터를 바인딩 해주게 된다. 이게 바로 HTTP 메시지 컨버터가 하는 일이다.
요청과 일치하게 응답도 동일하다. 만약 다음 코드가 있다고 했을 때,
@ResponseStatus(HttpStatus.OK)
@GetMapping("/response-body-json-v2")
public HelloData responseBodyJsonV2() {
HelloData helloData = new HelloData();
helloData.setUsername("B");
helloData.setAge(30);
return helloData;
}
반환값이 HelloData로 되어 있다. 그리고 이 메서드를 가진 클래스는 @RestController 애노테이션을 달았다. 그럼 메시지 컨버터가 동작하고, 클래스 타입이 HelloData라는 객체이고 미디어 타입은 요청 시 Accept를 application/json으로 던졌다고 가정하면 클래스 타입과 미디어 타입을 모두 만족하는 MappingJackson2HttpMessageConverter녀석이 동작하여 응답 시 알아서 잘 해주게 되는 것이다. 참고로 여기서 컨버터들에게 너 이거 쓸 수 있어? 라고 물어보는 메서드는 canWrite() 메서드가 되겠지!
MappingJackson2HttpMessageConverter 이 녀석 내부적으로 Writer를 가져와서 write()를 하겠지만 우리가 직접 하지 않아도 되니 얼마나 편한가?
그럼 HTTPMessageConverter가 뭐하는건지 이해를 했다. 그럼 스프링 MVC의 어디쯤에 존재하고 사용되는 것일까?
요청 매핑 핸들러 어댑터(RequestMappingHandlerAdapter) 구조
그래서 다시 위의 원초적인 질문으로 돌아와서 그렇다면 HTTP 메시지 컨버터는 스프링 MVC 어디쯤에서 사용되는 것일까?
이전에 봤던 이 그림을 다시 보자.
이 그림에서 HTTP 메시지 컨버터는 보이지 않는다. 그럼 어디에?
애노테이션 기반의 컨트롤러, 그러니까 @RequestMapping을 처리하는 핸들러 어댑터인 RequestMappingHandlerAdapter(요청 매핑 핸들러 어댑터)에 있다.
한번 이 핸들러 어댑터의 동작 방식을 다시 한번 상기해보자.
1. 외부로부터 요청이 들어온다.
2. 이 요청과 매핑된 핸들러(컨트롤러)를 찾는다.
3. 찾은 핸들러를 처리할 수 있는 핸들러 어댑터를 찾는다
4. 찾은 핸들러 어댑터는 RequestMappingHandlerAdapter가 된다. 이 핸들러 어댑터가 본인이 가지고 있는 handle()을 호출해서 실제로 핸들러가 실행된다.
5. 실행된 핸들러의 결과를 반환 받은 핸들러 어댑터는 뷰를 반환해야 하면 뷰 리졸버를 호출하고, 그대로 응답 메시지에 반환해야 하면 그 작업을 또 하게 된다.
저기서 4번이 중요하다. 생각해보면 컨트롤러에 엄청 많은 Arguments를 받을 수 있었다. 대표적인 예로,
HttpServletRequest, HttpServletResponse
@ModelAttribute
Model
@RequestParam
@RequestBody
등등
그럼 결국 이 arguments들에 실제 어떤 값이 담겨서 컨트롤러를 호출하는 handle()을 호출해야 한다. 그 값들이 채워지는 시점은 바로 4번이다. 그래서 다음 그림을 보자.
핸들러 어댑터가 필요한 Arguments들을 보고 이 Arguments들을 처리할 수 있는 ArgumentResolver를 호출한다.
호출해서 "너가 이 Argument 처리할 수 있어?"라고 물어보고 처리할 수 있는 녀석이 해당 Argument를 처리해서 실제 값을 담아주게 된다. 값을 그렇게 하나씩 차곡차곡 담아서 핸들러 어댑터가 모든 Arguments들이 완성이 되면 그제서야 핸들러를 호출하게 되는것이다.
참고로, ArgumentResolver의 정확한 명칭은 HandlerMethodArgumentResolver이고, 생김새는 이렇게 생겼다.
HandlerMethodArgumentResolver
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.springframework.web.method.support;
import org.springframework.core.MethodParameter;
import org.springframework.lang.Nullable;
import org.springframework.web.bind.support.WebDataBinderFactory;
import org.springframework.web.context.request.NativeWebRequest;
public interface HandlerMethodArgumentResolver {
boolean supportsParameter(MethodParameter parameter);
@Nullable
Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer, NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception;
}
그래서 딱 봐도 supportsParameter()를 호출해서 이 Argument를 처리할 수 있는 구현체를 찾을 것이다. 참고로 구현체 겁나 많다..
그래서 찾았다면 resolveArgument를 호출해서 실제 값을 객체에 차곡차곡 담아준다.
그리고 이렇게 다 생성된 객체를 핸들러 어댑터가 받아서 실제 핸들러를 호출하게 되는것이다.
그리고 스프링은 이렇게 모든게 인터페이스 - 구현체 구조로 되어 있기 때문에 확장에 너무나 용이하다. OCP 원칙을 고수하고 있다는 의미이고 새로운 기술을 도입해도 클라이언트 코드는 변경에 영향을 받지 않는다. 그리고 그 말은! 내가 원하는 나만의 Argument를 받을 수 있게 나만의 ArgumentResolver를 만들수도 있다는 얘기다.
"아니 그래서 HTTP 메시지 컨버터는 어디 있는데요!?"
맞다. 아직도 그래서 이 HTTP 메시지 컨버터의 비밀을 밝혀지지 않았다. 이 메시지 컨버터가 사용되는 지점은 바로 ArgumentResolver가 사용한다. 당연히 그렇겠지? 왜냐하면 @RequestBody는 파라미터로 들어오니까 그 파라미터를 처리할 수 있는 ArgumentResolver가 있고 거기서 사용될것이다. 다음 그림을 보자.
저렇게 ArgumentResolver가 HTTP 메시지 컨버터를 사용한다. 그리고 핸들러가 결국 응답을 하게 되는데 그 응답도 또한 인터페이스 - 구현체 구조로 되어 있다. 그 때 인터페이스는 ReturnValueHandler라는 녀석인데 뷰를 다루는 핸들러가 아니라 응답 데이터를 HTTP 메시지에 입력해야 하는 핸들러는 이 인터페이스를 구현한 구현체를 핸들러 어댑터에게 응답한다. 그리고 이 ReturnValueHandler가 또 HTTP 메시지 컨버터를 사용한다. HTTP 메시지 컨버터는 요청과 응답 둘 다 사용된다고 말했던 바 있다.
좀 더 깊이 들어가보자.
ArgumentResolver는 요청의 경우, @RequestBody를 처리하는 ArgumentResolver가 있고 HttpEnttiy를 처리하는 ArgumentResolver가 있다. (파라미터로 @RequestBody, HttpEntity를 둘 다 받을 수 있었다. 기억해보자!) 그래서 둘 중에 어떤게 사용됐는지 확인하여 적절한 ArgumentResolver가 선택되면 거기서 HTTP 메시지 컨버터가 실행된다.
응답의 경우도 동일하게 @ResponseBody와 HttpEntity를 처리하는 ReturnValueHandler가 있다. 그리고 이 ReturnValueHandler 녀석이 HTTP 메시지 컨버터를 사용하는 것이다.
그래서 정말 신기하고 새로웠던 @RequestBody로 데이터를 자동으로 바인딩 해주고 @ResponseBody로 반환값을 자동으로 반환해주는 비밀의 열쇠인 HttpMessageConverter에 대해 알아봤다.
결론
여기까지 하면 스프링 MVC의 핵심 구조들은 다 이해해 본 것이다. 이젠 이걸 활용하고 사용하는 것만이 남았다.
스프링이 제공하는 컨트롤러는 애노테이션 기반으로 동작한다. 그래서 매우 유연하고 실용적이다.
@RequestMapping
이 애노테이션이 바로 스프링이 사용하는 애노테이션 기반 컨트롤러이다. 이 애노테이션을 기반으로 핸들러 매핑과 핸들러 어댑터가 존재한다. 핸들러 매핑과 핸들러 어댑터가 뭔지 모른다면 이전 포스팅을 꼭 읽고 오길 바란다. 핸들러 매핑을 통해 URL과 매핑된 컨트롤러를 찾고 그 컨트롤러를 처리할 수 있는 핸들러 어댑터를 찾아내는게 핸들러 어댑터이다. 그게 스프링은 굉장히 여러 형태의 구현체로 존재하는데 이 애노테이션 기반은 다음 두 개이다.
RequestMappingHandlerMapping
RequestMappingHandlerAdapter
가장 우선순위가 높은 핸들러 매핑과 핸들러 어댑터이다. 애노테이션의 이름을 따서 만든 이름이다.
지금까지 쭉 만들어왔던 스프링 MVC 구조를 이해하기 위해서 작업했던 것들을 스프링 MVC로 바꿔보자.
참고로, 이 글은 이전 포스팅을 의존하기 때문에 이전 포스팅을 읽지 않았다면 먼저 읽고 오는 것을 권장한다.
package org.example.servlet.web.springmvc.v1;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.servlet.ModelAndView;
@Controller
public class SpringMemberFormControllerV1 {
@RequestMapping("/springmvc/v1/members/new-form")
public ModelAndView process() {
return new ModelAndView("new-form");
}
}
클래스 레벨에 @Controller 애노테이션이 붙었다. 이건 뭘까? 스프링이 자동으로 스프링 빈으로 등록하게 해주는 애노테이션이다. 저 애노테이션 내부에 @Component 애노테이션이 있어서 컴포넌트 스캔의 대상이 된다. 또한, 스프링 MVC에서 애노테이션 기반 컨트롤러로 인식한다. 그래서 @Controller 하나만 있어도 스프링 빈으로 자동 등록해주고 스프링 MVC에서 애노테이션 기반 컨트롤러로 인식하게 된다. @RequestMapping은 요청 정보를 매핑한다. 해당 URL이 호출되면 이 메서드가 호출된다.
RequestMappingHandlerMapping은 스프링 빈 중에서 @RequestMapping 또는 @Controller가 클래스 레벨에 붙어 있는 경우에 매핑 정보로 인식한다. 그래서 다음과 같은 코드도 동일하게 동작한다.
package org.example.servlet.web.springmvc.v1;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.servlet.ModelAndView;
@Component
@RequestMapping
public class SpringMemberFormControllerV1 {
@RequestMapping("/springmvc/v1/members/new-form")
public ModelAndView process() {
return new ModelAndView("new-form");
}
}
또는 컴포넌트 자동 스캔을 사용하지 않고 직접 빈으로 등록한다면 이런 코드도 가능하다.
package org.example.servlet.web.springmvc.v1;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.servlet.ModelAndView;
@RequestMapping
public class SpringMemberFormControllerV1 {
@RequestMapping("/springmvc/v1/members/new-form")
public ModelAndView process() {
return new ModelAndView("new-form");
}
}
근데 굳이 그럴 필요없이 @Controller를 사용한다면 모든게 충족된다.
주의! 스프링 부트 3.0이상부터는 클래스 레벨에 @RequestMapping이 있어도 스프링 컨트롤러로 인식하지 않는다. 오직 @Controller가 있어야 스프링 컨트롤러로 인식한다. 참고로 @RestController는 해당 애노테이션 내부에 @Controller가 있으므로 인식이 된다. 따라서 위에 설명한 두개의 코드는 이제 스프링 컨트롤러로 인식되지 않는다. RequestMappingHandlerMapping이 이제 @Controller만 인식을 한다.
SpringMemberListControllerV1
package org.example.servlet.web.springmvc.v1;
import org.example.servlet.domain.member.Member;
import org.example.servlet.domain.member.MemberRepository;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.servlet.ModelAndView;
import java.util.List;
@Controller
public class SpringMemberListControllerV1 {
private final MemberRepository memberRepository = MemberRepository.getInstance();
@RequestMapping("/springmvc/v1/members")
public ModelAndView process() {
List<Member> members = memberRepository.findAll();
ModelAndView mv = new ModelAndView("members");
mv.addObject("members", members);
return mv;
}
}
모두 반환타입이 ModelAndView 타입이다. 이는 이 컨트롤러는 어떤 특정 뷰를 보여줄것을 의미한다. 그리고 반드시 그 뷰의 이름을 넣어주게 되어 있고 필요하다면 해당 뷰에서 사용할 데이터를 ModelAndView의 Model에 담는다. 담을땐 mv.addObject("key", "value")로 넣으면 된다. 그리고 이 ModelAndView를 반환하면 끝이다.
근데, 지금 코드는 불편한 부분이 있다. 이 세개의 컨트롤러가 모두 나뉘어져 있는것이 상당히 불편하고 번잡하다. 하나로 합칠 수 있다. 그것을 해보자. 그리고 사실 이전 포스팅에서 배웠지만 단순 문자열만 반환해도 뷰를 보여줄 수 있었다. 그것 또한 차근차근 알아보자.
SpringMemberControllerV2
package org.example.servlet.web.springmvc.v2;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.example.servlet.domain.member.Member;
import org.example.servlet.domain.member.MemberRepository;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.servlet.ModelAndView;
import java.util.List;
@Controller
public class SpringMemberControllerV2 {
private final MemberRepository memberRepository = MemberRepository.getInstance();
@RequestMapping("/springmvc/v2/members/new-form")
public ModelAndView newForm() {
return new ModelAndView("new-form");
}
@RequestMapping("/springmvc/v2/members")
public ModelAndView members() {
List<Member> members = memberRepository.findAll();
ModelAndView mv = new ModelAndView("members");
mv.addObject("members", members);
return mv;
}
@RequestMapping("/springmvc/v2/members/save")
public ModelAndView save(HttpServletRequest request, HttpServletResponse response) throws Exception {
String username = request.getParameter("username");
int age = Integer.parseInt(request.getParameter("age"));
Member member = new Member(username, age);
memberRepository.save(member);
ModelAndView mv = new ModelAndView("save-result");
mv.addObject("member", member);
return mv;
}
}
@RequestMapping 애노테이션이 메서드 레벨에 붙기 때문에 연관성 있는 메서드들끼리 묶어서 한 컨트롤러에서 모두 처리가 가능하다.
파일3개가 파일1개가 돼버리니 훨씬 기분이 좋아진다. 그리고 지금 @RequestMapping의 URL 정보 중 `/springmvc/v2/members/`까지는 모두 동일하다. 이것 또한 하나로 줄일 수 있다.
SpringMemberControllerV2
package org.example.servlet.web.springmvc.v2;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.example.servlet.domain.member.Member;
import org.example.servlet.domain.member.MemberRepository;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.servlet.ModelAndView;
import java.util.List;
@Controller
@RequestMapping("/springmvc/v2/members")
public class SpringMemberControllerV2 {
private final MemberRepository memberRepository = MemberRepository.getInstance();
@RequestMapping("/new-form")
public ModelAndView newForm() {
return new ModelAndView("new-form");
}
@RequestMapping("")
public ModelAndView members() {
List<Member> members = memberRepository.findAll();
ModelAndView mv = new ModelAndView("members");
mv.addObject("members", members);
return mv;
}
@RequestMapping("/save")
public ModelAndView save(HttpServletRequest request, HttpServletResponse response) throws Exception {
String username = request.getParameter("username");
int age = Integer.parseInt(request.getParameter("age"));
Member member = new Member(username, age);
memberRepository.save(member);
ModelAndView mv = new ModelAndView("save-result");
mv.addObject("member", member);
return mv;
}
}
위 코드처럼 아예 클래스 레벨에 동일하게 들어가는 Path를 고정시키고 변경되는 부분만 메서드의 @RequestMapping으로 지정해주면 된다.
근데 여전히 불편한 부분이 있다. 위에서 잠깐 얘기했지만 모든것들이 다 ModelAndView를 반환해야 하고, 또 요청 URL에서 파라미터를 받아오는 부분이 굉장히 거슬린다. 이 부분을 실무에서 많이 사용하는 방식으로 변경해보자.
SpringMemberControllerV3
package org.example.servlet.web.springmvc.v3;
import org.example.servlet.domain.member.Member;
import org.example.servlet.domain.member.MemberRepository;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import java.util.List;
@Controller
@RequestMapping("/springmvc/v3/members")
public class SpringMemberControllerV3 {
private final MemberRepository memberRepository = MemberRepository.getInstance();
@RequestMapping("/new-form")
public String newForm() {
return "new-form";
}
@RequestMapping("")
public String members(Model model) {
List<Member> members = memberRepository.findAll();
model.addAttribute("members", members);
return "members";
}
@RequestMapping("/save")
public String save(@RequestParam("username") String username,
@RequestParam("age") int age,
Model model) {
Member member = new Member(username, age);
memberRepository.save(member);
model.addAttribute("member", member);
return "save-result";
}
}
우선 반환타입은 이제 단순 문자열이고 그 문자열이 곧 뷰 이름이 된다. 그리고 필요한 경우 뷰에 전달할 데이터를 모델에 담기 위해 ModelAndView를 사용했는데 파라미터에 그냥 Model을 받을 수가 있다. 그래서 이 녀석의 메서드 중 addAttribute()를 사용하면 알아서 반환할 뷰에게 데이터가 전달된다. 그리고 또한, URL로부터 가져와야 할 파라미터를 @RequestParam을 사용해서 아주 간편하게 가져올 수 있을뿐 아니라 보면 알겠지만 int 타입으로 알아서 형변환까지 해준다. 원래 URL은 무조건 모든게 다 문자열이다. 그래서 문자열이 아닌 경우를 원할땐 다 형변환을 해줘야했다(V2를 생각해보면 된다). 근데 그럴 필요 없이 알아서 타입을 맞춰준다.
참고로, @RequestParam은 GET 요청의 URL 파라미터도 가져오지만 POST 요청의 바디 FormData도 가져올 수 있다.
그리고 마지막으로, 지금의 경우 HTTP Method가 구분이 전혀 안 된 상태이다. 그니까 모든 멤버들을 조회하는 members()를 호출할때 GET, POST, PUT, PATCH, DELETE 다 사용이 가능한 상태이다. 아주 좋지 않다. 이 점도 깔끔하게 수정이 가능하다.
아래처럼 @RequestMapping()에는 Method라는 값을 전달할 수가 있다. 그래서 딱 원하는 Method로 결정할 수 있다.
@RequestMapping(value = "", method = RequestMethod.GET)
public String members(Model model) {
List<Member> members = memberRepository.findAll();
model.addAttribute("members", members);
return "members";
}
근데! 이것마저 귀찮다고 이런걸 만들었다.
SpringMemberControllerV3
package org.example.servlet.web.springmvc.v3;
import org.example.servlet.domain.member.Member;
import org.example.servlet.domain.member.MemberRepository;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@Controller
@RequestMapping("/springmvc/v3/members")
public class SpringMemberControllerV3 {
private final MemberRepository memberRepository = MemberRepository.getInstance();
@GetMapping("/new-form")
public String newForm() {
return "new-form";
}
@GetMapping
public String members(Model model) {
List<Member> members = memberRepository.findAll();
model.addAttribute("members", members);
return "members";
}
@PostMapping("/save")
public String save(@RequestParam("username") String username,
@RequestParam("age") int age,
Model model) {
Member member = new Member(username, age);
memberRepository.save(member);
model.addAttribute("member", member);
return "save-result";
}
}
이게 가장 최신의 깔끔한 방식이다. V1과 비교해보면 정말 군더더기 없이 깔끔하다. 그러나 V1에서 이 V3로의 역사를 알면 더 깊은 이해를 할 수가 있다.
구조 이해하기 1편에서는 직접 MVC 구조와 거의 유사한 구조를 만들어서 이 구조가 어떻게 동작하는지 알아봤다.
이번엔 실제 스프링 MVC 구조를 직접 보고 1편에서 만든 구조와 어떻게 같고 어떤 부분은 다른지를 좀 더 자세히 알아보자.
우선 1편에서 만든 구조와 스프링 MVC 구조의 전체적인 그림을 보자.
스프링 MVC 구조
어떤가? 스프링 MVC 구조와 직접 만든 구조가 거의 똑같다. 이름만 다른거 아닌가? 싶을 정도로 똑같다.
즉, 이 구조를 이해하기 위해 이 구조를 직접 만들어보고 어떻게 동작하는지 직접 해 본 것이다.
비교를 해보자면,
직접 만든 구조 <-> 스프링 MVC 구조
FrontController <-> DispatcherServlet
handlerMappingMap <-> HandlerMapping
MyHandlerAdapter <-> HandlerAdapter
ModelView <-> ModelAndView
viewResolver <-> ViewResolver
MyView <-> View
1편에서 말했던 내용인데 handlerMappingMap을 외부에서 주입받게 구현하면 FrontController는 아예 변경 사항이 없을 것이다라고 말했었다. 그게 스프링 MVC는 하고 있는 일이다. HandlerMapping으로 딱 봐도 타입(클래스, 인터페이스)형이다. 즉, 외부에서 주입받아 사용한다는 의미가 된다. ViewResolver도 마찬가지.
그건 그렇고, 우리가 만든 구조의 핵심은 FrontController였다. 결국 스프링 MVC 구조도 핵심은 DispatchServlet이다. 왜냐? 여기서 적절한 컨트롤러도 다 매핑해주고 외부로의 요청을 받는것도 다 이곳이 최초이기 때문에. 이 녀석을 살짝만 알아보자.
DispatcherServlet
우리가 만든 구조에서 FrontControllerServlet은 서블릿이었다. 스프링 MVC의 DispatcherServlet 역시 서블릿이고 결국 HttpServlet을 상속 받아서 사용한다. 스프링 부트는 DispatcherServlet을 서블릿으로 자동으로 등록하면서 모든 경로(urlPatterns = "/")에 대해서 매핑한다. 그래야 어떤 경로로 사용자가 요청하던, 이 DispatcherServlet을 먼저 통할테니까.
코드가 꽤 길지만 내가 직접 주석 처리한 1번, 2번, 3번을 보자. 결국 직접 만든 FrontControllerServlet에서 가장 핵심인 부분과 유사하다. 1. 핸들러(컨트롤러)를 조회하고 2. 그 핸들러를 다룰 수 있는 어댑터를 찾아서 3. 어댑터의 handle() 메서드를 호출한다.
그리고 그 하단에는 processDispatchResult()를 호출한다. 여기에 핸들러 어댑터의 handle() 메서드를 호출해서 받은 ModelAndView 객체와 핸들러를 넘기는 것을 알 수 있다. 이 메서드는 뭘할까?
이렇게 직접 만든 구조와 거의 동일하다. 물론 스프링 MVC가 훨씬 더 안정적이고 버그에 덜 취약하며 이것 저것 유효성 검사도 많고 잘 만들었지만 흐름이 유사하다는 것이다.
그럼 저 render()는 뭘할까?
DispatcherServlet.render()
protected void render(ModelAndView mv, HttpServletRequest request, HttpServletResponse response) throws Exception {
Locale locale = this.localeResolver != null ? this.localeResolver.resolveLocale(request) : request.getLocale();
response.setLocale(locale);
String viewName = mv.getViewName();
View view;
if (viewName != null) {
// 뷰 리졸버를 통해서 뷰 찾고 뷰를 반환받는다.
view = this.resolveViewName(viewName, mv.getModelInternal(), locale, request);
if (view == null) {
String var10002 = mv.getViewName();
throw new ServletException("Could not resolve view with name '" + var10002 + "' in servlet with name '" + this.getServletName() + "'");
}
} else {
view = mv.getView();
if (view == null) {
throw new ServletException("ModelAndView [" + mv + "] neither contains a view name nor a View object in servlet with name '" + this.getServletName() + "'");
}
}
if (this.logger.isTraceEnabled()) {
this.logger.trace("Rendering view [" + view + "] ");
}
try {
if (mv.getStatus() != null) {
request.setAttribute(View.RESPONSE_STATUS_ATTRIBUTE, mv.getStatus());
response.setStatus(mv.getStatus().value());
}
// 뷰 렌더링
view.render(mv.getModelInternal(), request, response);
} catch (Exception var8) {
Exception ex = var8;
if (this.logger.isDebugEnabled()) {
this.logger.debug("Error rendering view [" + view + "]", ex);
}
throw ex;
}
}
마찬가지로 내가 직접 넣은 주석을 보면, 뷰 리졸버를 통해 뷰를 찾아 결국 마지막 즈음에 뷰를 렌더링한다. 결국은 같은 흐름으로 이어진다.
그러니까 직접 만든 구조와 흐름이 100% 동일하다.
그리고 스프링 MVC는 확장에 유연하고 변경에 닫혀있는 OCP원칙을 훨씬 더 잘 고수하며 만든 프레임워크라서 이 DispatcherServlet의 코드 변경 없이 원하는 기능을 변경하거나 확장할 수 있다. 지금까지 말했던 대부분의 것들을 확장 가능할 수 있게 인터페이스로 제공한다.
이 인터페이스들만 구현해서, DispatchServlet에 등록하면 나만의 컨트롤러를 만들수도 있다. (만들라는 얘기는 절대 아니다.)
이렇게 큰 맥락에서 스프링 MVC 구조와 직접 만든 구조를 비교해 보았다. 이미 직접 만들어봤기 때문에 이해하는데 어렵지 않았다. 이런 과정을 통해 스프링 MVC가 동작하는구나를 이해하면 된다. 그럼 DispatcherServlet을 알아봤는데 핸들러와 핸들러 어댑터는 어떻게 만들었을까? 요새 스프링으로 개발하는 거의 99%는 애노테이션 기반의 컨트롤러를 사용한다. 그래서 RequestMappingHandlerAdapter라는걸 스프링이 만들어서 사용하는데 그 전 세대 사람들은 어떻게 개발했을까?
핸들러 매핑과 핸들러 어댑터
지금은 전혀 사용되지 않지만, 과거에 주로 사용했던 스프링이 제공하는 간단한 컨트롤러로 핸들러 매핑과 어댑터를 이해해보자.
@Component 애노테이션을 활용해서 빈으로 자동 주입을 했다. 그리고 빈의 이름을 지정했는데 꼭 보면 빈의 이름이 URL같이 생겼다. 맞다. 빈의 이름을 URL로 매핑한다.
그래서 한번 URL에 다음 경로로 들어가보자. `http://localhost:8080/springmvc/old-controller`
저 시스템 로그가 찍히면 정상적으로 동작하는 것이다.
그럼 이 URL이 호출될 때 이 컨트롤러를 실행하는 과정이 어떻게 될까? 우선 이 컨트롤러가 실행되려면 두가지가 필요하다.
HandlerMapping
HandlerAdapter
가장 먼저, 핸들러 매핑을 통해서 이 컨트롤러를 찾을 수 있어야 한다. 스프링은 핸들러 매핑에 어떻게 등록할까?
스프링 부트가 자동 등록하는 핸들러 매핑과 핸들러 어댑터가 있다.
스프링 부트가 자동 등록해주는HandlerMapping
0 = RequestMappingHandlerMapping
1 = BeanNameUrlHandlerMapping
우선 0번부터 우선순위가 더 높은거라고 생각하면 된다. RequestMappingHandlerMapping은 애노테이션 기반으로 컨트롤러를 찾는 핸들러 매핑이다. 이건 아니고 두번째 거를 보자. BeanNameUrlHandlerMapping이다. 이름만 봐도 너무 이거일것같다. 맞다.
= 빈의 이름이 곧 URL이 되는 컨트롤러를 찾는 핸들러 매핑이다.
이 핸들러 매핑을 통해 적절한 컨트롤러 (위의 예시에선 내가 만든 OldController)를 찾아서 이 컨트롤러를 처리할 수 있는 어댑터를 찾는다. 스프링 부트가 역시 마찬가지로 자동으로 등록해주는 HandlerAdapter가 있다.
스프링 부트가 자동 등록해주는 HandlerAdapter
0 = RequestMappingHandlerAdapter
1 = HttpRequestHandlerAdapter
2 = SimpleControllerHandlerAdapter
우선, 마찬가지로 0번이 제일 우선순위가 높은것이다. 그리고 RequestMappingHandlerAdapter는 애노테이션 기반의 핸들러를 처리할 수 있는 어댑터이고 HttpRequestHandlerAdapter는 이후에 살펴볼 핸들러 타입의 어댑터이다. 즉, 마지막 SimpleControllerHandlerAdapter가 바로 Controller라는 인터페이스를 구현한 컨트롤러를 처리할 수 있는 어댑터이다. 실제로 이 코드를 한번 봐보자.
SimpleControllerHandlerAdapter
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.springframework.web.servlet.mvc;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.lang.Nullable;
import org.springframework.web.servlet.HandlerAdapter;
import org.springframework.web.servlet.ModelAndView;
public class SimpleControllerHandlerAdapter implements HandlerAdapter {
public SimpleControllerHandlerAdapter() {
}
public boolean supports(Object handler) {
return handler instanceof Controller;
}
@Nullable
public ModelAndView handle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
return ((Controller)handler).handleRequest(request, response);
}
public long getLastModified(HttpServletRequest request, Object handler) {
if (handler instanceof LastModified lastModified) {
return lastModified.getLastModified(request);
} else {
return -1L;
}
}
}
굉장히 익숙하게 생긴 supports()가 있고 보면 Controller 타입인지를 체크한다. 그 Controller는 위에서 다뤄본 Controller 인터페이스이다. 이게 바로 과거의 방식이었다. 하나 더 알아보자.
이번엔 Controller 인터페이스 말고 HttpRequestHandler를 알아보자.
스프링 부트가 자동으로 등록해주는 HttpRequestHandler
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.springframework.web;
import jakarta.servlet.ServletException;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import java.io.IOException;
@FunctionalInterface
public interface HttpRequestHandler {
void handleRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException;
}
이것도 역시 위 Controller 인터페이스와 유사한데 얘는 리턴 타입도 void이다. 즉 저 메서드 안에서 전부 다 처리해주는 방식이다.
이 또한 역시 빈의 이름으로 URL을 매핑하는 핸들러를 만든다. 그래서 핸들러를 찾을때 빈의 이름과 URL이 똑같은 컨트롤러를 찾는다. (바로 이 MyHttpRequestHandler) 그럼 핸들러 매핑을 통해 핸들러를 찾았으면 이 핸들러가 어떤 어댑터에 적용될 수 있는지 핸들러 어댑터를 찾는다. 위에 말했던 1번 어댑터인 HttpRequestHandlerAdapter에 걸리는 것이다.
보면 결국은 1편에서 직접 만들어본 구조랑 완전 똑같다. 스프링이 어떻게 MVC 구조를 만들었는지 아니까 이게 어렵지가 않다. 그리고 이 어댑터도 실제 코드를 보면 이렇게 생겼다.
HttpRequestHandlerAdapter
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.springframework.web.servlet.mvc;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.lang.Nullable;
import org.springframework.web.HttpRequestHandler;
import org.springframework.web.servlet.HandlerAdapter;
import org.springframework.web.servlet.ModelAndView;
public class HttpRequestHandlerAdapter implements HandlerAdapter {
public HttpRequestHandlerAdapter() {
}
public boolean supports(Object handler) {
return handler instanceof HttpRequestHandler;
}
@Nullable
public ModelAndView handle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
((HttpRequestHandler)handler).handleRequest(request, response);
return null;
}
public long getLastModified(HttpServletRequest request, Object handler) {
if (handler instanceof LastModified lastModified) {
return lastModified.getLastModified(request);
} else {
return -1L;
}
}
}
supports()는 HttpRequestHandler 타입인지를 판단한다. 그리고 handle()은 결국 그 핸들러가 가지고 있는 (구현해야만 하는) handleRequest()를 호출한다. 너무너무 이해가 잘된다. 그리고 이젠 이런 방식을 사용하지 않는다는 것도 알고 있다.
지금은 거의 100%에 가깝게 애노테이션 기반의 컨트롤러(핸들러)를 사용하기 때문에 나도 이 방식으로 개발을 할거지만 이런 역사가 있었다는 사실을 알면 개발하는데 무조건 도움이 된다. 어떤게 불편해서 지금의 스프링이 있는지 이해를 할 수 있기 때문에.
그럼 핸들러와 핸들러 어댑터를 알아봤으니 뷰 리졸버도 한번 알아보자.
뷰 리졸버
우리가 직접 만든 구조에서 뷰 리졸버를 통해 논리 이름을 가지고 전체 이름을 가질 수 있게 만들었다.
스프링 부트를 사용하면 어떻게 해야 할까? 우선 위에서 만들어본 완전 과거 버전의 컨트롤러인 OldController를 이렇게 변경해보자.
OldController
package org.example.servlet.web.springmvc.old;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.ModelAndView;
import org.springframework.web.servlet.mvc.Controller;
@Component("/springmvc/old-controller")
public class OldController implements Controller {
@Override
public ModelAndView handleRequest(HttpServletRequest request, HttpServletResponse response) throws Exception {
System.out.println("OldController.handleRequest");
return new ModelAndView("new-form");
}
}
반환값을 변경했다. 기존에는 null을 리턴했는데 이제 new ModelAndView("new-form")을 리턴한다. 그리고 이 컨트롤러를 호출하면 어떻게 될까? 결과는 다음과 같다. 아무것도 나타나지 않는다. 분명 우리 프로젝트에는 JSP 파일이 있다.
그러나 아무것도 보이진 않는다. 그치만 로그는 찍히고 있다. 컨트롤러 호출은 됐다는 이야기이다.
어떻게 동작하는 걸까? 스프링 부트는 InternalResourceViewResolver 라는 뷰 리졸버를 자동으로 등록하는데, 이때 application.yml 파일에 등록한 spring.mvc.view.prefix, spring.mvc.view.suffix 설정 정보를 사용해서 등록한다.
그러니까 스프링은 뷰 리졸버도 인터페이스로 등록하고 그 인터페이스를 구현한 많은 구현체 중 하나로부터 이 뷰를 보여주는 방법을 사용하는 것이다. 그리고 스프링 부트가 자동으로 등록하는 뷰 리졸버는 여러개가 있고 그 중 일부는 다음과 같다.
1 = BeanNameViewResolver: 빈 이름으로 뷰를 찾아서 반환 (예: 엑셀 파일 생성 기능에 사용)
2 = InternalResourceViewResolver: JSP를 처리할 수 있는 뷰를 반환
저 중 BeanNameViewResolver는 현재 위 코드의 해당 사항이 아니다. 이는 빈 이름으로 뷰를 찾아서 반환하는데 우리가 호출하는 뷰 이름이 `new-form`인데 이런 빈이 없기 때문에 자기는 처리해줄 수 없다고 다음으로 넘긴다. 그리고 이 뷰 리졸버는 보통 엑셀 파일 생성 기능에 사용한다.
참고로, Thymeleaf 뷰 템플릿을 사용하면 ThymeleafViewResolver를 등록해야 하는데 최근 스프링 부트는 라이브러리만 추가하면 스프링 부트가 이런 작업도 모두 자동으로 해준다.
그래서 전체적인 구조를 다시 보자.
결국 핸들러 어댑터 목록을 통해 찾은 핸들러를 처리할 수 있는 핸들러 어댑터를 찾고 핸들러 어댑터가 가진 handle()을 호출하면 결과적으로 뷰의 논리 이름을 얻게 된다. 뷰의 논리 이름을 얻은 DispatchServlet은 뷰 리졸버를 통해 뷰를 찾아내는데 수많은 뷰 리졸버 중 우리는 InternalResourceViewResolver를 통해 뷰를 찾아서 렌더링 하게 된다.
결론
이게 바로 스프링 MVC의 전체 구조가 된다. 굉장히 복잡한 구조인데 직접 이 구조를 만들어보고 나니 그렇게 어렵게 느껴지지 않는다. 제대로 배운 느낌이 든다. 이제 구조도 다 이해했으니 진짜 Spring MVC를 사용해보자.
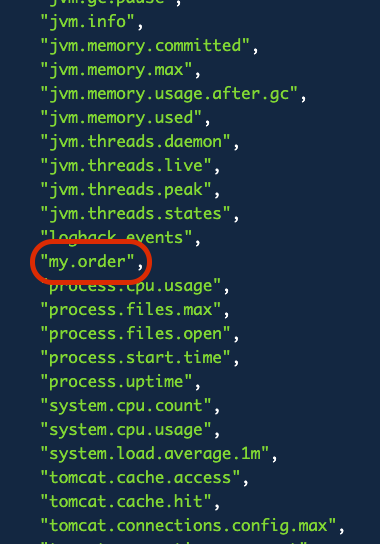
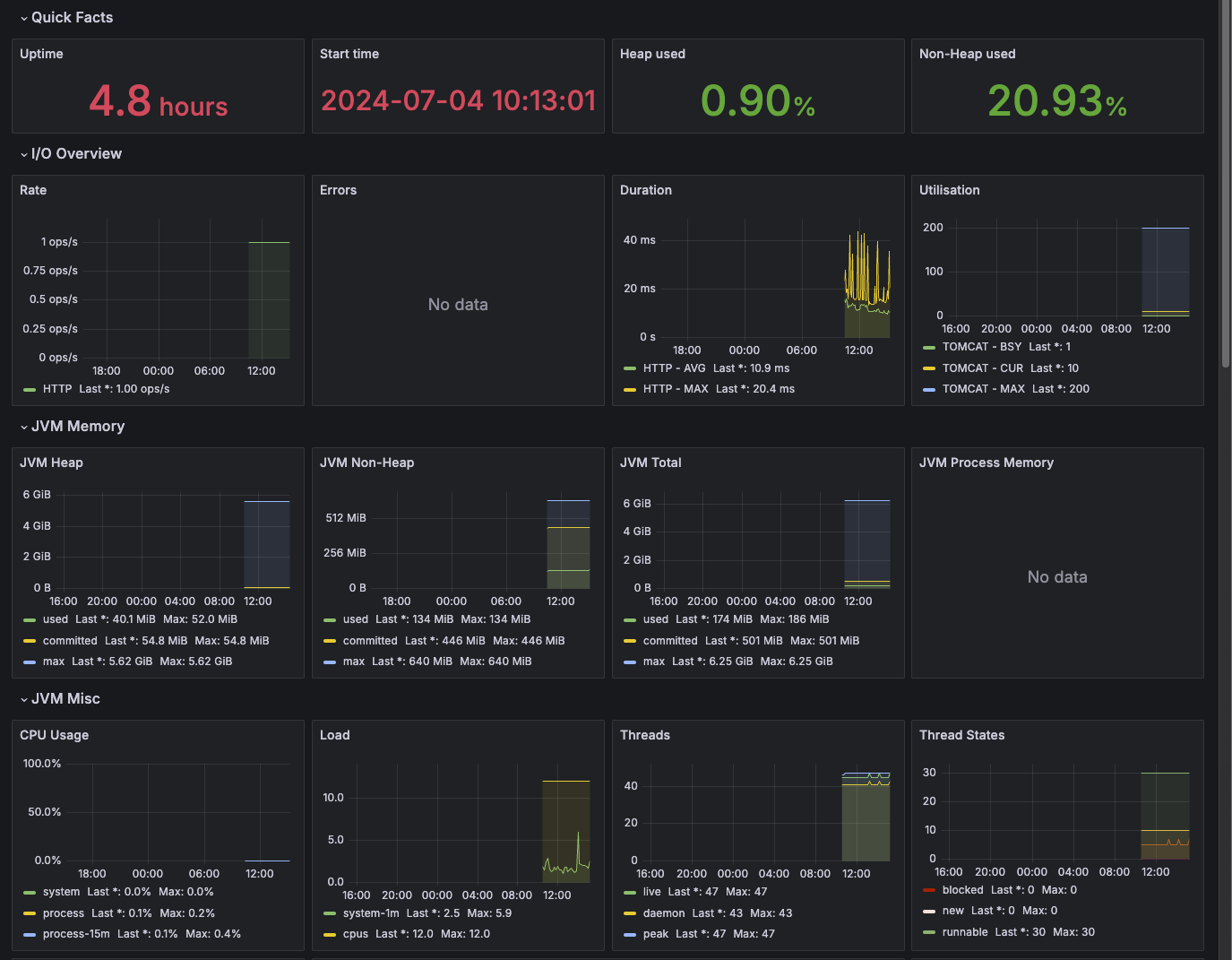
Part.2를 봤다면, CPU 사용량, 메모리 사용량, 톰캣의 쓰레드, DB 커넥션 풀과 같이 공통으로 사용되는 기술 메트릭은 이미 등록되어 있다. 이런 등록된 메트릭을 사용해서 대시보드를 구성하고 모니터링 하면 된다. 여기서 더 나아가서 비즈니스에 특화된 부분을 모니터링 하고 싶다. 예를 들어, 주문수, 취소수, 재고 수량 같은 메트릭들이 있다. 이 부분은 공통으로 만드는 게 아니라 각각의 비즈니스에 특화된 부분들이다.
이런 메트릭도 시스템을 운영하는데 굉장히 많은 도움이 된다. 예를 들어, 취소수가 갑자기 급증하거나 재고 수량이 임계치 이상으로 쌓이는 부분들은 기술적인 메트릭으로 확인할 수 없는 우리 시스템의 비즈니스 문제를 빠르게 파악하는데 도움을 준다.
그래서 이런 자기만의 메트릭을 만들어보자.
우선 코드가 필요하다. 간단한 주문 관련 코드를 만들자.
OrderService
package hello.order;
import java.util.concurrent.atomic.AtomicInteger;
public interface OrderService {
void order();
void cancel();
AtomicInteger getStock(); // Atomic : 멀티 쓰레드 환경에서 안전하게 값에 쓰기를 할 수 있는 방법
}
OrderServiceV0
package hello.order.v0;
import hello.order.OrderService;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.atomic.AtomicInteger;
@Slf4j
public class OrderServiceV0 implements OrderService {
private final AtomicInteger stock = new AtomicInteger(100);
@Override
public void order() {
log.info("주문");
stock.decrementAndGet();
}
@Override
public void cancel() {
log.info("취소");
stock.incrementAndGet();
}
@Override
public AtomicInteger getStock() {
return stock;
}
}
OrderConfigV0
package hello.order.v0;
import hello.order.OrderService;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class OrderConfigV0 {
@Bean
OrderService orderService() {
return new OrderServiceV0();
}
}
OrderController
package hello.controller;
import hello.order.OrderService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@Slf4j
@RestController
public class OrderController {
private final OrderService orderService;
public OrderController(OrderService orderService) {
this.orderService = orderService;
}
@GetMapping("/order")
public String order() {
log.info("order");
orderService.order();
return "order";
}
@GetMapping("/cancel")
public String cancel() {
log.info("cancel");
orderService.cancel();
return "cancel";
}
@GetMapping("/stock")
public int stock() {
log.info("stock");
return orderService.getStock().get();
}
}
간단한 OrderService 인터페이스와 버전별 구현체가 등록될 것이고 컨트롤러가 있다.
그리고 버전별로 계속 빈으로 등록될 서비스와 설정 클래스가 달라지기 때문에 스캔 경로도 수정해줘야 한다.
ActuatorApplication
package hello;
import hello.order.v0.OrderConfigV0;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Import;
@Import(OrderConfigV0.class)
@SpringBootApplication(scanBasePackages = "hello.controller")
public class ActuatorApplication {
public static void main(String[] args) {
SpringApplication.run(ActuatorApplication.class, args);
}
}
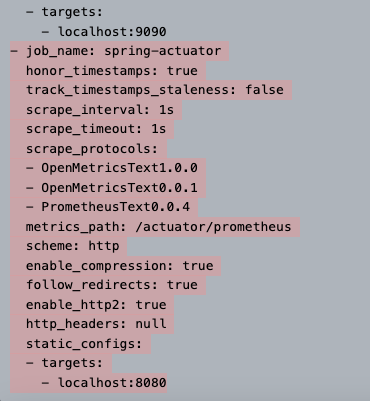
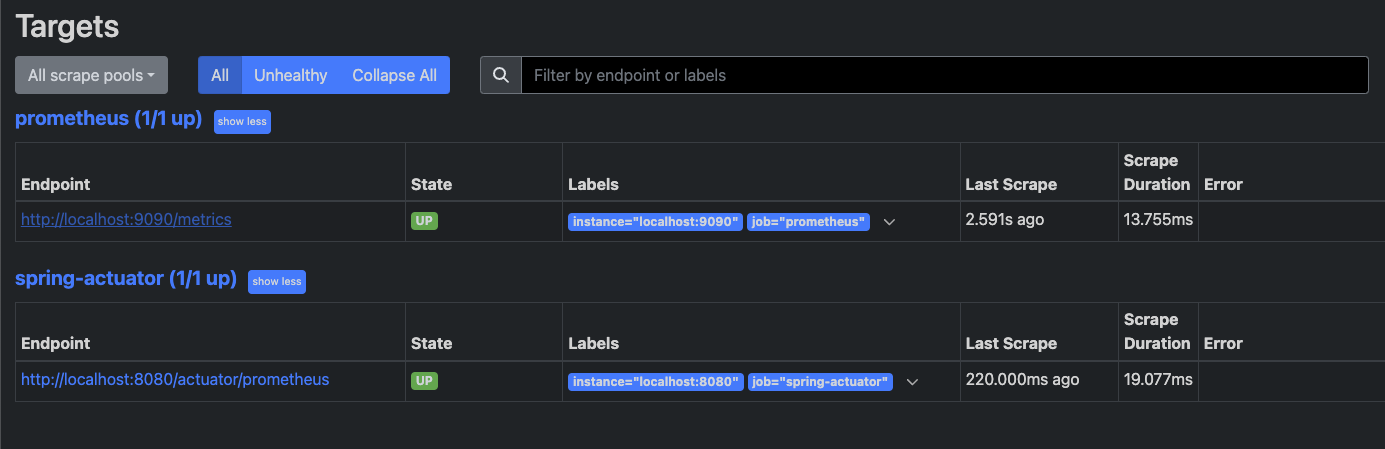
이제 주문, 취소, 현재 재고수량에 관련된 컨트롤러에 접속하면 정상적으로 잘 노출되는 것을 확인할 수 있을것이다. 이제 메트릭을 만들어보자.
메트릭 등록 V1 - 카운터
우선, 하나씩 증가하는 메트릭을 만들어보자.
메트릭을 등록하려면 먼저 MeterRegistry 라는 클래스를 주입받아야 한다. 액츄에이터를 사용하면 이 MeterRegistry는 자동으로 빈으로 등록된다. 그래서 이 녀석을 통해 카운터나 게이지를 등록해보자.
OrderServiceV1
package hello.order.v1;
import hello.order.OrderService;
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.MeterRegistry;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.atomic.AtomicInteger;
@Slf4j
public class OrderServiceV1 implements OrderService {
private final AtomicInteger stock = new AtomicInteger(100);
private final MeterRegistry meterRegistry;
public OrderServiceV1(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
}
@Override
public void order() {
log.info("주문");
stock.decrementAndGet();
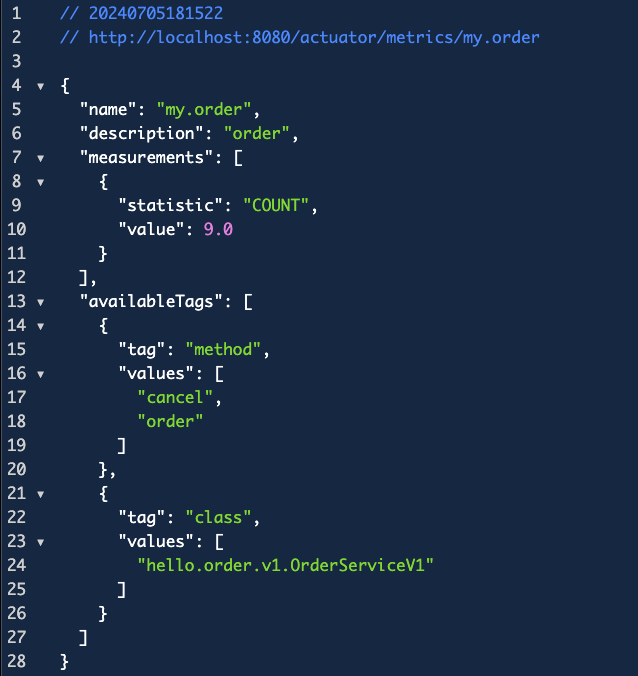
Counter.builder("my.order")
.tag("class", this.getClass().getName())
.tag("method", "order")
.description("order")
.register(meterRegistry)
.increment();
}
@Override
public void cancel() {
log.info("취소");
stock.incrementAndGet();
Counter.builder("my.order")
.tag("class", this.getClass().getName())
.tag("method", "cancel")
.description("order")
.register(meterRegistry)
.increment();
}
@Override
public AtomicInteger getStock() {
return stock;
}
}
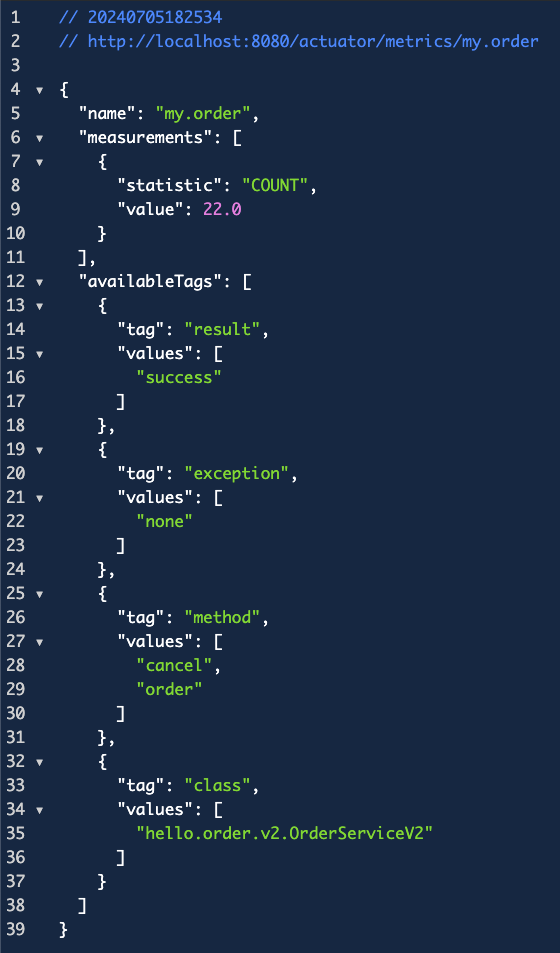
위 코드를 보면, 먼저 MeterRegistry를 주입받고, order()와 cancel()에서 메트릭을 만들고 있다.
그리고 Counter라는 io.micrometer.core.instrument 패키지에 있는 인터페이스를 통해 카운터 메트릭을 등록한다.
builder("my.order")는 메트릭의 이름으로 표현될 부분이고, tag는 메트릭에 달린 태그들을 만들어준다. 그리고 register(meterRegistry)로 메트릭으로 등록한 후에 메서드가 호출될 때 한번씩 그 값을 증가시키는 increment()를 호출한다.
이렇게 하면 끝이다. 이제 V1 Config 클래스를 만들어서 빈으로 등록하자.
OrderConfigV1
package hello.order.v1;
import hello.order.OrderService;
import hello.order.v0.OrderServiceV0;
import io.micrometer.core.instrument.MeterRegistry;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class OrderConfigV1 {
@Bean
OrderService orderService(MeterRegistry meterRegistry) {
return new OrderServiceV1(meterRegistry);
}
}
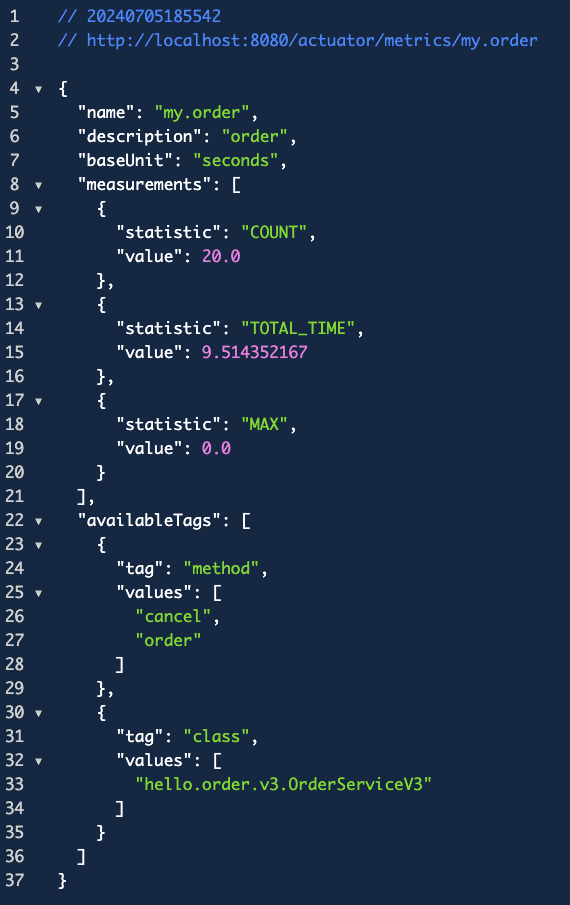
이번엔 io.micrometer.core.instrument 패키지에 있는 Timer라는 녀석을 가져온다. 마찬가지로 직접 등록하기 때문에 MeterRegistry도 가져와야 한다. 그래서 아까 카운터를 등록할때와 유사하게 등록을 해주면 된다. 근데 이 Timer는 이 인스턴스로 받아서 record()안에서 실행 로직을 수행해야 한다. 그 점이 좀 다르다는 것 확인하고! 그리고 코드가 너무 짧기 때문에 뭐 실행 시간이나 최대 시간을 계산하는게 매우 의미없을 수 있어서 랜덤하게 sleep()을 적용했다.
OrderConfigV3
package hello.order.v3;
import hello.order.OrderService;
import io.micrometer.core.instrument.MeterRegistry;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class OrderConfigV3 {
@Bean
OrderService orderService(MeterRegistry meterRegistry) {
return new OrderServiceV3(meterRegistry);
}
}
설정 클래스에 빈으로 잘 등록해준다. 스프링 부트 실행 클래스에 이 설정 클래스로 바꾸는건 생략하겠다. 계속 했던거니까!
그리고 주문과 취소를 여러번 좀 요청한 다음 메트릭을 보면 이렇게 나온다.
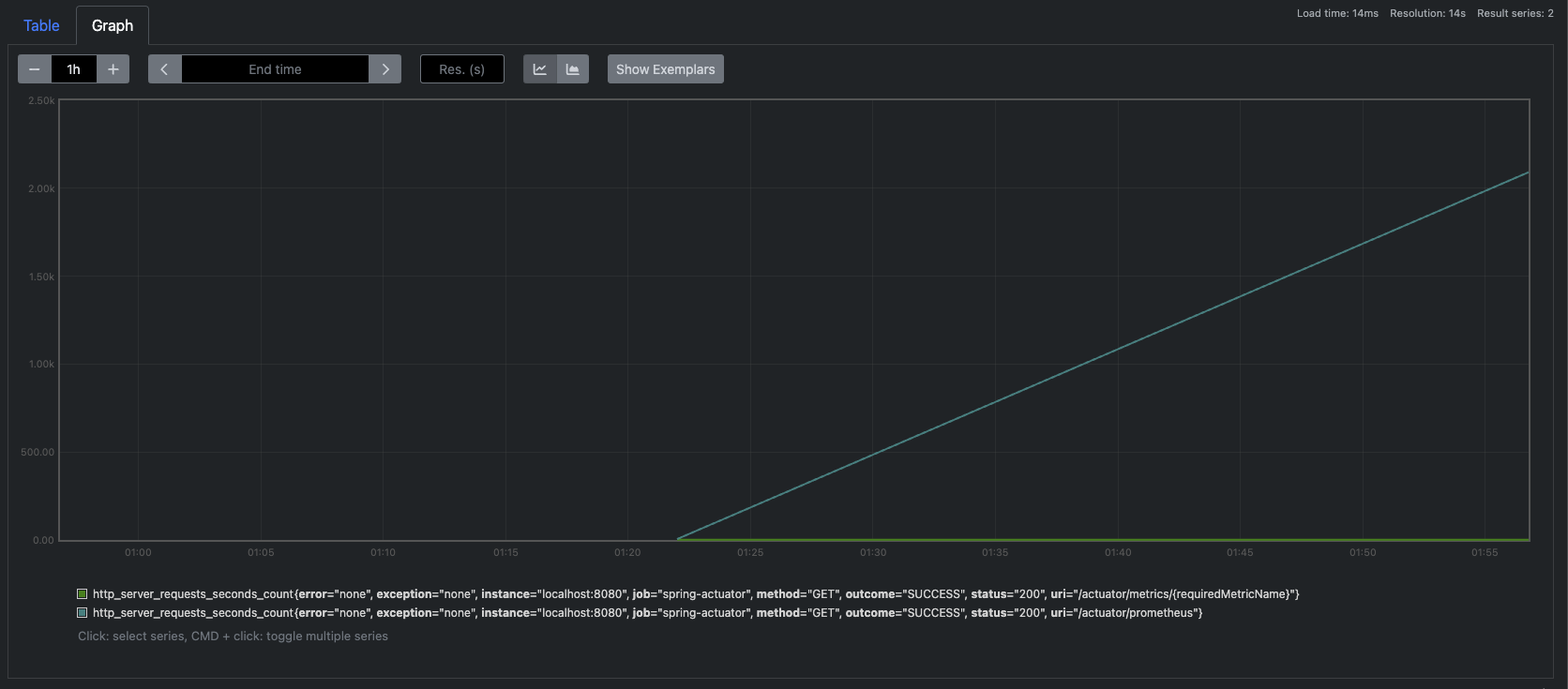
카운터도 있는데 총 걸린 시간과 최대 시간이 나온다. 보면 MAX값이 0인 이유는 위에서 말한것처럼 3분 간격으로 계속 체크를 한다. 내가 지난 3분 동안 요청이 없어서 값이 0이다. 그리고 전체 걸린 시간과 카운트가 있으면? 평균시간도 구할 수 있다.
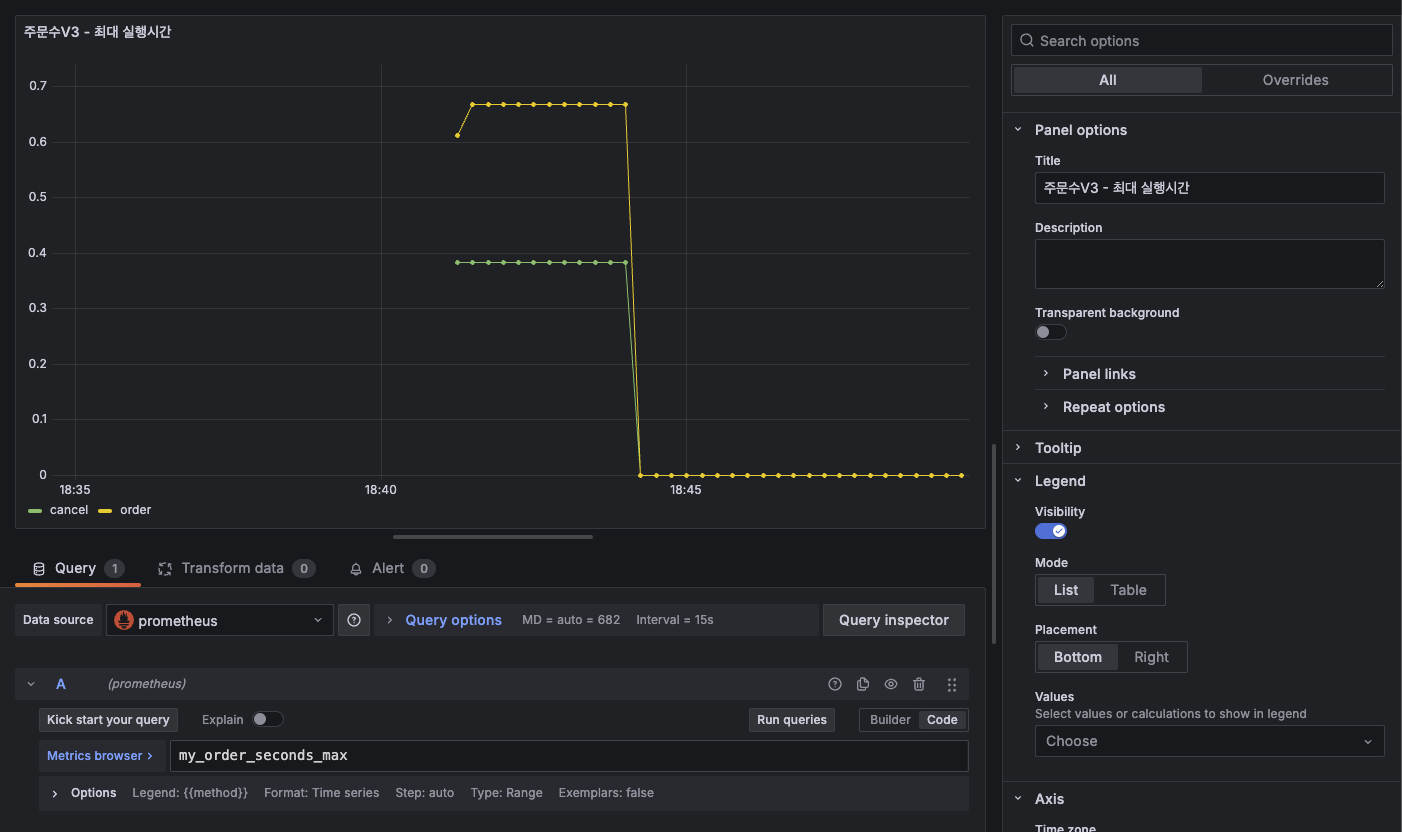
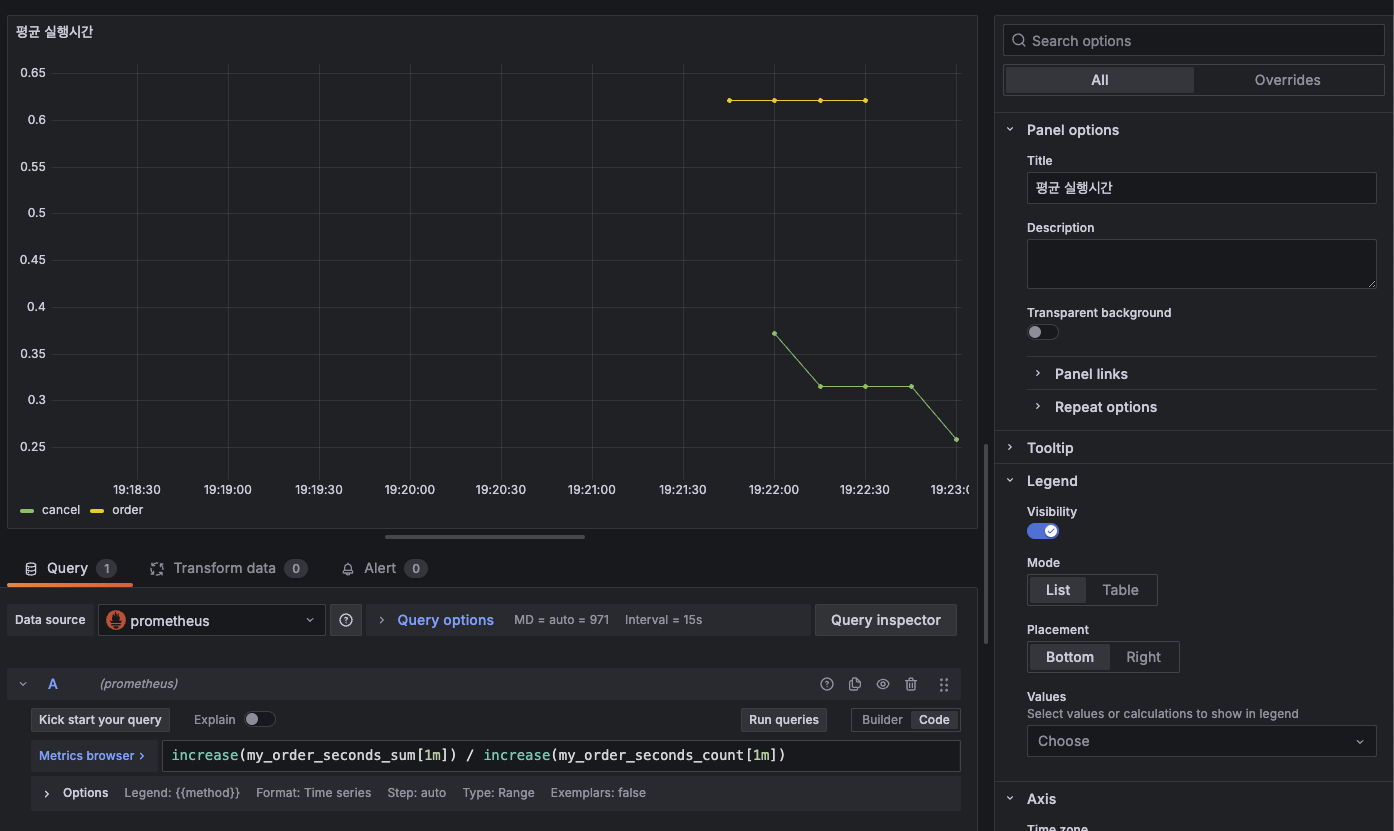
그래서 이 또한 그라파나로 이쁘게 가시화해보자.
최대 실행 시간에 대한 그래프
평균 실행 시간에 대한 그래프
이렇게 시간에 관련된 메트릭 데이터도 그라파나로 이쁘게 볼 수 있게 됐다. 이제 이 Timer를 AOP로 바꿔보자. 이미 스프링이 다 만들어 놓은것을 가져다가 사용만 하면 된다.
메트릭 등록 - @Timed
이제 AOP로 간단하게 등록해보자.
OrderServiceV4
package hello.order.v4;
import hello.order.OrderService;
import io.micrometer.core.annotation.Timed;
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.Timer;
import lombok.extern.slf4j.Slf4j;
import java.util.Random;
import java.util.concurrent.atomic.AtomicInteger;
@Timed(value = "my.order")
@Slf4j
public class OrderServiceV4 implements OrderService {
private final AtomicInteger stock = new AtomicInteger(100);
@Override
public void order() {
log.info("주문");
stock.decrementAndGet();
sleep(500);
}
private static void sleep(int l) {
try {
Thread.sleep(l + new Random().nextInt(200));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
@Override
public void cancel() {
log.info("취소");
stock.incrementAndGet();
sleep(200);
}
@Override
public AtomicInteger getStock() {
return stock;
}
}
@Timed 애노테이션을 사용하면 된다. 이 애노테이션은 클래스 레벨도 가능하고 메서드 레벨도 다 가능하다.
아까 @Counted랑 다른게 없어서 바로 넘어가자.
OrderConfigV4
package hello.order.v4;
import hello.order.OrderService;
import io.micrometer.core.aop.TimedAspect;
import io.micrometer.core.instrument.MeterRegistry;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class OrderConfigV4 {
@Bean
OrderService orderService() {
return new OrderServiceV4();
}
@Bean
public TimedAspect timedAspect(MeterRegistry meterRegistry) {
return new TimedAspect(meterRegistry);
}
}
마찬가지로 이 @Timed도 TimedAspect를 빈으로 꼭! 등록을 해줘야 한다. 이렇게 해주면 끝!
메트릭 등록 - 게이지
게이지는 임의로 오르내릴 수 있는 단일 숫자 값을 나타내는 메트릭이다. 예를 들면, 재고 수량이나 주식의 현재가 같은 올랐다가도 내렸다가도 할 수 있는 값을 말한다. 그럼 위에서 계속 작업했던 주문 관련 서비스의 재고 수량을 가지고 게이지 메트릭을 만들어보자.
참고로, 게이지로 메트릭을 만들어야하나 카운터로 메트릭을 만들어야하나 고민이 된다면 "값이 줄거나 오르거나 둘 다 가능한가?"를 생각해보면 된다. 떨어지기도 하고 오르기도 하는 경우라면 그냥 게이지로 만들면 된다.
StockConfigV1
package hello.order.gauge;
import hello.order.OrderService;
import io.micrometer.core.instrument.Gauge;
import io.micrometer.core.instrument.MeterRegistry;
import jakarta.annotation.PostConstruct;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class StockConfigV1 {
@Bean
public MyStockMetric myStockMetric(OrderService orderService, MeterRegistry registry) {
return new MyStockMetric(orderService, registry);
}
@Slf4j
static class MyStockMetric {
private OrderService orderService;
private MeterRegistry meterRegistry;
public MyStockMetric(OrderService orderService, MeterRegistry meterRegistry) {
this.orderService = orderService;
this.meterRegistry = meterRegistry;
}
// 메트릭을 확인할 때 마다 (`/actuator/*` 요청을 의미) 이 메서드가 호출 된다.
@PostConstruct
public void init() {
Gauge.builder("my.stock", orderService, service -> {
log.info("stock gauge call");
return service.getStock().get();
}).register(meterRegistry);
}
}
}
위 코드가 게이지 메트릭을 등록하는 코드이다.
우선 MyStockMetric 이라는 클래스를 만들었다. 이 클래스는 OrderService, MeterRegistry를 주입받는다.
@PostConstruct 애노테이션으로 빈으로 등록된 후 실행될 메서드 init()을 만든다.
안에서 Gauge라는 io.micrometer.core.instrument 패키지에 있는 녀석을 가져와서 builder("my.stock")이라는 메트릭 이름을 준다. 그리고 OrderService를 넘기고 그 서비스의 현재 재고 수량을 반환하는 메서드를 리턴한다.
이렇게 하면 이제 메트릭을 외부에서 확인할 때마다 (예: 누군가가 `/actuator/*`로 요청을 날린다, 프로메테우스가 주기적으로 메트릭 정보를 수집하기 위해 요청을 하는 경우) 이 게이지의 세번째 파라미터인 람다 함수가 호출된다.
그리고 이 MyStockMetric 클래스를 빈으로 등록한다.
이러면 끝이다. 스프링 부트 시작 클래스에 이 설정 클래스 등록하는 것 잊지말고! 실행하면 다음과 같이 계속해서 1초마다 로그가 찍힐것이다. 왜 그럴까? 내가 프로메테우스로 1초마다 `/actuator/prometheus`로 데이터 받아오는 작업을 하게 했기 때문.
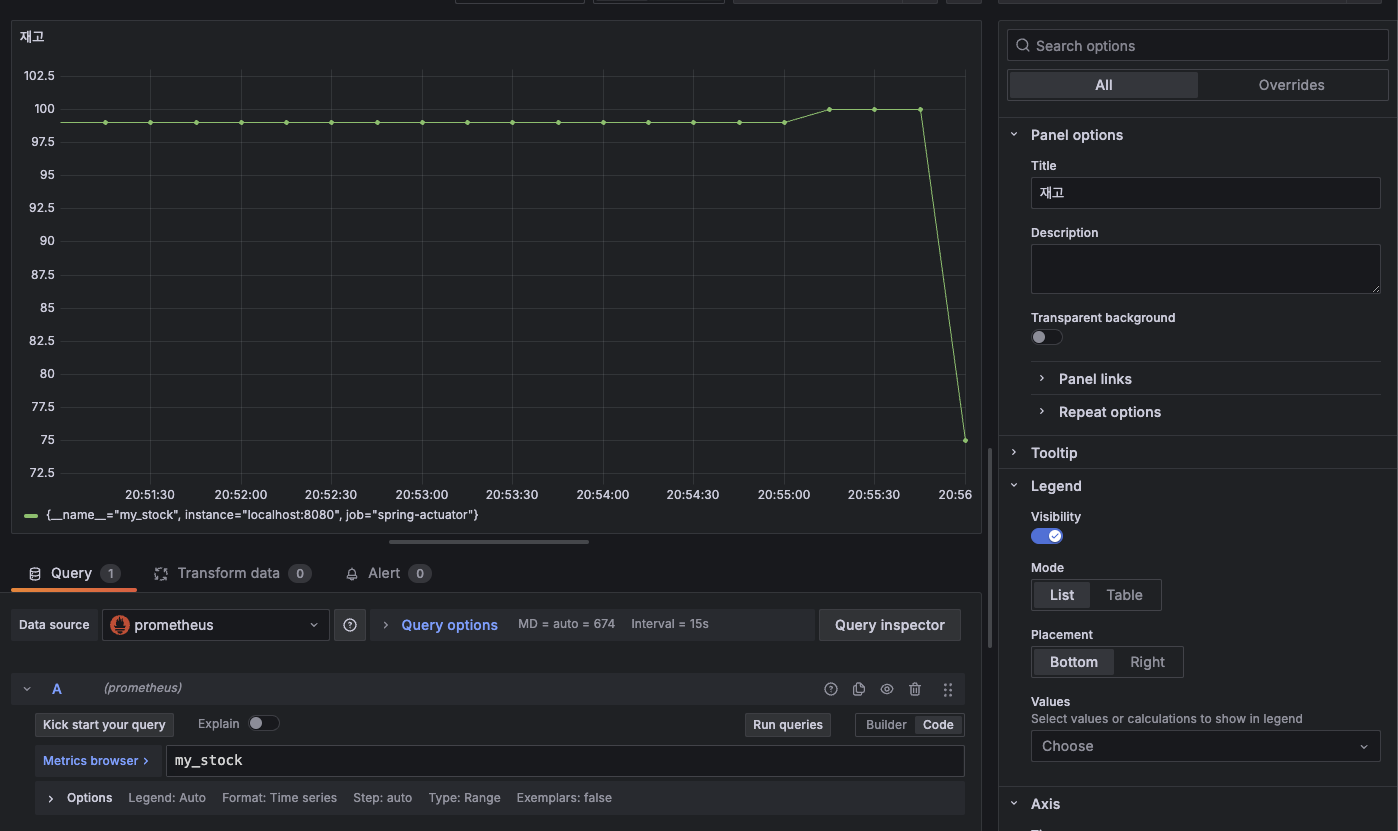
이렇게 한 후 간단하게 그라파나로 이쁘게 보여줘보자. 게이지에 대한 쿼리는 아주 간단하다. 내가 100개가 있는 상태에서 주문 요청을 여러번 했더니 저렇게 그래프가 꺾였다. 이제 취소도 하면 또 올라오게 된다. 이런게 게이지다.
전체를 한눈에 볼 수 있는 가장 큰 뷰 마이크로미터, 프로메테우스, 그라파나 이렇게해서 사용하면 된다.
모니터링 대상
시스템 메트릭 (CPU, 메모리)
애플리케이션 메트릭 (톰캣 쓰레드 풀, DB 커넥션 풀, 애플리케이션 호출 수)
비즈니스 메트릭 (주문수, 취소수)
애플리케이션 추적
주로 각각의 HTTP 요청을 추적, 일부는 마이크로서비스 환경에서 분산 추적. 핀포인트를 사용하면 된다.
로그
가장 자세한 추적, 원하는대로 커스텀 가능.
같은 HTTP 요청을 묶어서 확인할 수 있는 방법이 중요하고 그 방법은 MDC를 적용하면 된다.
파일로 직접 로그를 남기는 경우
일반 로그와 에러 로그를 구분해서 파일로 남기기
클라우드에 로그를 저장하는 경우
검색이 잘 되도록 구분
정리를 하자면, 각각 용도가 다르다. 관찰을 할 땐 전체에서 좁게 가야한다. 핀포인트는 정말 좋다. 핀포인트는 무조건 사용할 것 마이크로서비스 분산 모니터링도 가능하고 대용량 트래픽에도 가능하다.
알람
모니터링 툴에서 일정 이상 수치가 넘어가면 슬랙 연동하기
알람은 2가지 종류(경고, 심각)로 꼭 구분해서 관리
왜 그럴까? 경고는 하루 1번 정도 사람이 그냥 들어가서 있나? 하고 보면 된다. 푸시 알림도 필요없다. 근데 심각은 즉시 확인해야 한다. 그래서 푸시 알림도 필요하다. 푸시 알림이 경고까지 적용되면 알림이 와도 느슨한 태도가 될 수 있어서 안된다. 그리고 업무와 삶에 방해가 되지 않아야 한다.
예를 들면,
디스크 사용량 70% - 경고
디스크 사용량 80, 90% - 심각
CPU 사용량 40% - 경고
CPU 사용량 50% - 심각
그리고 알림으로 정해놓은 것 중 알림이 아니어도 될 것 같다싶으면 바로바로 처리해야 한다. 이것도 알림 자체에 느슨한 태도를 유발할 수 있는 원인!
근데 그 전에 원래 사용하던 모니터링 툴이 있는데 모니터링 툴을 교체한다고 하면 어떻게 될까?
예를 들어, 기존에 사용하던 모니터링 툴이 JMX 모니터링 툴이었다고 해보자. 그럼 이 모니터링 툴에 지표를 전달하기 위해 JMX API를 사용해서 데이터를 전달하는데 중간에 프로메테우스를 사용한다고 하면 원래라면 도구가 다르니 전달하는 방식도 다르고 그럼 API도 교체해야 할 것이다. 그럼 모니터링 툴을 바꿨을뿐인데 애플리케이션에 수정이 일어난다.
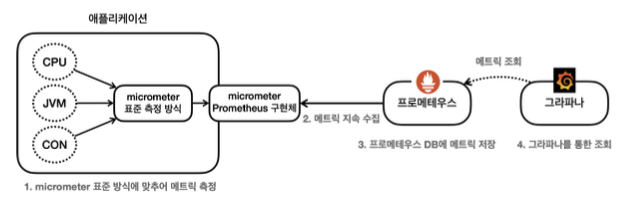
이런 불편한 상황을 해결하기 위해 나타난 라이브러리가 마이크로미터(Micrometer)이다.
마이크로미터는 모니터링 툴에 전달하는 지표를 추상화해놓은 라이브러리이다. 그러니까 이 추상화가 이렇게 중요하다.
코드에서도 인터페이스와 그 인터페이스를 구현한 구현체가 아무리 많아지고 사용하는 기술이 바뀌어도 의존하고 있는 것이 인터페이스 하나 뿐이라면 기술이 바뀌어도 클라이언트 코드에는 수정이 필요없어진다. 마찬가지로 이 마이크로미터를 사용하면 모니터링 툴이 바뀌든 두개를 사용하든 상관없이 같은 API를 사용해서 지표를 전달할 수 있다.
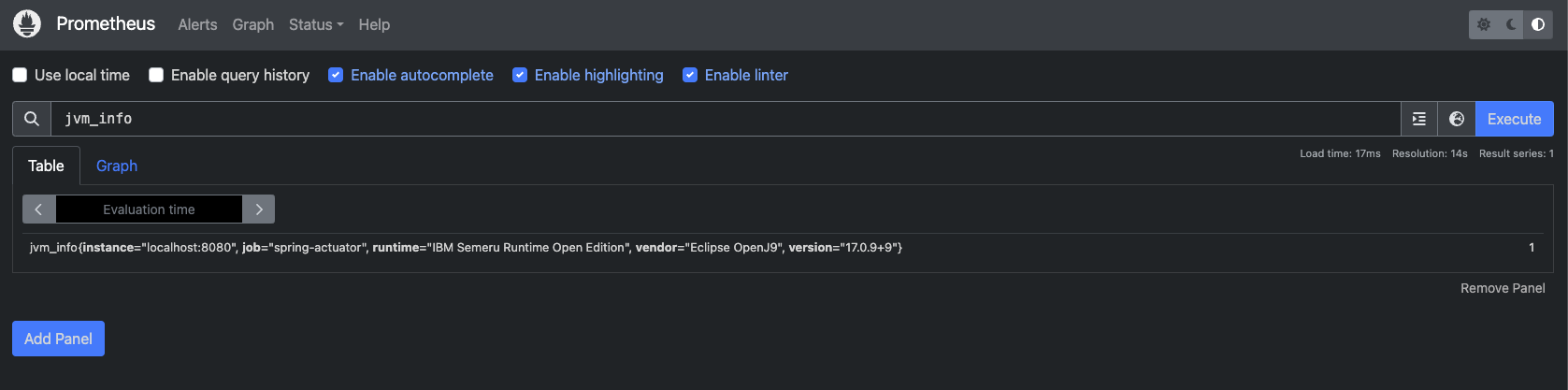
그럼, 모니터링 툴을 사용하기 전에 어떤 지표가 있는지 확인해보자. 이 지표도 역시 스프링 부트의 액츄에이터가 우리를 위해 만들어준다.
액츄에이터를 활성화 시키는 내용은 바로 이 전 포스팅에 있으니 참고하고 이미 활성화되어 있다고 가정하고 시작해보자.
다음 URL에 접속해보자.
`http://yourbaseURL/actuator/metrics`
여기에 접속하면 스프링 부트가 우릴 위해 만들어주는 여러가지 지표가 있다.
보면 disk.free, disk.total, http.server.requests 등 여러 지표들이 있다.
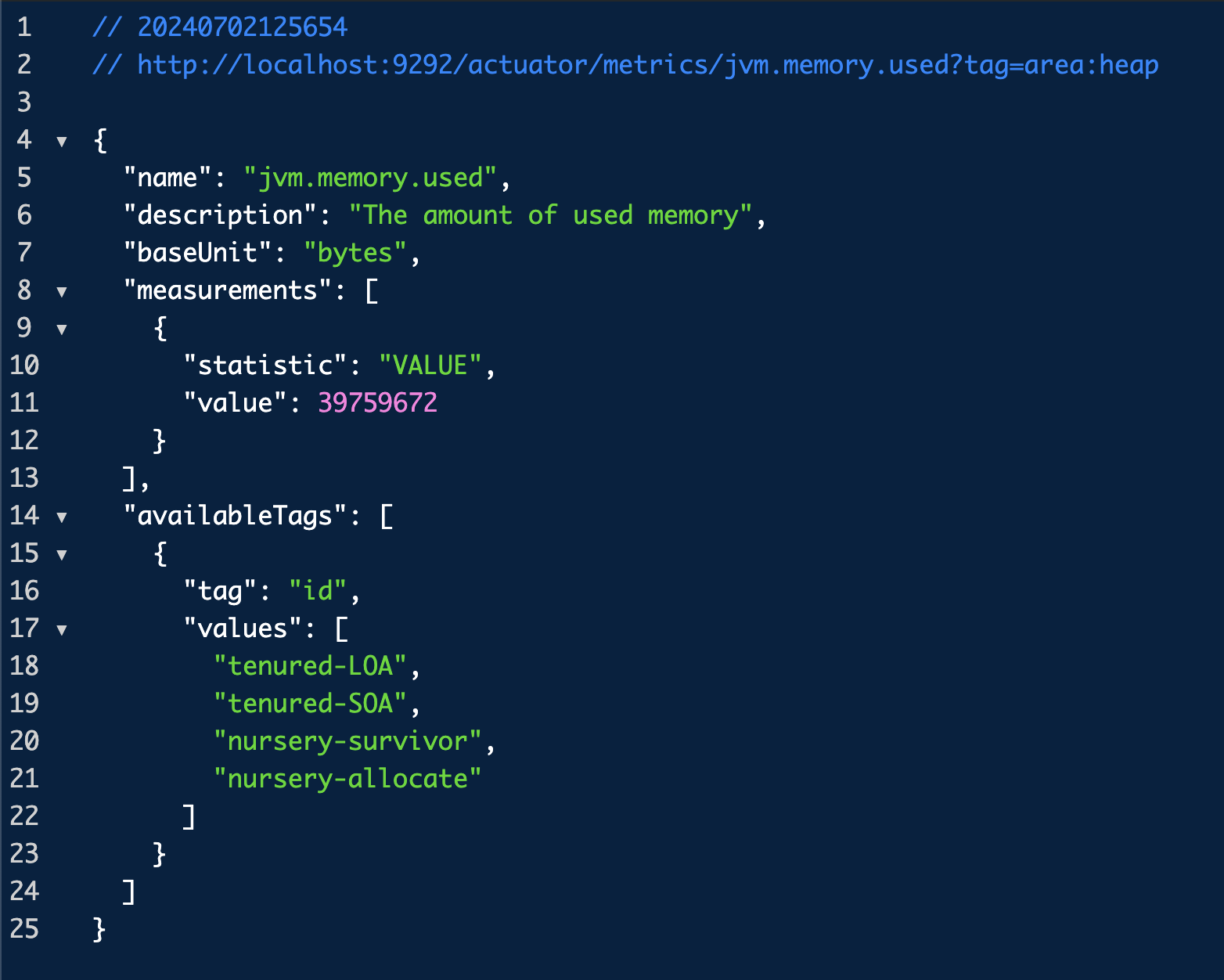
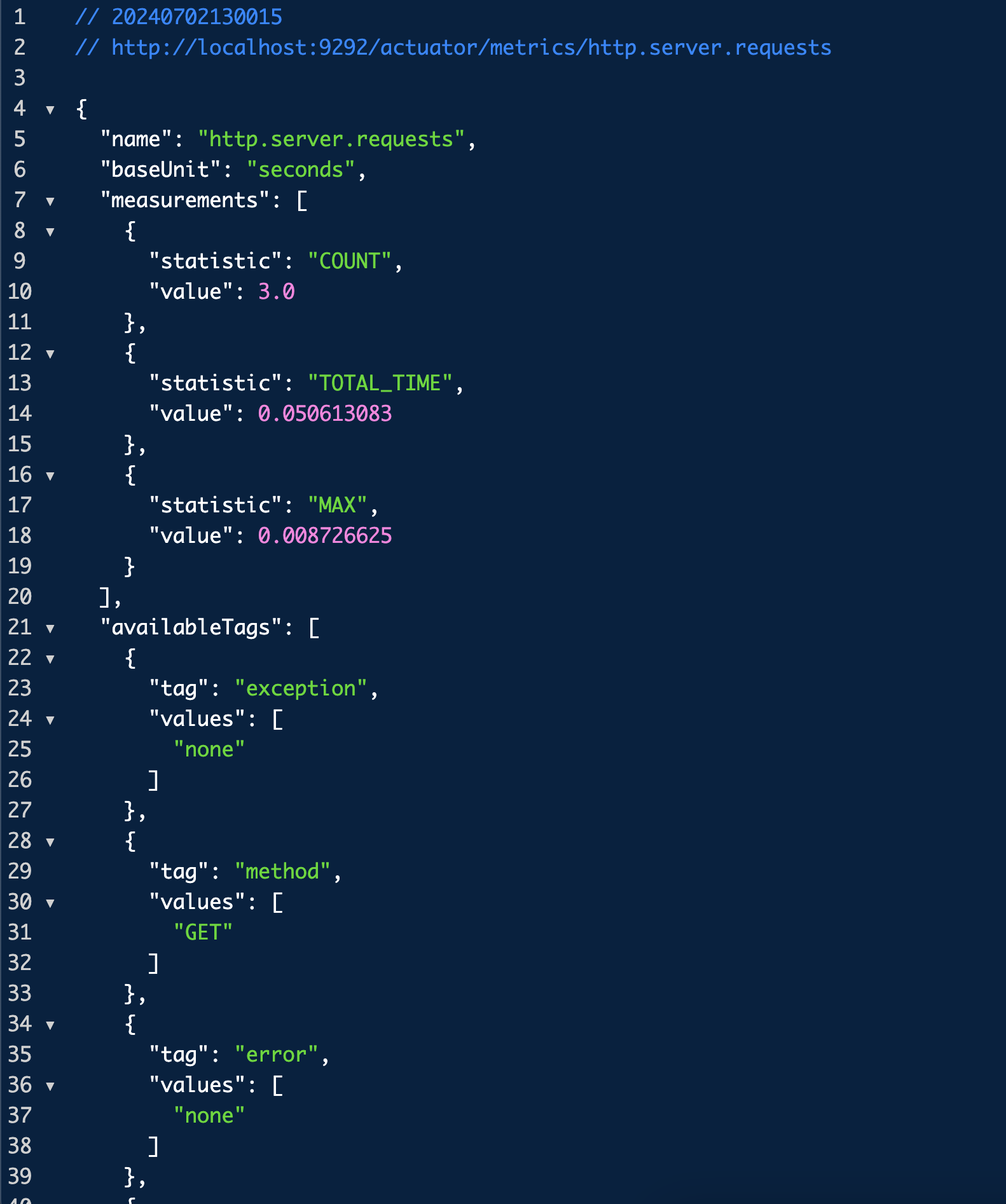
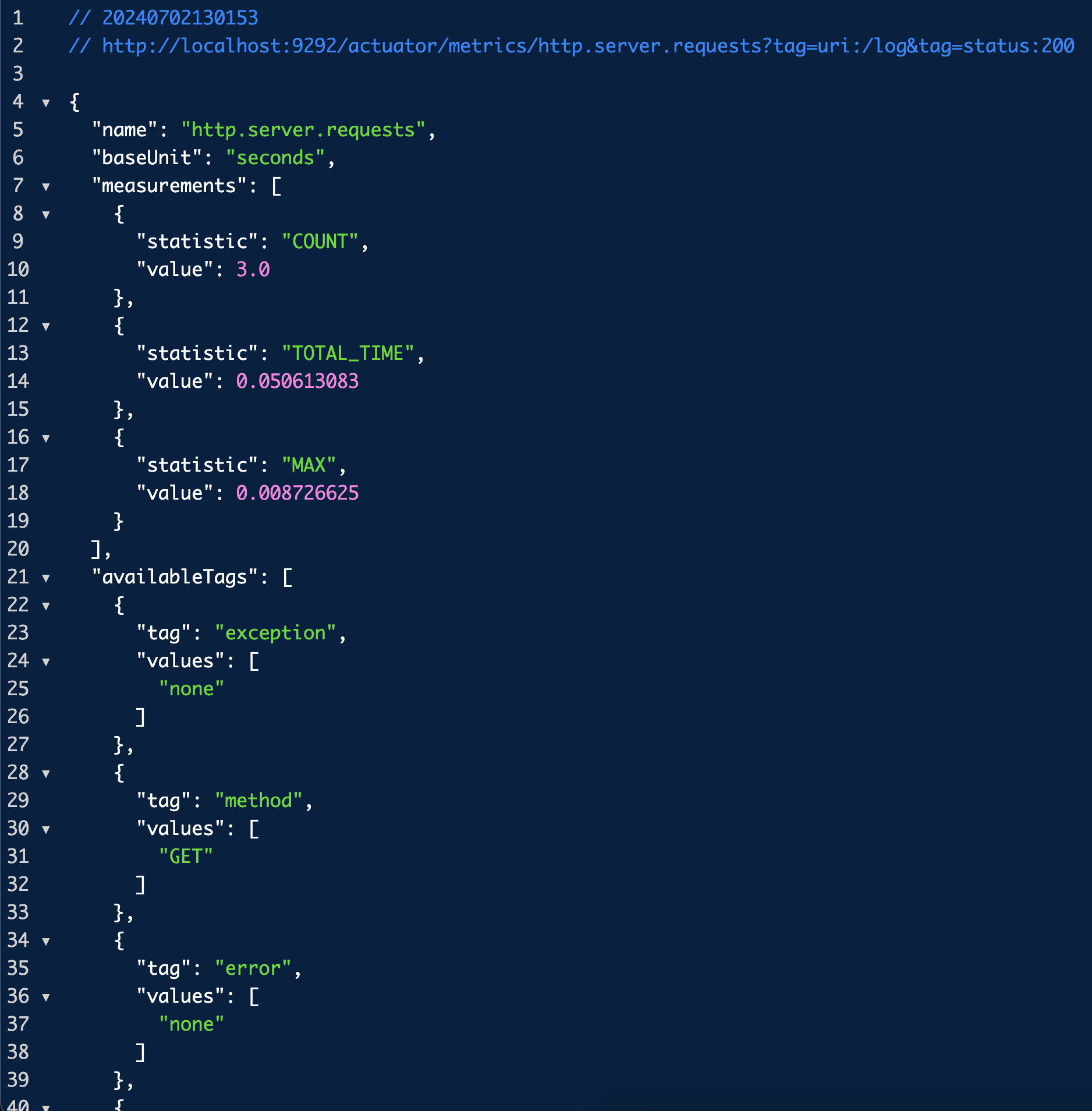
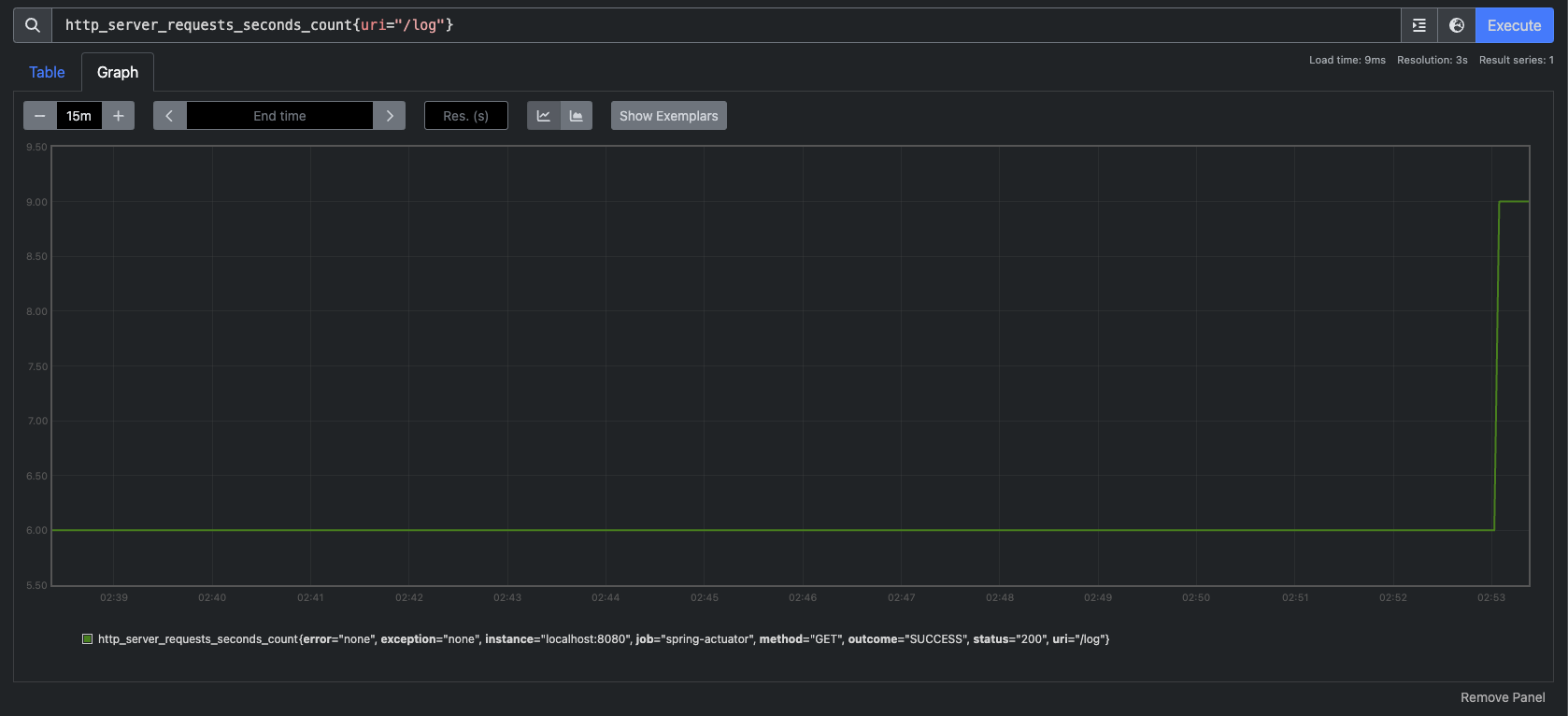
그럼 이 여러 지표들 중 하나를 선택해서 더 자세히 볼 수 있는데 그 방법은 위 URL에 지표까지 넣어주는 것이다.
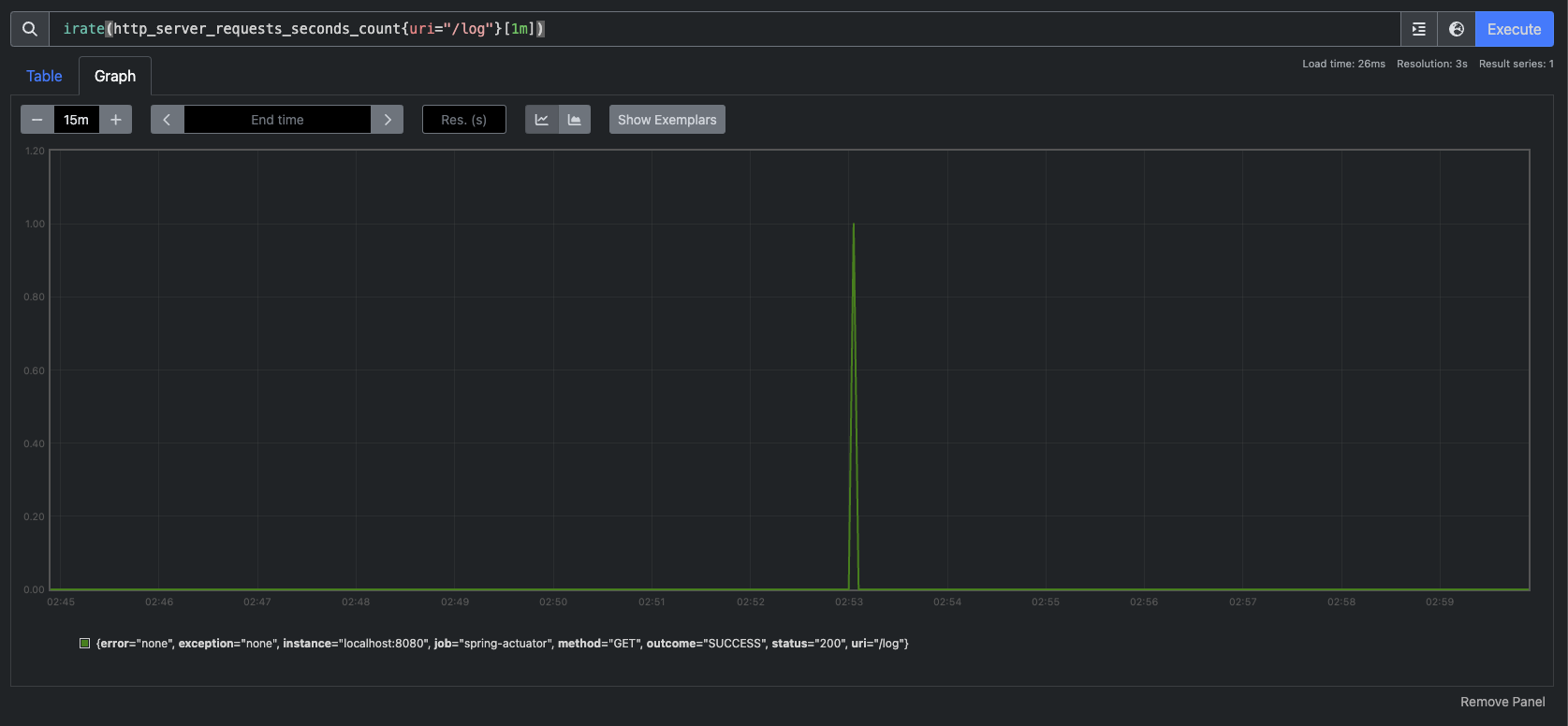
이건 URI가 `/log`이고 응답 코드가 200인 요청에 대해서만 필터링한 메트릭을 보여주는 URL이다.
이렇게 액츄에이터는 여러 모니터링을 위한 지표들을 제공한다. 이 지표들을 이제 모니터링 툴과 연동해서 사용할 수 있어보인다.
그럼 어떤 지표들이 있는지 조금 더 자세하게 알아보자.
마이크로미터와 액츄에이터가 기본으로 제공하는 다양한 메트릭을 확인해보자.
JVM 메트릭
시스템 메트릭
애플리케이션 시작 메트릭
스프링 MVC 메트릭
톰캣 메트릭
데이터 소스 메트릭
로그 메트릭
기타 수 많은 메트릭과 사용자가 직접 정의하는 메트릭
JVM 메트릭
JVM 관련 메트릭을 제공한다. `jvm.`으로 시작한다.
메모리 및 버퍼 풀 세부 정보
가비지 수집 관련 통계
스레드 활용
로드 및 언로드된 클래스 수
JVM 버전 정보
JIT 컴파일 시간
시스템 메트릭
시스템 메트릭을 제공한다. `system.`, `process.`, `disk.`으로 시작한다.
CPU 지표
파일 디스크립터 메트릭
가동 시간 메트릭
사용 가능한 디스크 공간
애플리케이션 시작 메트릭
애플리케이션 시작 시간 메트릭을 제공한다.
application.started.time: 애플리케이션을 시작하는데 걸리는 시간
application.ready.time: 애플리케이션이 요청을 처리할 준비가 되는데 걸리는 시간
스프링은 내부에 여러 초기화 단계가 있고 각 단계별로 내부에서 애플리케이션 이벤트를 발행한다.
ApplicationStartedEvent: 스프링 컨테이너가 완전히 실행된 상태이다. 이후에 커맨드 라인 러너가 호출된다.
ApplicationReadyEvent: 커맨드 라인 러너가 실행된 이후에 호출된다.
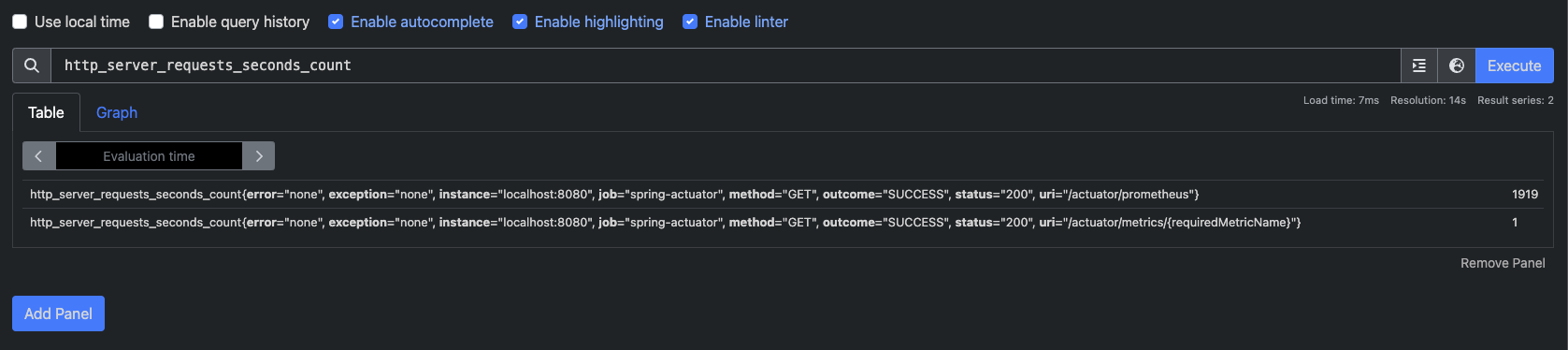
스프링 MVC 메트릭
스프링 MVC 컨트롤러가 처리하는 모든 요청을 다룬다. `http.server.requests`
`tag`를 이용해서 다음 정보를 분류해서 확인할 수 있다.
uri: 요청 URI
method: GET, POST와 같은 HTTP 메서드
status: 200, 400, 500 같은 HTTP Status 코드
exception: 예외
outcome: 상태 코드를 그룹으로 모아서 확인 (1xx: INFORMATIONAL, 2xx: SUCCESS, 3xx: REDIRECTION, 4xx: CLIENT_ERROR, 5xx: SERVER_ERROR)
데이터소스 메트릭
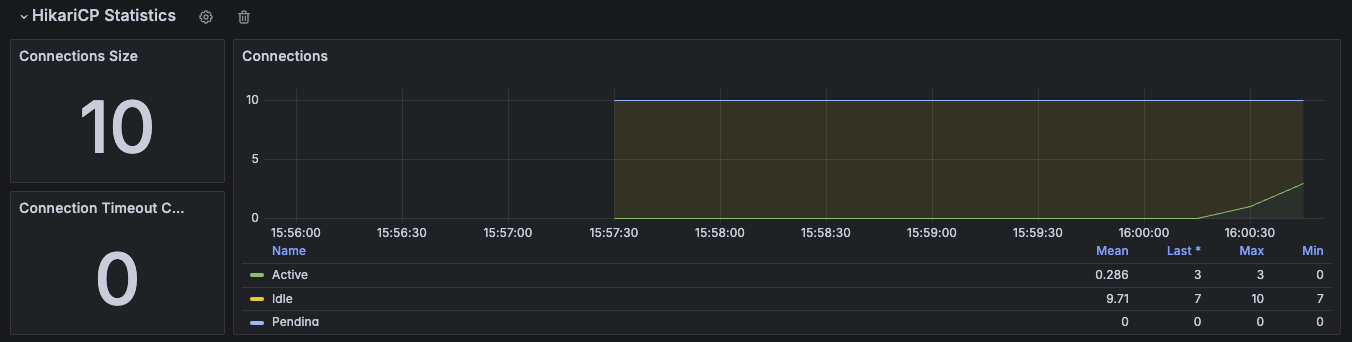
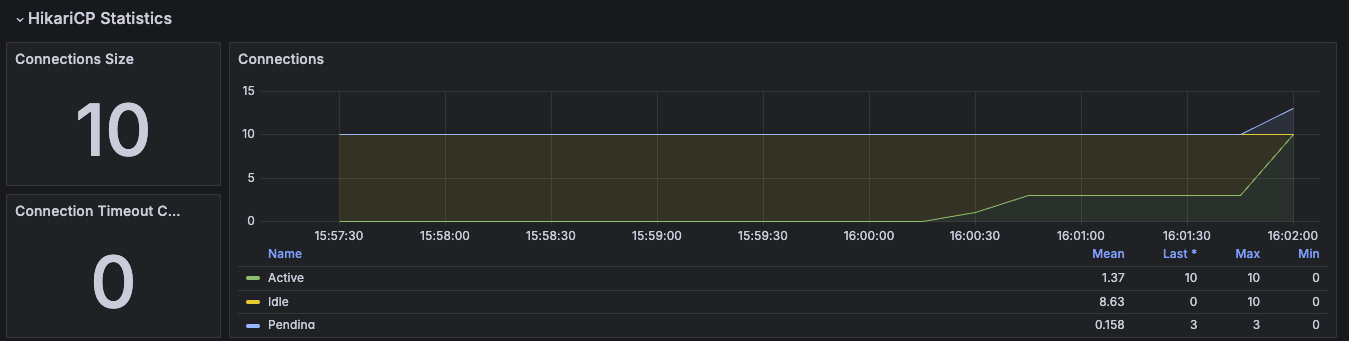
DataSource, 커넥션 풀에 관한 메트릭을 확인할 수 있다. `jdbc.connections.`로 시작한다.
최대 커넥션, 최소 커넥션, 활성 커넥션, 대기 커넥션 수 등을 확인할 수 있다.
히카리 커넥션 풀을 사용하면 `hikaricp.`를 통해 히카리 커넥션 풀의 자세한 메트릭을 확인할 수 있다.
로그 메트릭
logback.events: logback 로그에 대한 메트릭을 확인할 수 있다.
trace, debug, info, warn, error 각각의 로그 레벨에 따른 로그 수를 확인할 수 있다.
예를 들어서 `error` 로그 수가 급격히 높아진다면 위험한 신호로 받아들일 수 있다.
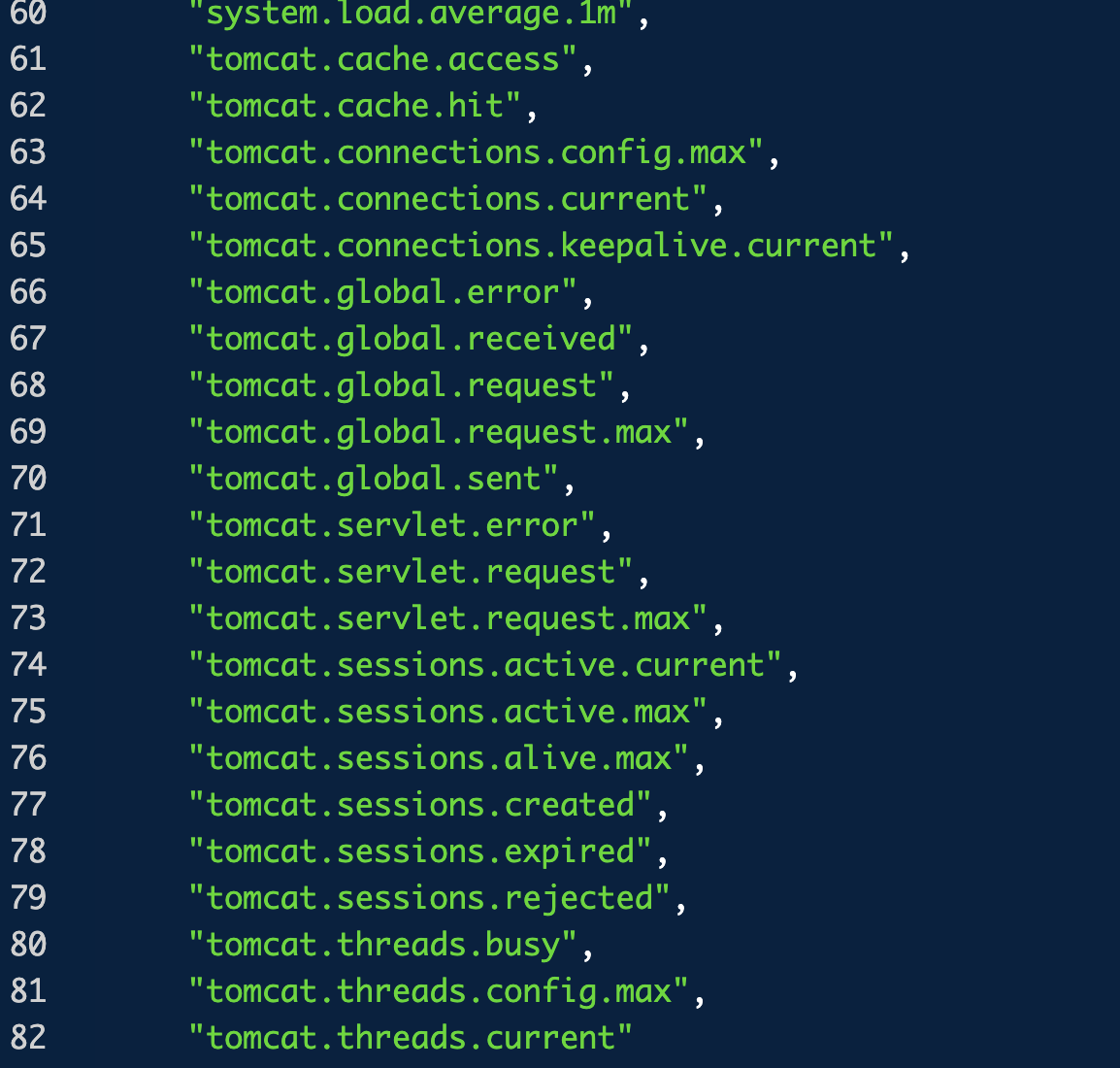
톰캣 메트릭
톰캣 메트릭은 `tomcat.`으로 시작한다. 톰캣 메트릭을 모두 사용하려면 다음 옵션을 켜야한다. (옵션을 켜지 않으면 `tomcat.session.`관련 정보만 노출된다.
application.yml
server:
tomcat:
mbeanregistry:
enabled: true
이 옵션을 키면 다음과 같이 `tomcat.session.`외에도 `tomcat.xxx.` 메트릭도 제공이 된다.
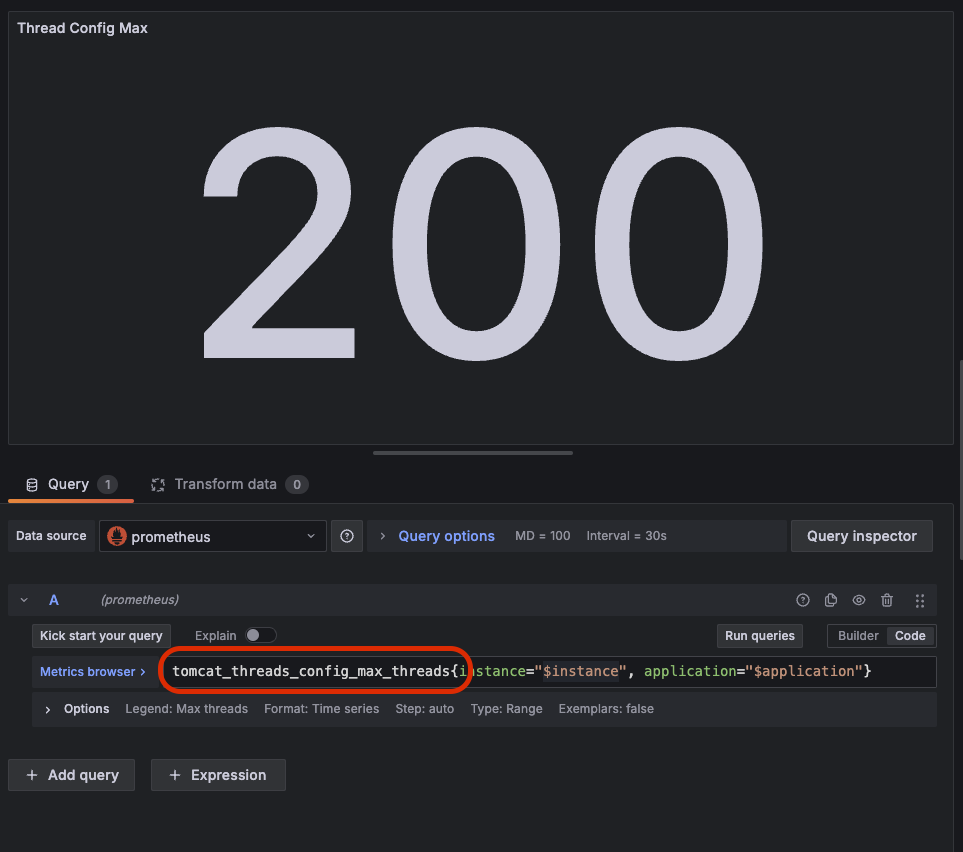
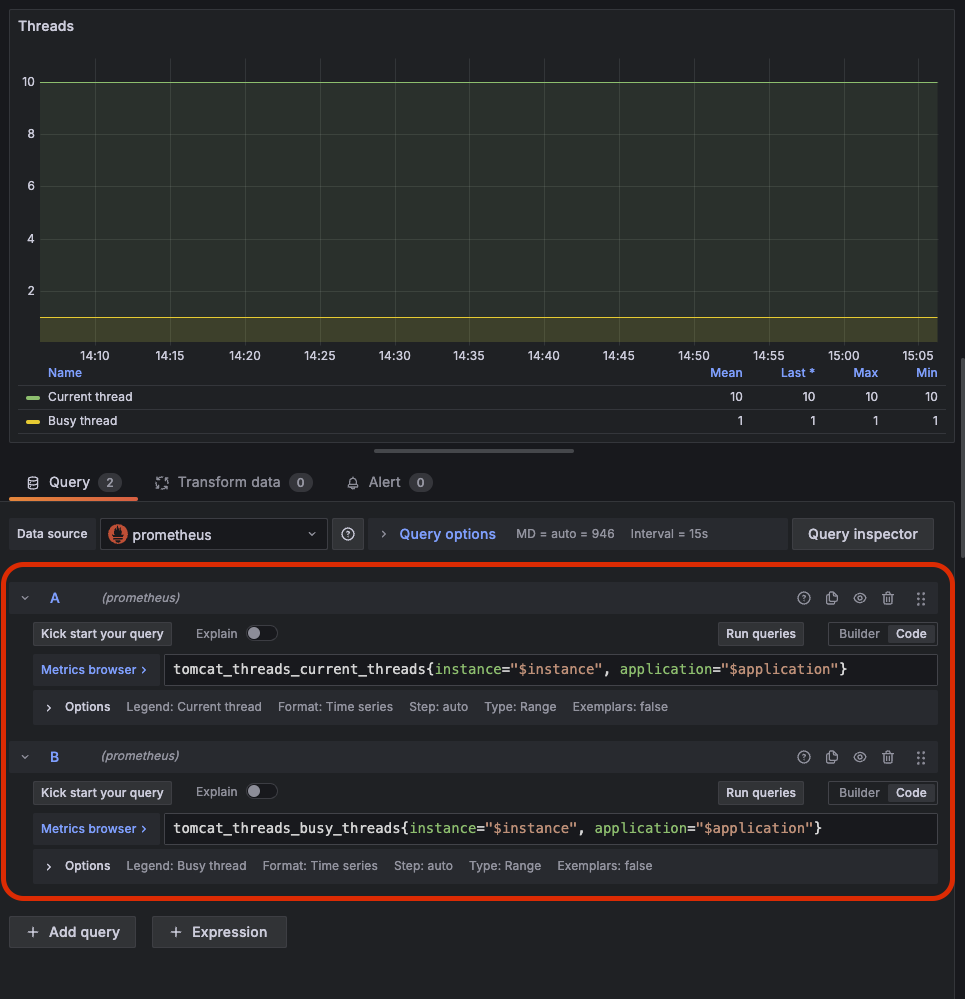
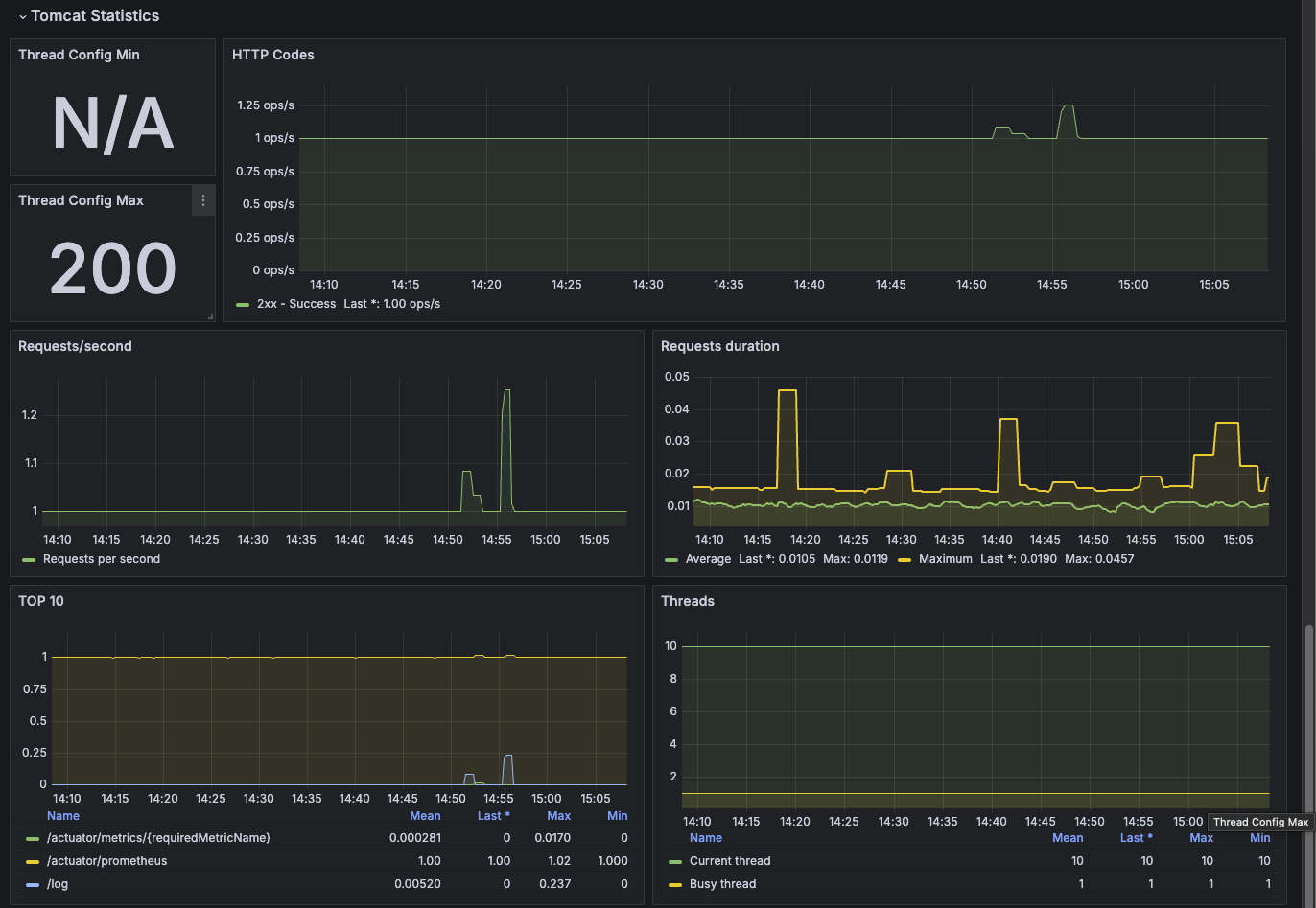
예를 들어, `tomcat.threads.config.max` 메트릭은 톰캣이 제공하는 쓰레드의 최대 개수를 보여준다. 그리고 현재 사용중인 쓰레드 수는 `tomcat.threads.current`로 확인할 수 있다.
기타 메트릭
HTTP 클라이언트 메트릭(RestTemplate, WebClient)
캐시 메트릭
작업 실행과 스케쥴 메트릭
스프링 데이터 레포지토리 메트릭
몽고DB 메트릭
레디스 메트릭
사용자 정의 메트릭
사용자가 직접 메트릭을 정의할 수도 있다. 예를 들어서 주문수, 취소수를 메트릭으로 만들 수 있다.
사용자 정의 메트릭을 만들기 위해서는 마이크로미터의 사용법을 먼저 이해해야 한다. 이 부분은 뒤에서 다룬다.
중간 정리
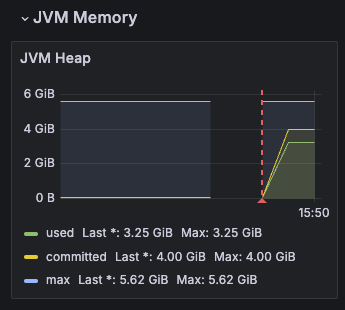
액츄에이터를 통해서 수많은 메트릭이 자동으로 만들어지는 것을 확인했다. 그런데 이러한 메트릭들을 어딘가에 지속해서 보관해야 과거의 데이터들도 확인할 수 있을것이다. 따라서 메트릭을 지속적으로 수집하고 보관할 데이터베이스가 필요하다. 그리고 이러한 메트릭들을 그래프를 통해서 한눈에 쉽게 확인할 수 있는 대시보드도 필요하다.
메트릭의 데이터베이스: 프로메테우스
애플리케이션에서 발생한 메트릭을 그 순간만 확인하는 것이 아니라 과거 이력까지 함께 확인하려면 메트릭을 보관하는 DB가 필요하다.
이렇게 하려면 어디선가 메트릭을 지속해서 수집하고 DB에 저장해야 한다. 프로메테우스가 바로 이런 역할을 담당한다.
그럼 그라파나는?
프로메테우스가 DB라고 하면, 이 DB에 있는 데이터를 불러서 사용자가 보기 편하게 보여주는 대시보드가 필요한데 그라파나는 매우 유연하게 데이터를 그래프로 보여주는 툴이다. 수 많은 그래프를 제공하고 프로메테우스를 포함한 다양한 데이터소스를 지원한다.
어떤 흐름으로 데이터를 보관하고 대시보드에 보여주는지는 다음과 같다.
스프링 부트 액츄에이터와 마이크로미터를 사용하면 수 많은 메트릭을 자동으로 생성한다.
마이크로미터 프로메테우스 구현체는 프로메테우스가 읽을 수 있는 포맷으로 메트릭을 생성한다.
프로메테우스는 이렇게 만들어진 메트릭을 지속해서 수집한다.
프로메테우스는 수집한 메트릭을 내부 DB에 저장한다.
사용자는 그라파나 대시보드 툴을 통해 그래프로 편리하게 메트릭을 조회한다. 이때 필요한 데이터는 프로메테우스를 통해서 조회한다.
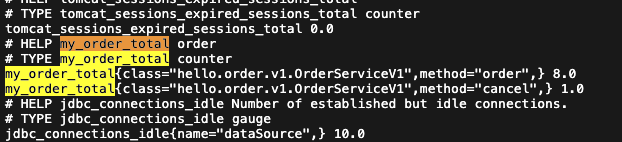
태그, 레이블: 위 결과에서 `error`, `exception`, `instance`, `job`, `method`, `outcome`, `status`, `uri`는 각각의 메트릭 정보를 구분해서 사용하기 위한 태그이다. 마이크로미터는 이를 태그라고 하고 프로메테우스는 레이블이라고 한다.
숫자: 끝에 마지막에 보면 1919, 1 이런 값이 보인다. 이게 바로 해당 메트릭의 값이다.
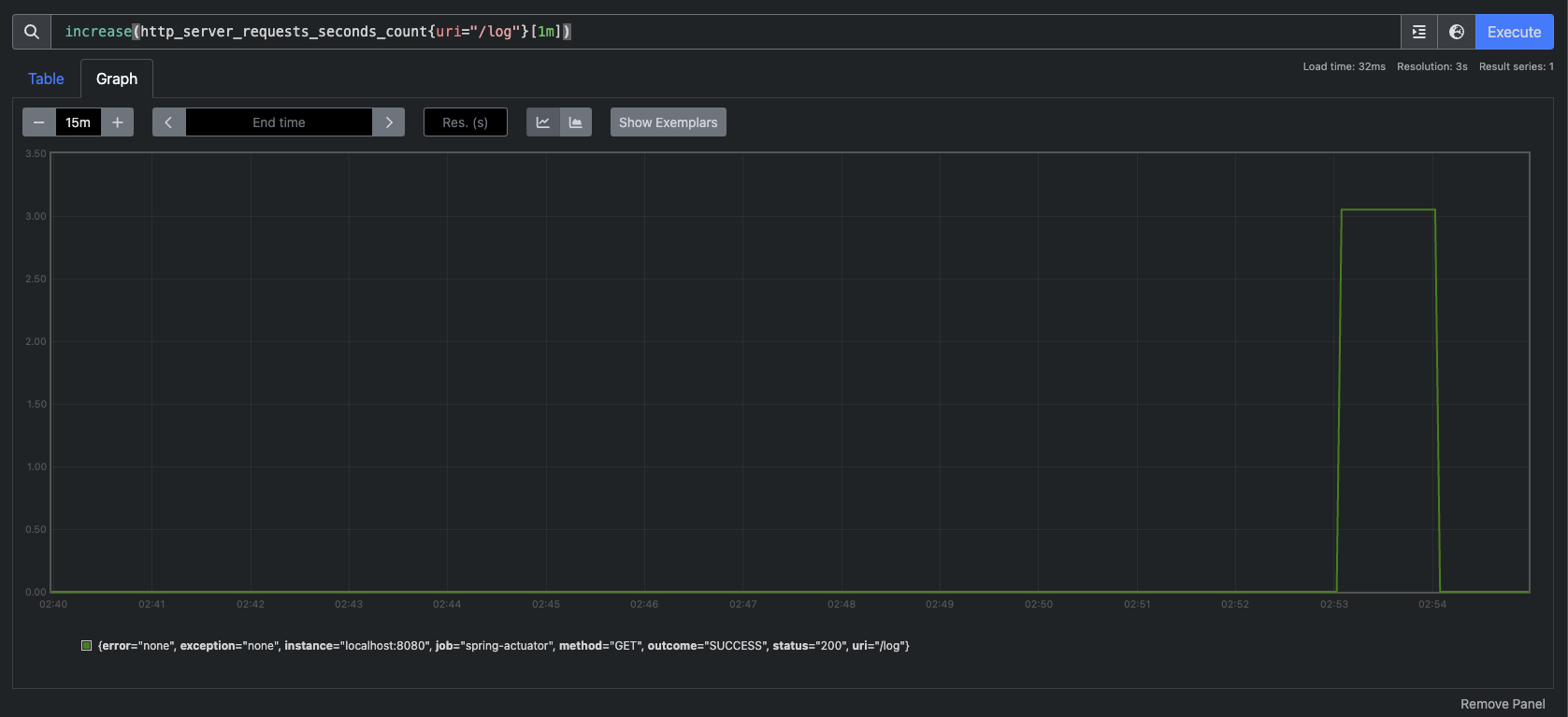
보이는것처럼 특정 시간에 사용자 요청이 급격하게 올라가고 특정 시간에 급격하게 내려가는 것을 확인할 수 있다.
이와 비슷하게 rate()라는 것도 있는데, 이건 비율로 보여주는 거고 increase()는 정적인 숫자로 결과를 보여주는 것이라고 보면 된다.
irate()도 있는데 irate()는 rate()와 유사한데 범위 벡터에서 초당 순간 증가율을 계산한다. 급격하게 증가한 내용을 확인하기 좋다.
irate() 그래프
정리
게이지는 값이 계속 변하는, 오르락 내리락하는 값을 그래프로 표현한다. 카운터는 값이 단조롭게 증가하는 카운터는 increase(), rate()등을 사용해서 표현하면 된다. 이렇게 하면 카운터에서 특정 시간에 얼마나 고객의 요청이 들어왔는지 확인할 수 있다. 그러나, 프로메테우스의 단점은 한눈에 들어오는 대시보드를 만들어보기 어렵다는 점이다. 위에서도 뭔가 보기 위해 계속 지표를 변경하고, 시간을 바꾸고 등등의 수작업이 들어가는데 이런 부분을 그라파나로 해결할 수 있다.
설치를 다 마치면 `/bin` 폴더에 들어가야 한다. 들어가면 `grafana-server` 라는 실행 파일이 있다. 실행하자.
실행하면 쭉 로그가 찍히는데 대략 이렇게 생겼다.
잘 실행됐는지 확인하려면 `localhost:3000` 으로 들어가보자. 그라파나는 기본 포트가 3000이다.
최초 접속 정보는 `admin/admin` 이다. 추후에 변경할 수 있다.
로그인에 성공하면 다음과 같은 화면이 보일것이다.
그라파나 - 프로메테우스 연동
이제 프로메테우스로부터 데이터를 받아 그라파나에 데이터를 대시보드로 이쁘게 보여주자.
그러려면 우선 다음이 실행중이어야 한다.
애플리케이션 서버
프로메테우스 서버
그라파나 서버
그리고 연동하기 위해 좌측 사이드바에 Connections > Data sources를 클릭한다.
그럼 다음과 같은 화면이 나온다. Add data source 클릭
그럼 바로 앞에 프로메테우스가 보여진다. 클릭.
커넥션 주소를 넣어줘야 한다. 프로메테우스는 9090으로 띄워져 있다.
나머지는 필요없다. 최하단에 Save & test 버튼 클릭
잘 연동되면 다음과 같은 화면이 보인다.
그라파나 대시보드 만들기
이제 연동도 했으니 대시보드를 만들어보자. 좌측 사이드바에 Dashboards 클릭
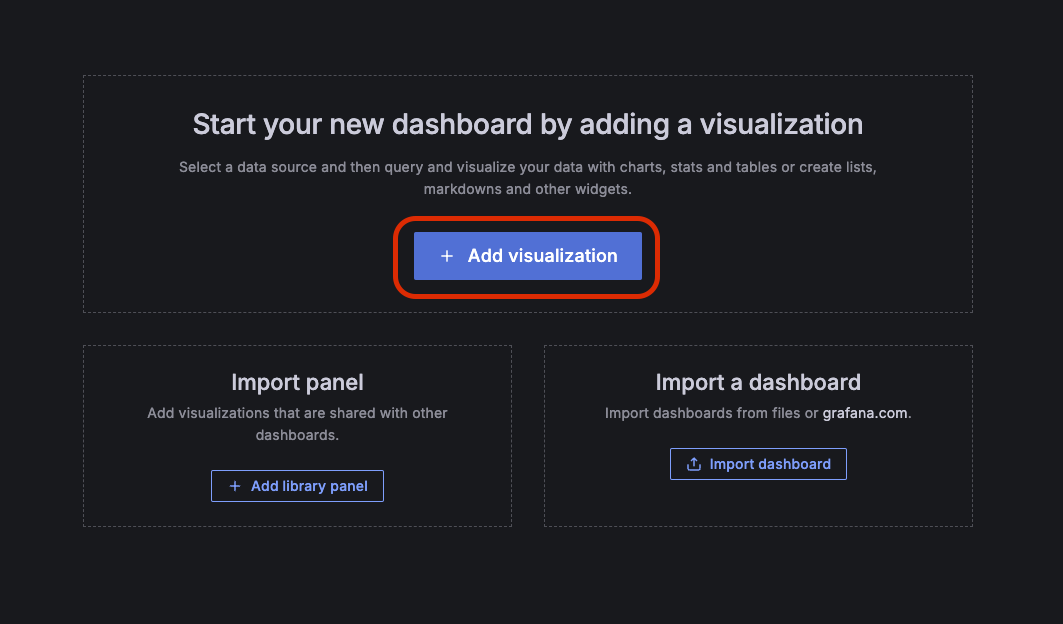
그럼 이러한 화면이 보여진다. New > New dashboards 버튼 클릭
클릭하면 화면이 하나 보일텐데 우선 Save 버튼을 눌러서 대시보드를 저장하자.
그 다음 다시 처음 화면으로 돌아가서 + Add visualization 버튼 클릭
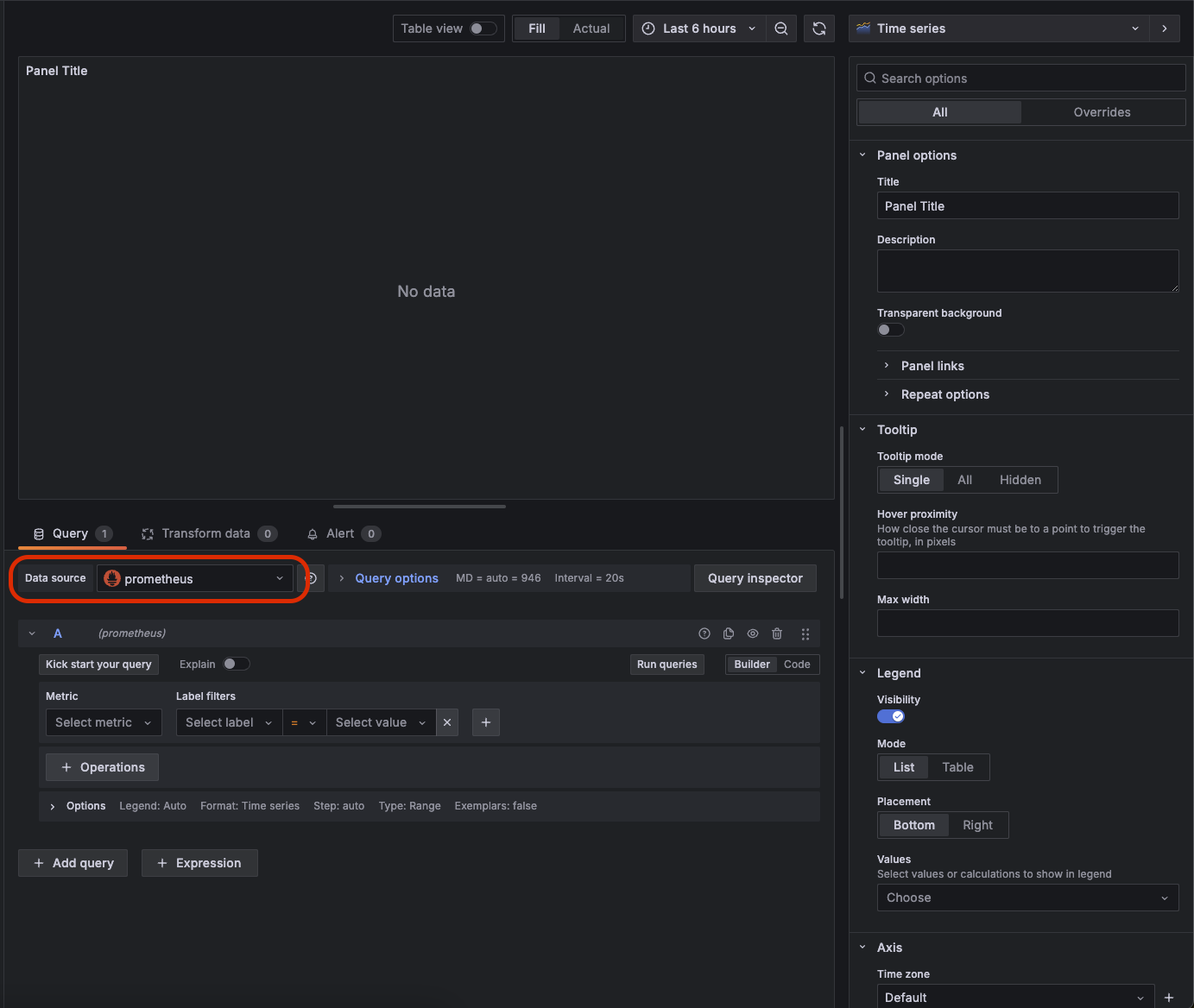
그럼 아래와 같은 화면이 보여진다. 여기서 가장 먼저 확인할 건 Datasource가 프로메테우스로 잘 되어 있는지 확인하자.
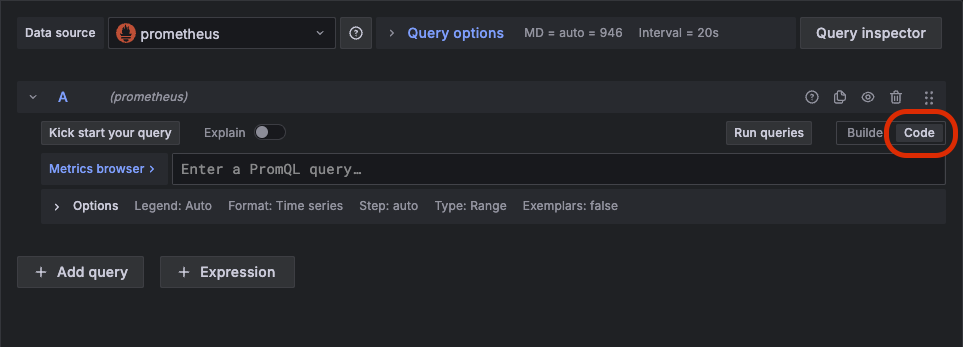
그 다음 그 하단에 쿼리를 날려서 데이터를 프로메테우스로부터 가져온다. 그러기 위해 우선 Builder 대신 Code를 선택하자.
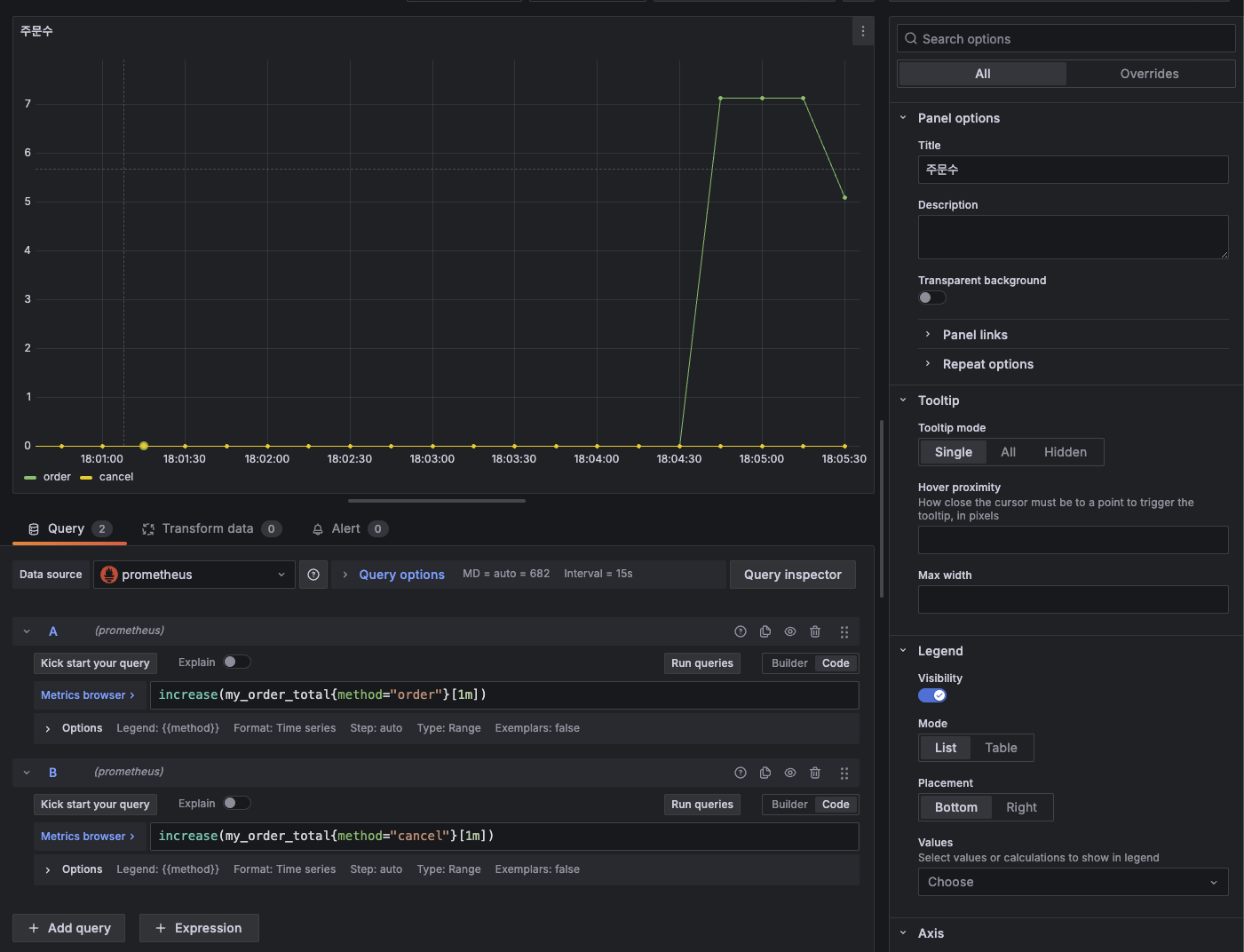
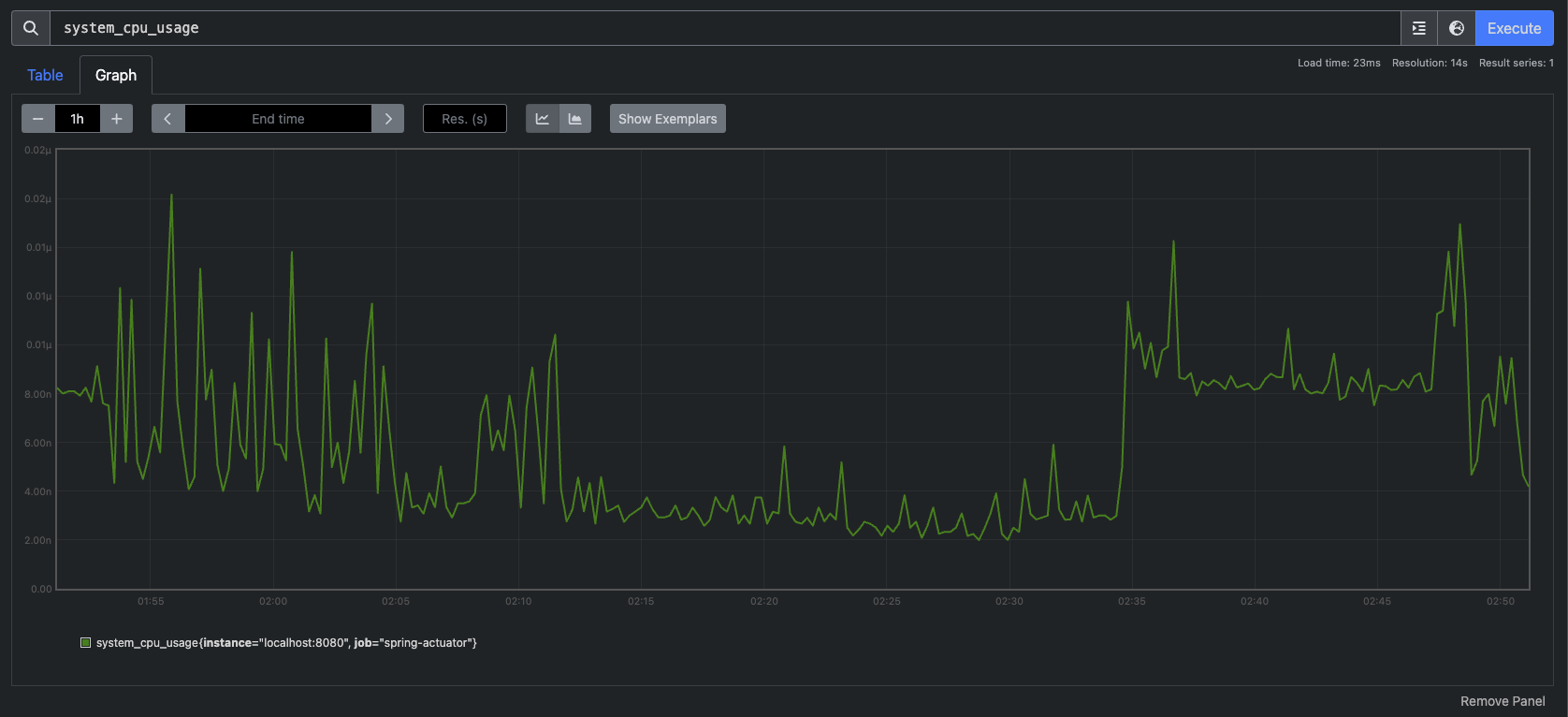
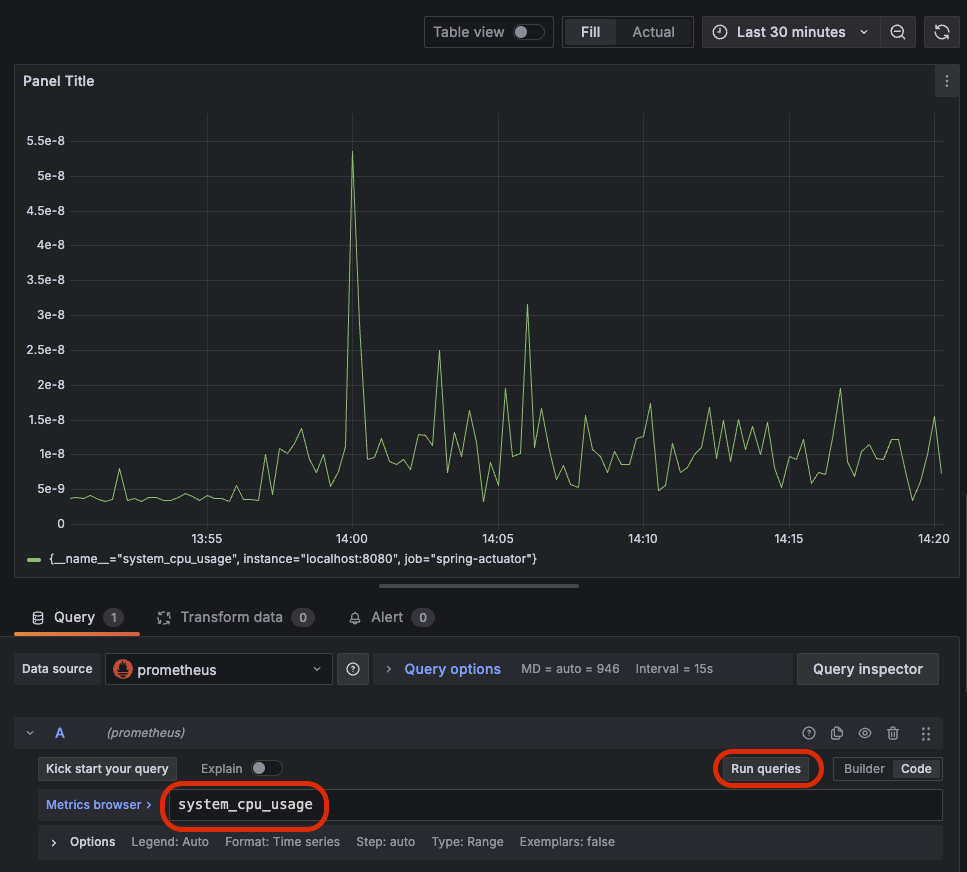
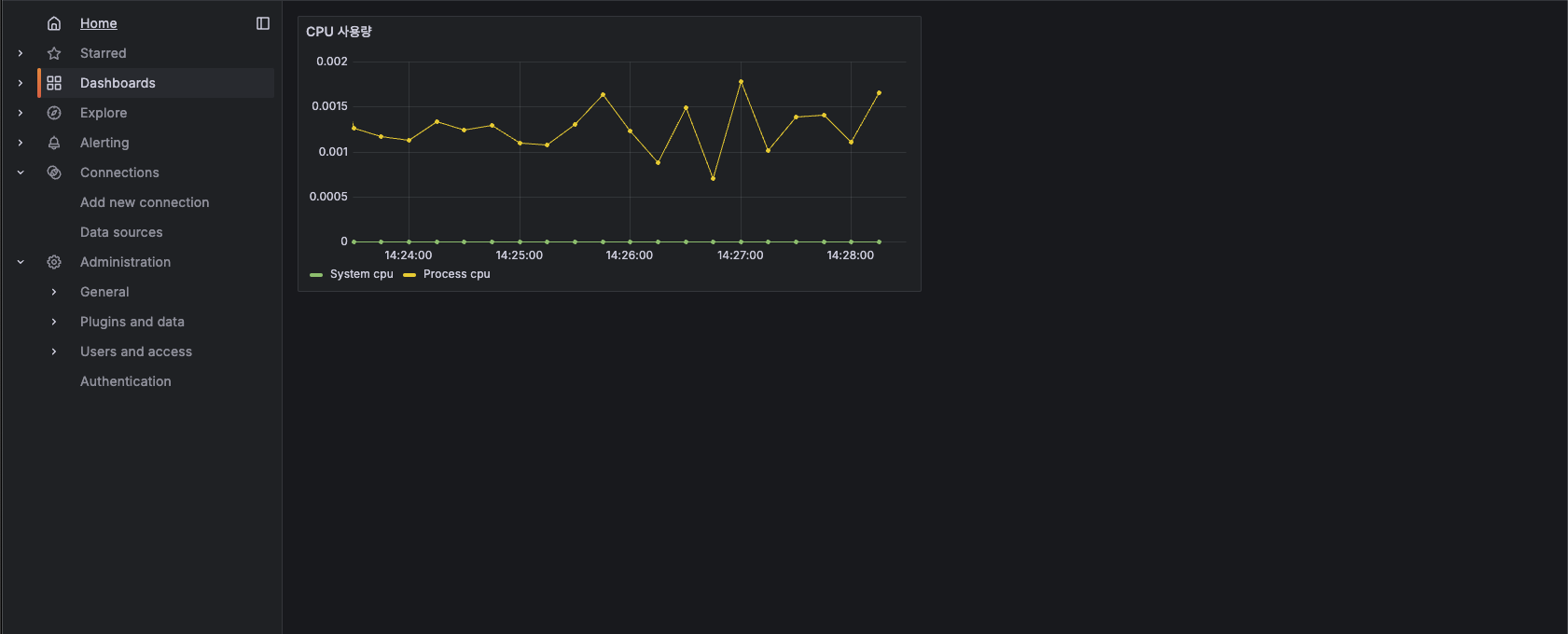
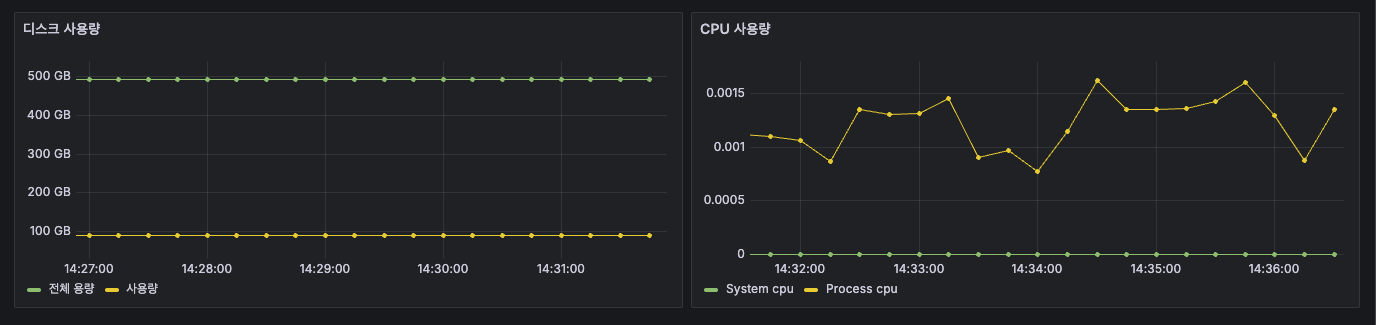
가장 간단한 CPU 사용량을 확인해보자. 하단 사진처럼 `system_cpu_usage`을 입력하고 Run queries 버튼 클릭
그럼 위처럼 데이터를 가져와서 차트로 보여준다. 여기에 한 가지 지표를 더 추가하자.
하단에 + Add query 버튼 클릭
`process_cpu_usage`를 입력하고 Run queries 버튼을 클릭하면 두 지표가 동시에 보여진다.
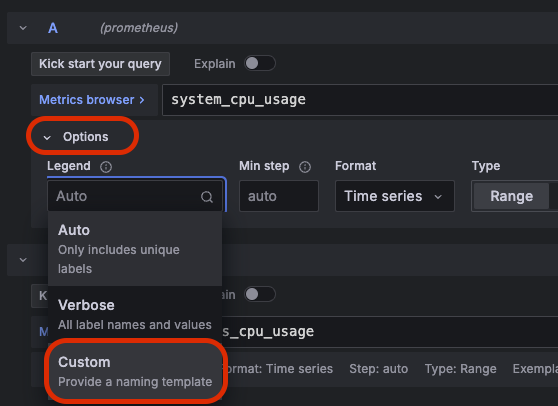
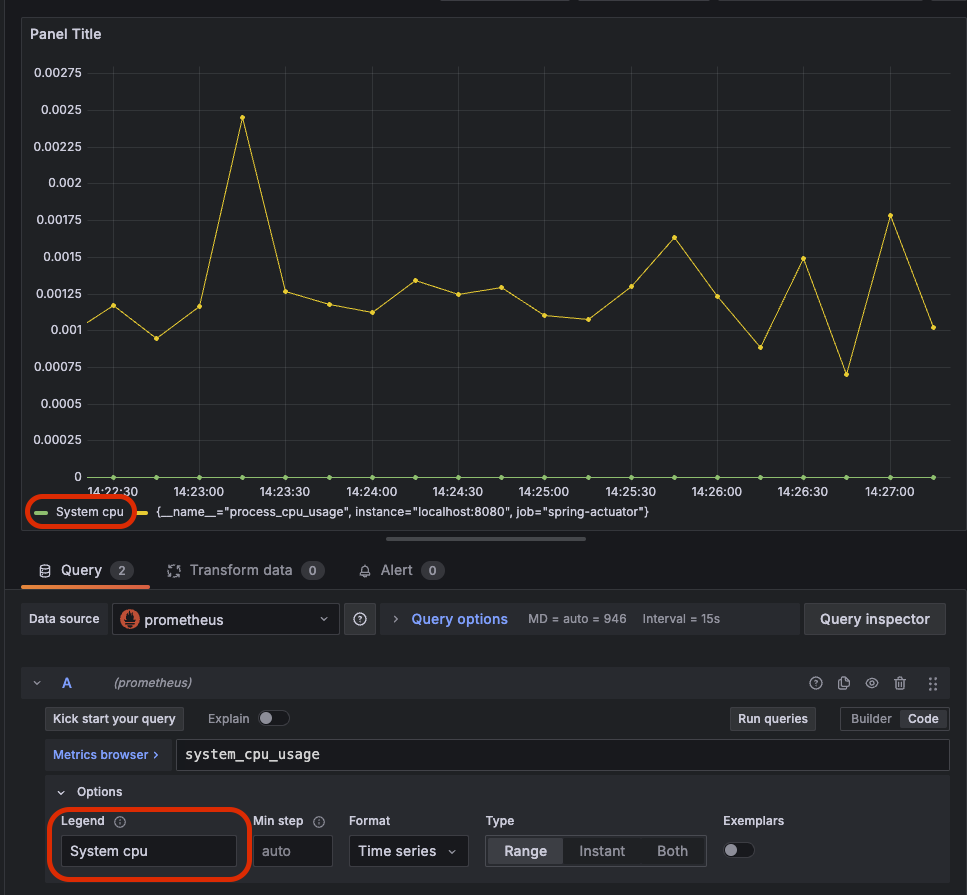
그럼 보자. 두 지표가 동시에 이쁘게 잘 나온다. 상대적으로 System CPU는 거의 잡아먹지 않고 Process CPU가 좀 더 많이 사용중인걸 한 눈에 볼 수 있다. 근데 보여지는 이름이 맘에 들지 않는다. 그래서 이름을 좀 더 간결하게 바꿔주자. 아래 사진처럼 특정 지표에 하단 Options 버튼을 클릭하면 Legend라는 단어가 보인다. 이걸 범례라고도 하는데 이 값을 Custom으로 변경해주자.
그런 다음 값을 "System cpu"로 입력해주면 다음과 같이 화면에 보이는 값이 변경된다.
마찬가지로 Process cpu도 적용해주자. 그런 다음 이 패널의 제목을 다음과 같이 변경해주자.
다 했으면 우측 상단에 Apply 버튼 클릭. 그럼 이렇게 보여진다.
대시보드 만드는 거 어렵지 않다. 깔끔하게 잘 만들었다! 하나 더 만들어보자.
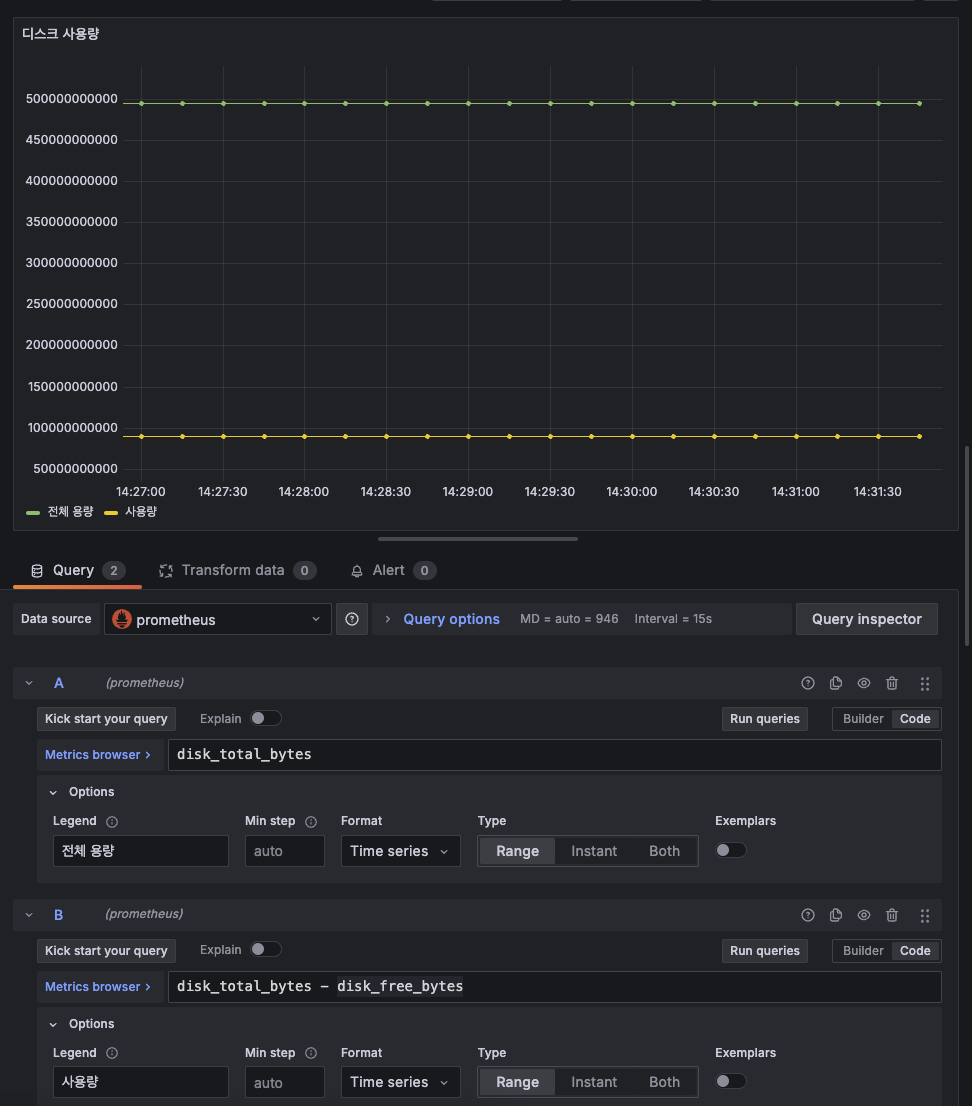
이번엔 디스크 사용량을 추가해보자. 이젠 여기까지 직접 할 수 있다.
두 개의 쿼리가 있는데, 하나는 전체 용량이고 하나는 전체 용량에서 여유 용량을 뺀 즉, 사용량이다.
이런식으로 연산도 가능하다.
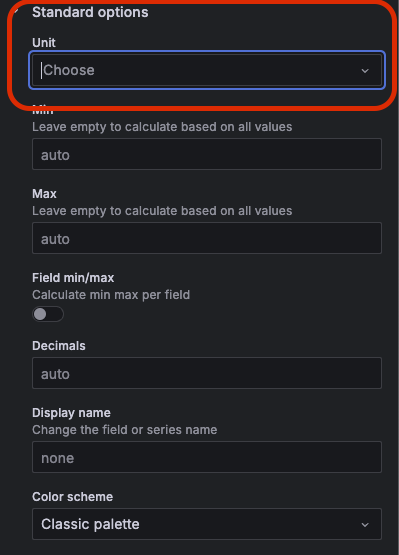
근데, 다 좋은데 좌측에 값이 바이트 값으로 나와있어서 보기가 어렵다. 사람이 보기 편하게 바꾸고 싶은데 이럴땐 우측에 보면
Standard options > Unit 이것을 수정해주면 된다. Data > bytes(SI)로 수정해보자.
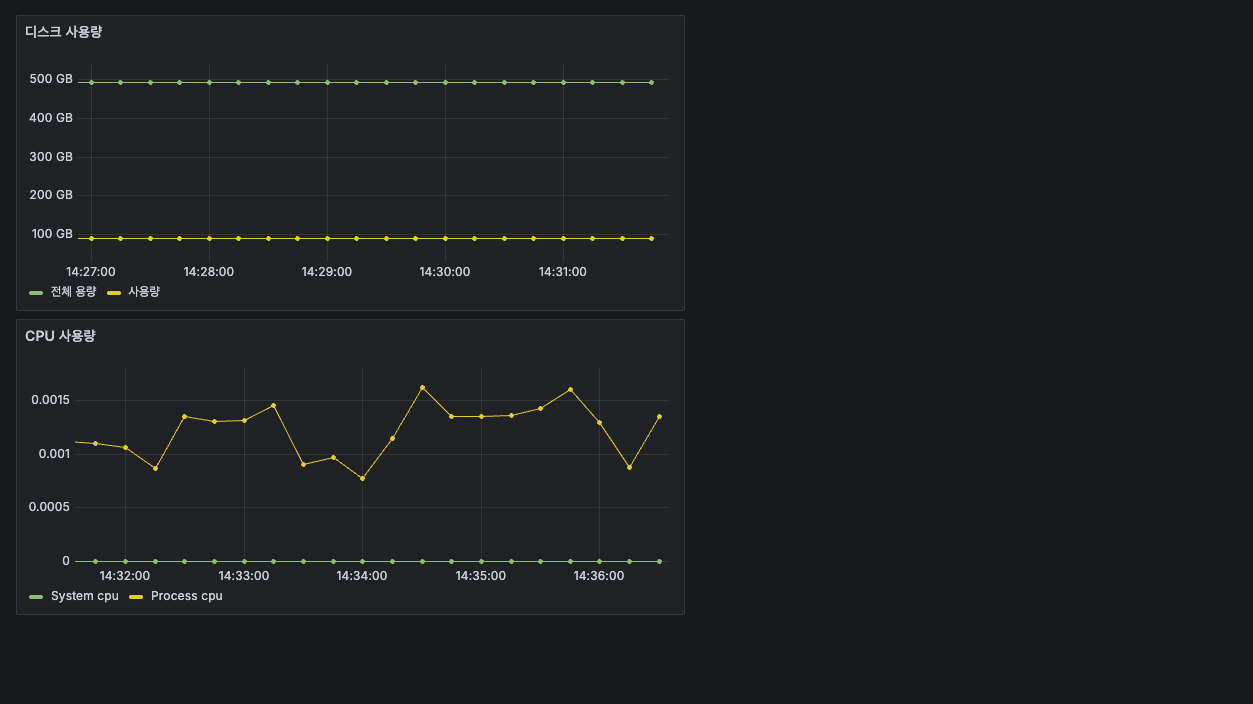
그럼 아래와 같이 깔끔하게 보여진다.
그리고 또 저장하자. 그럼 이렇게 잘 보여진다.
드래그로 이쁘게 한 줄로 만들어보자.
이렇게 이쁘게 하나하나 꾸며서 만들면 이제 시각적으로 메트릭 정보를 얻을 수 있게 됐다.
근데, 프로젝트 할 때마다 이렇게 하나 하나 만드는 것도 여간 귀찮은 일이 아니다. 그러면? 이미 만들어둔 대시보드를 가져다가 사용할 수 있는 기능을 제공한다. 그것도 아주 잘 만들어 놓은. 그것을 사용해보자.
그래서 실제 저기서 알려주는 health, caches, conditions 등등 여러 종류의 URL로 접속해보면 현재 스프링 부트의 서버 정보 관련된 내용이 나온다.
엔드포인트 설정하기
엔드포인트를 사용하려면 다음 2가지 과정이 모두 필요하다.
엔드포인트 활성화
엔드포인트 노출
엔드포인트를 활성화 한다는 것은 해당 기능 자체를 사용할지 말지 on, off를 선택하는 것이다.
엔드포인트를 노출하는 것은 활성화된 엔드포인트를 HTTP에 노출할지 아니면 JMX에 노출할지 선택하는 것이다. 엔드포인트를 활성화하고 추가로 HTTP를 통해서 웹에 노출할지, 아니면 JMX를 통해서 노출할지 두 위치에 모두 노출할지 노출 위치를 지정해주어야 한다.
물론 활성화가 되어 있지 않으면 노출도 되지 않는다. 그런데 엔드포인트는 대부분 기본으로 활성화 되어 있다. (shutdown 제외) 노출이 되어 있지 않을 뿐이다. 따라서 어떤 엔드포인트를 노출할지 선택하면 된다. 참고로 HTTP와 JMX를 선택할 수 있는데, 보통 JMX는 잘 사용하지 않으므로 HTTP에 어떤 엔드포인트를 노출할지 선택하면 된다.
이 정보가 은근히 아주 쏠쏠하게 도움이 많이 되는데 예를 들면 DB 상태, 디스크 상태 등 여러 유용한 정보를 보여주기 때문에 이 기능을 잘 사용하면 좋다. 기본으로는 별 정보가 안나온다. 근데 다음과 같이 show-details 옵션을 always로 변경하면 더 자세한 정보를 출력해준다.
이렇게 설정해 둔 채로 `/actuator/health` 로 이동해보면 다음과 같이 보여진다.
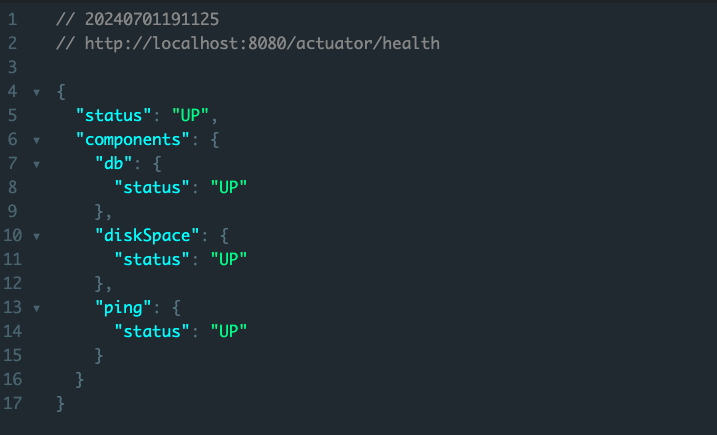
우선, 첫번째 status는 UP 또는 DOWN을 표시할 수 있는데, 아래 components 목록 중 하나라도 DOWN이라면 저 status는 DOWN이 된다. DB의 헬스 상태를 확인을 어떻게 할까? 예전에는 실제로 디비에 더미 쿼리를 날려서 날린 쿼리를 잘 응답하는지 알아봤는데 요새는 디비의 상태 체크를 해주는 옵션 자체가 디비마다 있다. 그래서 그 방식으로 헬스 체크를 하고, 정상 응답을 받으면 다음과 같이 UP 상태로 띄워지게 된다.
그래서 만약에 이 정보를 보고 DB가 DOWN인 상태라면 어? 이 애플리케이션 또는 이 서버의 디비가 현재 맛이 갔네? 라는 사실을 빠르게 인지할 수 있고 그에 따른 대응도 당연히 빨라질 수 밖에 없다. 이 DB상태가 DOWN이 되면 알림을 보내는 기능을 구현할수도 있고 여러 방법을 통해서 말이다.
저런 세부적인 내용까지 볼 필요없고 그냥 상태가 UP인지 DOWN인지만 보고 싶으면 다음과 같이 show-components를 always로 설정하면 된다.
그래서, 이 JSON 데이터를 대시보드로 이쁘게 꾸밀수도 있고, 알림 설정을 해놔서 상태가 DOWN이 되면 곧바로 담당자에게 알림을 보내는 기능을 통해 애플리케이션의 장애를 빠르게 대응할 수 있게 된다. 일단, 어디서 어떤 문제가 생겼는지를 바로 체크할 수 있다는 것 자체가 대응의 시간을 전폭적으로 줄여주기 때문에 상당히 유용한 기능이라고 볼 수 있다.
info: 애플리케이션 정보
이번엔 info에 대해 알아보자. 이 info는 애플리케이션 정보를 알려준다. 예를 들면 OS 정보, JVM정보, 환경 변수 정보, Git 정보등을 말이다.
INFO레벨부터 로그가 찍혔다. 이 이유는 해당 패키지에 대한 로그 레벨이 INFO이기 때문이다. 실제로 그런지 액츄에이터로 확인해보자.
이는 ROOT의 기본 로그 레벨이 INFO라서 그 하위 패키지들은 따로 변경하지 않는 이상 전부 ROOT의 로그 레벨을 따라간다.
근데 이 액츄에이터는 이렇게 로그 레벨을 확인하는 기능도 있지만 실행중인 애플리케이션의 로그 레벨을 변경할 수도 있다.
예를 들어보자. 만약 운영중인 실제 서버가 어떤 장애가 났는데 해당 장애를 알기 위해 DEBUG로 찍은 로그를 확인하고 싶다. 보통은 로컬 또는 개발 서버에는 TRACE, DEBUG로 로그 레벨을 잡고 운영 중인 서버는 INFO부터 로그 레벨을 잡는게 일반적이다. 그럼 운영 중인 서버에서는 DEBUG 로그는 출력되지 않기 때문에 디버깅을 하기 어려운 환경이다. 이러한 상황일때 방법은 두가지가 있다.
이 파일에 logging.level.{원하는 패키지}: 로그레벨을 설정하면 된다. 그러나 이건 어떤 불편함이 있냐면, 이렇게 하면 로그 레벨을 바꾸고 다시 실행해야 하는 부분과 실행해서 원하는 작업을 다 끝내면 다시 로그 레벨을 원래대로 돌려놓고 또 다시 실행해야 하는 이런 단계를 거쳐야하고 그 단계를 거치면서 서버 다운 타임이 생기게 된다. 보통은 이런 경우를 원하지는 않을 것이다.
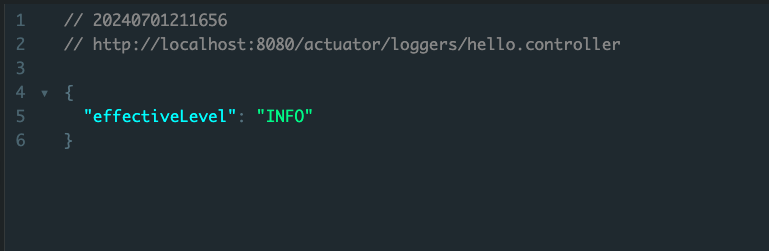
그럼 이럴땐 액츄에이터를 이용하면 된다. 액츄에이터로 로그 레벨을 확인하는 방법은 저렇게 전역으로 확인하는 방법도 있지만 딱 특정 패키지만을 확인하는 방법도 있다. 다음과 같이 path 마지막에 원하는 패키지명을 적어주면 된다.
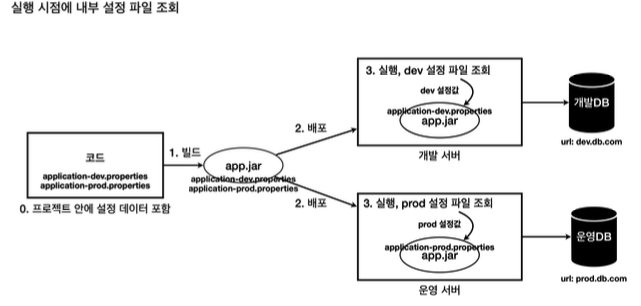
개발을 하다보면 로컬 환경에서 사용될 빈과 운영 환경에서 사용될 빈이 달라져야 하는 경우가 더러 있다.
예를 들면, 결제 관련 빈은 로컬 환경에서 테스트를 위해 가짜 결제 빈을 등록해서 테스트만을 위해 수행되어야 하고 운영 환경에서는 실제 결제 서비스를 통한 결제가 이루어져야 한다. 이런 경우에 구분된 빈이 스프링 컨테이너에 등록되어야 하는데 이걸 환경에 따라 편리하게 나눌수가 있다.
@Profile 애노테이션을 활용하면 된다.
다음 코드를 보자.
PayClient
package hello.pay;
public interface PayClient {
void pay(int money);
}
LocalPayClient
package hello.pay;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class LocalPayClient implements PayClient {
@Override
public void pay(int money) {
log.info("로컬 결제 money={}", money);
}
}
ProdPayClient
package hello.pay;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class ProdPayClient implements PayClient {
@Override
public void pay(int money) {
log.info("운영 결제 money={}", money);
}
}
PayClient라는 인터페이스를 하나 만들고 이를 구현하는 구현체(LocalPayClient, ProdPayClient)를 만들었다.
이 두 구현체를 빈으로 동시에 등록할 순 없다. 왜냐하면 둘 다 PayClient를 구현하는 구현체이므로. (물론 원한다면 할 수는 있다 근데 그게 지금 목적이 아니니)
그래서 Configuration 클래스를 하나 만들어보자.
PayConfig
package hello.pay;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Profile;
@Slf4j
@Configuration
public class PayConfig {
@Bean
@Profile("default")
public PayClient localPayClient() {
log.info("LocalPayClient 빈 등록");
return new LocalPayClient();
}
@Bean
@Profile("prod")
public PayClient prodPayClient() {
log.info("ProdPayClient 빈 등록");
return new ProdPayClient();
}
}
두 빈을 등록하는데 @Profile 애노테이션으로 LocalPayClient는 @Profile("default")일 때 등록되는 구현체다. ProdPayClient는 @Profile("prod")일 때 등록되는 구현체다. 이렇게 현재 프로필에 따라 빈으로 등록되는 구현체를 지정할 수 있다. 스프링 부트에서 해주는 아주 편리하고 좋은 기능이다.
그럼 이제 사용하는 서비스 코드를 보자.
OrderService
package hello.pay;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
@Service
@RequiredArgsConstructor
public class OrderService {
private final PayClient payClient;
public void order(int money) {
payClient.pay(money);
}
}
이 OrderService는 PayClient를 주입받는다. 어떤걸 주입받을지 이 OrderService는 알지 못한다. 이것 또한 유지보수에 좋은 코드이다. OCP원칙. 주입 시점을 이후로 미루는 것.
그리고 이 코드를 실제로 호출해서 사용해봐야 하는데 지금은 컨트롤러나 뭐 웹 서버를 띄우는게 아니니까 ApplicationRunner를 구현해서 스프링이 띄워질때 호출되는 코드가 생기도록 해보자.
OrderRunner
package hello.pay;
import lombok.RequiredArgsConstructor;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.stereotype.Component;
/**
* ApplicationRunner는 이 구현체를 스프링이 뜨는 시점에 자동으로 실행해준다.
* */
@Component
@RequiredArgsConstructor
public class OrderRunner implements ApplicationRunner {
private final OrderService orderService;
@Override
public void run(ApplicationArguments args) throws Exception {
orderService.order(10000);
}
}
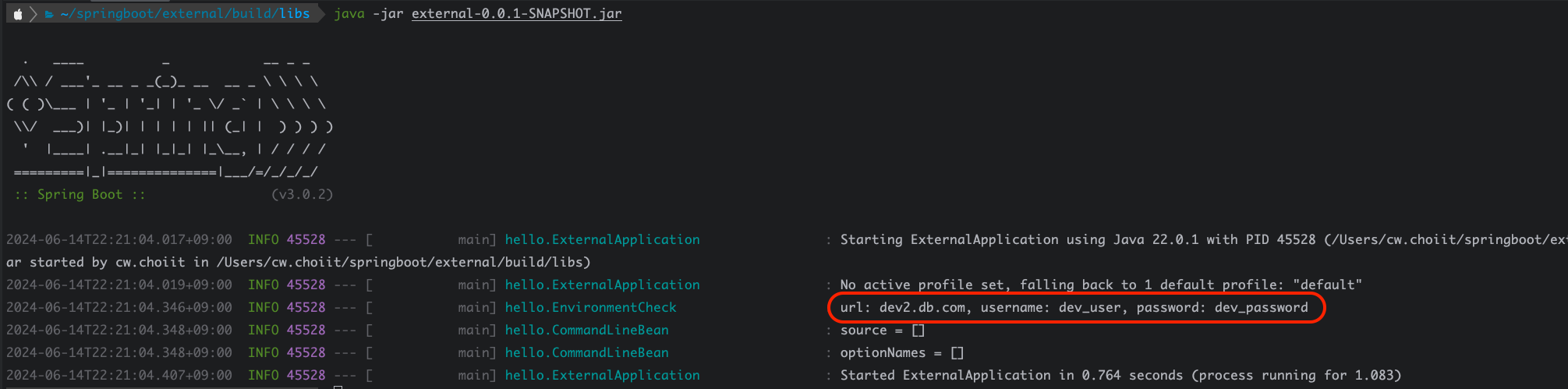
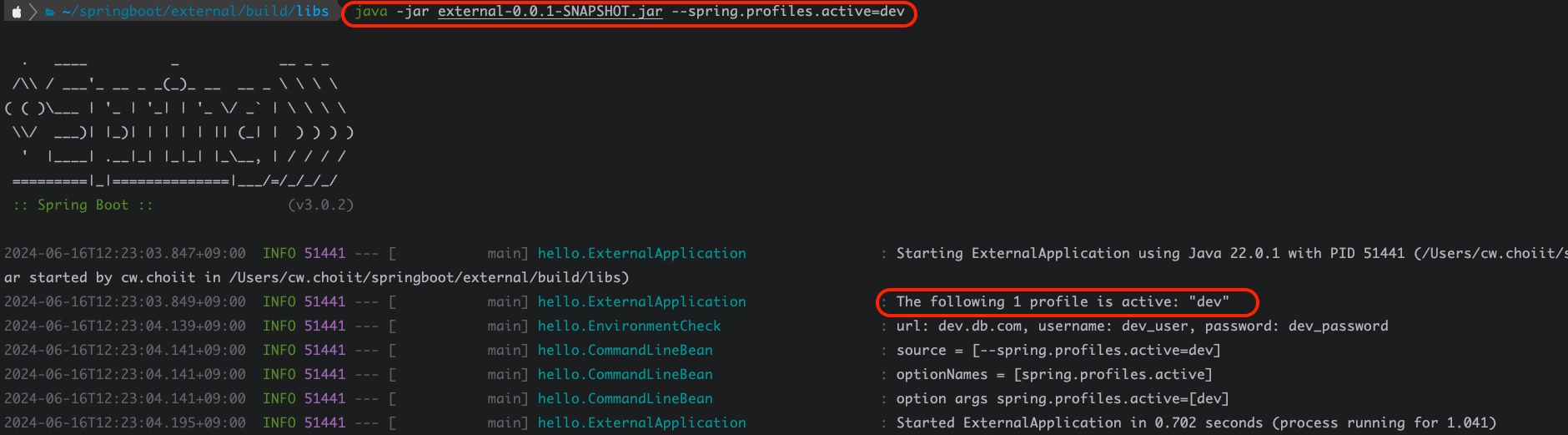
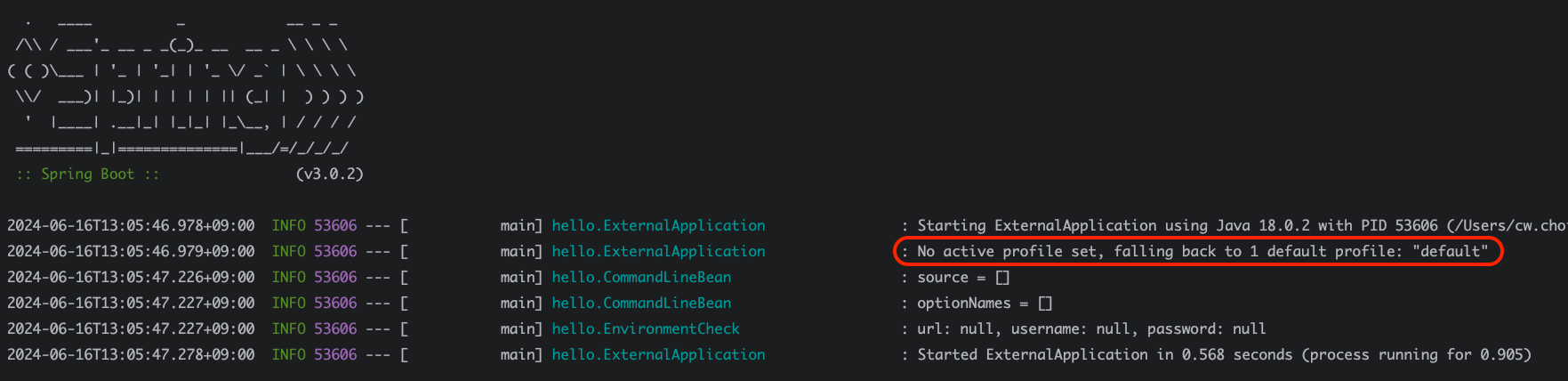
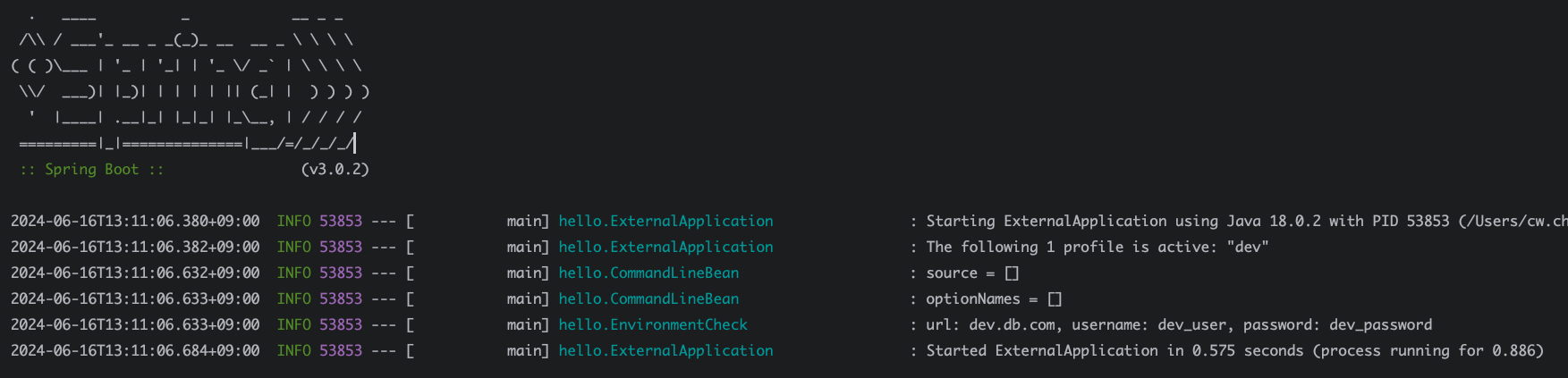
이렇게 코드를 작성하면 스프링이 띄워질때 이 OrderRunner라는 ApplicationRunner를 구현한 구현체의 구현 메서드인 run()이 호출된다. 프로필을 아무것도 주지않고 (즉, default 프로필) 실행해보자. 실행결과는 다음과 같다.
2024-06-30T20:33:35.161+09:00 INFO 21109 --- [ main] hello.ExternalReadApplication : No active profile set, falling back to 1 default profile: "default"
2024-06-30T20:33:35.477+09:00 INFO 21109 --- [ main] hello.pay.PayConfig : LocalPayClient 빈 등록
2024-06-30T20:33:35.583+09:00 INFO 21109 --- [ main] hello.datasource.MyDataSource : url: local.db.com
2024-06-30T20:33:35.584+09:00 INFO 21109 --- [ main] hello.datasource.MyDataSource : username: username
2024-06-30T20:33:35.584+09:00 INFO 21109 --- [ main] hello.datasource.MyDataSource : password: password
2024-06-30T20:33:35.584+09:00 INFO 21109 --- [ main] hello.datasource.MyDataSource : maxConnection: 1
2024-06-30T20:33:35.584+09:00 INFO 21109 --- [ main] hello.datasource.MyDataSource : timeout: PT3.5S
2024-06-30T20:33:35.584+09:00 INFO 21109 --- [ main] hello.datasource.MyDataSource : options: [CACHE, ADMIN]
2024-06-30T20:33:35.638+09:00 INFO 21109 --- [ main] hello.ExternalReadApplication : Started ExternalReadApplication in 0.767 seconds (process running for 1.109)
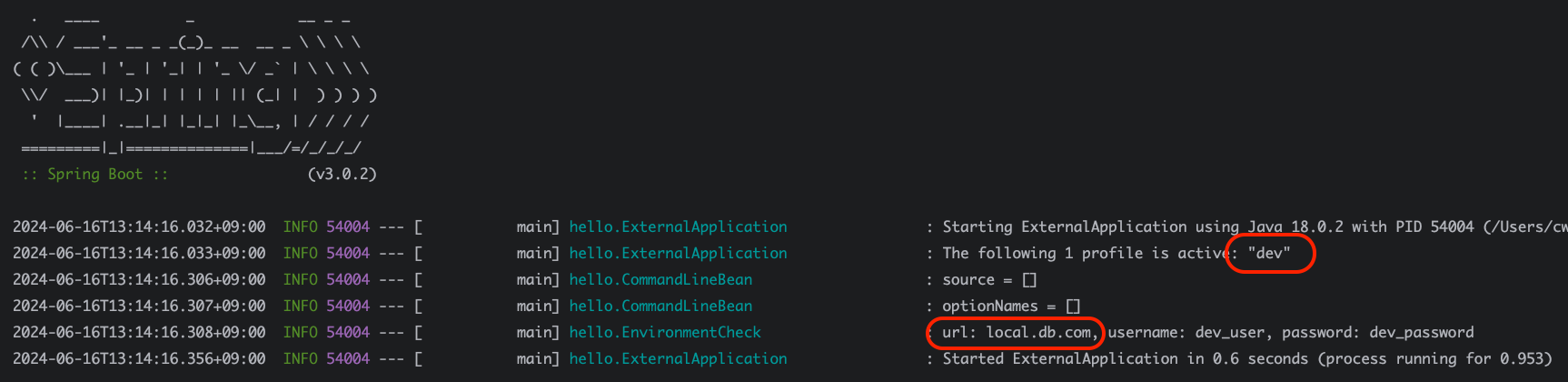
2024-06-30T20:33:35.640+09:00 INFO 21109 --- [ main] hello.pay.LocalPayClient : 로컬 결제 money=10000
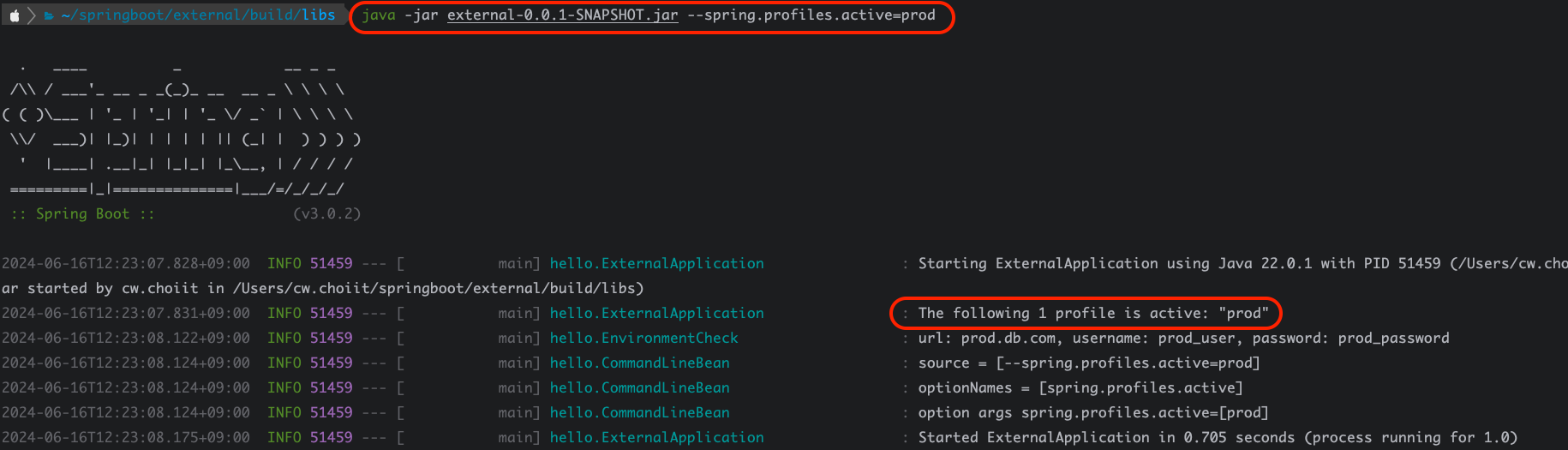
결과를 보면 알 수 있듯, 로컬 결제 빈이 등록되어 실행됐다. 만약 프로필을 `prod`로 주고 실행하면 다음과 같은 실행결과가 도출된다.
2024-06-30T20:38:38.289+09:00 INFO 21334 --- [ main] hello.ExternalReadApplication : The following 1 profile is active: "prod"
2024-06-30T20:38:38.649+09:00 INFO 21334 --- [ main] hello.pay.PayConfig : ProdPayClient 빈 등록
2024-06-30T20:38:38.743+09:00 INFO 21334 --- [ main] hello.datasource.MyDataSource : url: local.db.com
2024-06-30T20:38:38.743+09:00 INFO 21334 --- [ main] hello.datasource.MyDataSource : username: username
2024-06-30T20:38:38.743+09:00 INFO 21334 --- [ main] hello.datasource.MyDataSource : password: password
2024-06-30T20:38:38.743+09:00 INFO 21334 --- [ main] hello.datasource.MyDataSource : maxConnection: 1
2024-06-30T20:38:38.743+09:00 INFO 21334 --- [ main] hello.datasource.MyDataSource : timeout: PT3.5S
2024-06-30T20:38:38.743+09:00 INFO 21334 --- [ main] hello.datasource.MyDataSource : options: [CACHE, ADMIN]
2024-06-30T20:38:38.791+09:00 INFO 21334 --- [ main] hello.ExternalReadApplication : Started ExternalReadApplication in 0.83 seconds (process running for 1.191)
2024-06-30T20:38:38.792+09:00 INFO 21334 --- [ main] hello.pay.ProdPayClient : 운영 결제 money=10000
MyDataSourceEnvConfig 여기에서 MyDataSource를 빈으로 등록한 다음 필요한 값들을 Environment를 통해 외부 설정으로부터 가져온다. 이 Environment는 어떤 외부 설정이던 상관없이 가져올 수 있게 스프링이 제공해주는 아주 좋은 추상화된 객체이므로 위 코드처럼 값들을 가져올 수 있다.
한번 서버를 실행해보면 결과는 다음과 같다.
보이는 것처럼 @PostConstruct에 의해 호출된 데이터값들이 잘 보여진다.
근데, 이 방식은 어떤 단점이 있는가하면, 이 Environment를 직접 주입받는 것 자체에 있다. 주입을 직접 받는것도 불편하지만 받은 객체를 통해 계속해서 .getProperty()를 호출해서 꺼내와야만 한다. 이것을 반복하는 게 단점이다. 스프링은 @Value를 통해서 외부 설정값을 주입 받는 더욱 편리한 기능을 제공한다.
@Value
이 방법은 스프링이 외부 설정값을 편리하게 주입받게 해주는 방법이다. (사실 이 방법도 내부적으로는 Environment를 사용한다)
이렇게해도 가져올 수 있다. 그리고 이 방법은 외부 설정에서 값을 찾지 못하면 기본값으로 대체할 수 있는 기능도 제공하는데 이는 ":"로 기본값을 추가적으로 작성하면 된다.
@Value("${my.datasource.etc.max-connection:2}")
private int maxConnection;
이렇게 :2 라고 해두면 없는 경우 기본값을 2로 받아오겠다는 의미가 된다.
그래서 이렇게 간단하게 가져올 수는 있다만 이 방법 역시 하나하나 외부 설정 정보의 키 값을 입력받고 주입 받아와야 하는 부분이 번거롭다. 그리고 설정 데이터를 보면 하나하나 분리되어 있는 게 아니라 정보의 묶음으로 되어 있다. my.datasource.xxx 이렇게 말이다.
그 말은 이 부분을 객체로 변환해서 사용할 수 있다면 더 편리하고 더 좋을 것이다. 그 방법을 알아보자.
외부 설정 사용 - @ConfigurationProperties
이번에는 외부 설정 값을 객체로 가져올 수 있는 방법에 대해 알아보자.
우선, 객체로 가져오려면 객체가 필요하다.
MyDataSourcePropertiesV1
package hello.datasource;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
@Data
@ConfigurationProperties("my.datasource")
public class MyDataSourcePropertiesV1 {
private String url;
private String username;
private String password;
private Etc etc;
@Data
public static class Etc {
private int maxConnection;
private Duration timeout;
private List<String> options = new ArrayList<>();
}
}
이 객체를 보면, @ConfigurationProperties("my.datasource") 애노테이션이 있다. 이 애노테이션을 사용하면, .yml 파일이나 .properties 파일에 값을 등록한 `my.datasource`키에 대한 값을 객체로 변환해서 읽어오게된다.
그리고 그 중에 url, username, password는 바로 접근할 수 있지만, max-connection, timeout, options는 etc라는 키 하위에 존재한다. 다음 application.yml 파일을 비교해서 봐보자.
이 타입이 아닌 값이 외부 설정으로 부터 들어오면 에러를 뱉어낸다. 또한 계층 구조도 일치하는지 확인해주기 때문에 안전하고 재사용 가능한 객체 형태의 외부 설정값을 가져올 수 있다.
자, 객체 형태로 외부 설정을 가져와 빈으로 등록해서 여기저기 주입을 통해 사용할 수 있다는 것도 알게됐다. 근데 한가지 불편한 점이 있는데 아래 @ConfigurationProperties("my.datasource") 애노테이션을 붙였는데,
@Data
@ConfigurationProperties("my.datasource")
public class MyDataSourcePropertiesV1 {...}
여기서 또 @EnableConfigurationProperties(MyDataSourcePropertiesV1.class) 애노테이션을 붙여야 한다는 점이다.
@Slf4j
@EnableConfigurationProperties(MyDataSourcePropertiesV1.class)
public class MyDataSourcePropertiesConfigV1 {...}
그냥 한번만 애노테이션을 달면 좋겠는데, 귀찮게 두번 다 해줘야한다. 이 또한 해결 방법이 있다. 아래 애노테이션을 스프링 부트의 메인 클래스에 붙여주면 메인 클래스부터 하위 모든 패키지를 찾아서 @ConfigurationProperties 애노테이션을 등록한 클래스를 빈으로 알아서 등록해준다.
package hello.config;
import hello.datasource.MyDataSource;
import hello.datasource.MyDataSourcePropertiesV1;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
@Slf4j
// @EnableConfigurationProperties(MyDataSourcePropertiesV1.class)
public class MyDataSourcePropertiesConfigV1 {
private final MyDataSourcePropertiesV1 properties;
public MyDataSourcePropertiesConfigV1(MyDataSourcePropertiesV1 properties) {
this.properties = properties;
}
@Bean
public MyDataSource dataSource() {
return new MyDataSource(
properties.getUrl(),
properties.getUsername(),
properties.getPassword(),
properties.getEtc().getMaxConnection(),
properties.getEtc().getTimeout(),
properties.getEtc().getOptions());
}
}
그리고 이제 @EnableConfigurationProperties(MyDataSourcePropertiesV1.class) 이 애노테이션을 주석처리했다.
실행해보면 결과는 동일하게 잘 동작한다.
실행결과
2024-06-22T15:11:34.007+09:00 INFO 1827 --- [ main] hello.ExternalReadApplication : Starting ExternalReadApplication using Java 17.0.9 with PID 1827 (/Users/choichiwon/Spring/external-read/out/production/classes started by choichiwon in /Users/choichiwon/Spring/external-read)
2024-06-22T15:11:34.008+09:00 INFO 1827 --- [ main] hello.ExternalReadApplication : No active profile set, falling back to 1 default profile: "default"
2024-06-22T15:11:34.179+09:00 INFO 1827 --- [ main] hello.datasource.MyDataSource : url=local.db.com
2024-06-22T15:11:34.179+09:00 INFO 1827 --- [ main] hello.datasource.MyDataSource : username=local_user
2024-06-22T15:11:34.179+09:00 INFO 1827 --- [ main] hello.datasource.MyDataSource : password=local_pw
2024-06-22T15:11:34.179+09:00 INFO 1827 --- [ main] hello.datasource.MyDataSource : maxConnection=1
2024-06-22T15:11:34.179+09:00 INFO 1827 --- [ main] hello.datasource.MyDataSource : timeout=PT1M
2024-06-22T15:11:34.179+09:00 INFO 1827 --- [ main] hello.datasource.MyDataSource : options=[LOCAL, CACHE]
2024-06-22T15:11:34.217+09:00 INFO 1827 --- [ main] hello.ExternalReadApplication : Started ExternalReadApplication in 0.387 seconds (process running for 0.578)
남은 문제
어느 정도 해결된 것 같지만, 한가지 정말 불편한 점이 있다. Lombok의 @Data 애노테이션을 사용했는데 이 애노테이션은 Setter를 자동으로 만들어주는 것이다. Setter는 되도록이면 없어야 한다. 적어도 난 그렇게한다. 세터로부터 파생되는 찾기 힘든 문제들이 너무 많기 때문에. 그래서 이 Setter 대신 생성자를 통해서 외부 설정 값을 넣는 방법을 알아보자.
외부 설정 사용 - @ConfigurationProperties (생성자를 통해서)
위에 말한것처럼, 남은 문제가 있다. Setter를 남겨두고 싶지 않다. 그래서 생성자를 통해 외부 설정 값을 주입하는 방법이 있다.
우선 V2를 만든다. 여기서는 @Data를 지우고, @Getter만 남겨두자. 그리고 이 클래스의 생성자를 만들면 된다. 위 코드처럼. 그럼 끝이다.
실행결과
2024-06-29T15:22:08.257+09:00 INFO 71180 --- [ main] hello.datasource.MyDataSource : url=local.db.com
2024-06-29T15:22:08.257+09:00 INFO 71180 --- [ main] hello.datasource.MyDataSource : username=local_user
2024-06-29T15:22:08.257+09:00 INFO 71180 --- [ main] hello.datasource.MyDataSource : password=local_pw
2024-06-29T15:22:08.257+09:00 INFO 71180 --- [ main] hello.datasource.MyDataSource : maxConnection=1
2024-06-29T15:22:08.257+09:00 INFO 71180 --- [ main] hello.datasource.MyDataSource : timeout=PT1M
2024-06-29T15:22:08.257+09:00 INFO 71180 --- [ main] hello.datasource.MyDataSource : options=[DEFAULT]
2024-06-29T15:22:08.297+09:00 INFO 71180 --- [ main] hello.ExternalReadApplication : Started ExternalReadApplication in 0.397 seconds (process running for 0.589)
Process finished with exit code 0
@PostConstruct 애노테이션으로부터 실행되는 메서드의 로그가 잘 출력됐고, 값도 잘 들어갔다. 그리고 V2에 보면 내부 클래스(Etc)의 생성자에 보면 @DefaultValue라는 애노테이션이 있다. 이건 외부 설정으로부터 해당 키가 없으면 그 값에 기본값을 넣어주는 방법이다. 그래서 해당 키가 있으면 그 값을 그대로 가져오고 없으면 저기에 선언한 기본값을 넣어준다.
스프링 3.0 이전에는 생성자에 @ConstructorBinding 애노테이션이 없으면 안됐다. 필수적으로 달아줘야 했던 애노테이션인데, 3.0 이후에는 생성자가 하나뿐이라면 생략 가능하다. 그래서 위 코드에서도 해당 애노테이션은 없다.
남은 문제
남은 문제가 또 있다고?! 라고 생각하겠지만, 문제라기보단 더 많은 기능을 원한다. 이제는 생성자를 통해서 외부 설정값을 받아오고, 타입 안정성도 체크가 된다. 근데 검증을 하고 싶다. 예를 들면, max-connection이 최소 1보단 커야 이 값의 의미가 있다고 가정할때 0이 들어오면 아무런 의미없게 애플리케이션은 정상 동작을 하지 않을것이다. 그러나 타입 안정성에는 아무런 문제가 없기 때문에 어떤 에러로 인식시켜 주지 않는다. 내가 원하는건 만약 내가 실수로 0 또는 그보다 작은 수를 적었으면 바로 에러를 띄워 알려주길 원한다. 이게 가능할까?
외부 설정 사용 - @ConfigurationProperties (검증기 도입)
이제는 한 단계 더 나아가서 검증 기능까지 추가해서 더 안전한 외부 설정 주입을 사용해보자.
참고로, 위 두개 중 패키지 이름에 jakarta.validation으로 시작하는 것은 자바 표준 검증기에서 지원하는 기능이다. org.hibernate.validator로 시작하는 것은 자바 표준 검증기에서 아직 표준화 된 기능은 아니고 하이버네이트 검증기라는 표준 검증기의 구현체에서 직접 제공하는 기능이다. 대부분 하이버네이트 검증기를 사용하므로 크게 문제될 건 없다.
Part.1에서는 세가지를 배웠다. OS 환경 변수, 자바 시스템 속성, 커맨드 라인 인수.
근데 배우고 보니 저 세가지 방법 모두가 코드에서 가져오는 방식이 다 다르다는 것을 깨달았다. 그럼 여기서 스프링은 이를 두고보지 않는다. 우리에게 추상화 기능을 제공해서 아주 편리하게 어떻게 설정값을 지정했던 상관없이 한 가지 방법으로 모든 방법을 사용할 수 있도록 한다. 다음 그림을 보자.
스프링에서는 커맨드 라인 옵션 인수이던, 자바 시스템 속성이던, OS 환경변수이던, 설정 데이터(파일)이던 상관없이 딱 하나 `Environment` 객체를 통해서 원하는 값을 가져올 수 있다.
이 Environment는 역할(인터페이스)이고 이를 구현한 여러 구현체가 있다. 우리는 그 각각의 세부적인 구현체에 대해 자세히 알 필요없이 그저 Environment만 가져다가 사용하면 된다. 이것이 바로 변경가능한 부분과 변경하지 않아도 되는 부분을 잘 분리했다라고 말 할 수 있는 상황이다.
근데, 한가지 궁금한 부분이 생긴다. 그럼 만약 OS 환경 변수와 자바 시스템 속성 둘 다 또는 그 이상이 모두 같은 key를 가지는 값이 있을땐 무엇을 가져올까? 스프링이 자체적으로 우선순위를 만들어 두었다. 그 우선순위에 대해 알아보자.
예를 들어, 다음과 같이 커맨드 라인 옵션 인수와 자바 시스템 속성으로 같은 키를 지정했다면 어떤 값을 가져올까?
실행결과
url: devurl, username: dev_user, password: dev_pw
결과는 커맨드 라인 옵션 인수값을 가져온다. 즉, 자체적으로 우선순위가 커맨드 라인 옵션 인수가 더 높다는 뜻이다. 그럼 이걸 외워야하나?
우선순위는 상식 선에서 딱 2가지만 기억하면 된다.
더 유연한 것이 우선권을 가진다 (변경하기 어려운 파일 보다 실행 시 원하는 값을 줄 수 있는 자바 시스템 속성이 더 우선권을 가진다)
범위가 넓은 것보다 좁은 것이 우선권을 가진다(OS 환경 변수처럼 전역으로 여기저기 프로그램에서 가져올 수 있는 값보다 JVM 안에서만 접근 가능한 자바 시스템 속성이 더 우선순위가 높고, JVM 안에서 모두 접근 가능한 경우보다 커맨드 라인 옵션 인수는 main의 args를 통해서 들어오기 때문에 이 커맨드 라인 옵션 인수가 더 우선순위가 높다)
이제 스프링이 제공해주는 추상화 `Environment`를 통해 어떻게 외부에 데이터(설정값)를 저장했다고 해도 편리하게 가져다가 사용할 수 있게 됐다. 그럼 남은 한 가지, 외부 파일을 통해 가져오는 것도 알아보자.
설정 데이터1 - 외부 파일
지금까지 배운 내용으로 외부로부터 설정 데이터를 가져올 수 있게 됐다. 근데 사실 설정값이 지금이야 3개뿐이니 굉장히 간단하고 편해보이지만 실제 운영서버에서 사용되는 설정 데이터는 몇십개 몇백개도 존재할 수 있다. 그럼 벌써 머리 아프다. 관리하기가 굉장히 난처해진다.
그래서 그렇게 많은 데이터를 관리하기엔 파일로 관리하는게 최고다.
그래서 파일로 관리를 하고 애플리케이션 로딩 시점에 해당 파일을 읽어들이면 된다. 그 중에서도 .properties 파일이나 .yml 파일이 key=value 형식으로 설정값을 관리하기에 아주 적합하다.
그래서 .jar 파일을 빌드를 통해 만들고 그 .jar 파일이 있는 경로에 application.yml 파일을 만들어보자.
위 사진과 같이 .jar 파일이 존재하는 경로에 application.yml 파일을 만들어서 그 안에 key=value 값을 넣었다.
이 상태에서 애플리케이션을 실행해보자.
보이는 것과 같이 외부 파일을 읽어들여 값을 잘 찍는것을 볼 수 있다. 근데 이렇게 하는 것은 어떤 불편함이 있냐?
서버가 10대라면 10대 서버마다 이러한 파일을 다 만들어야 하는 불편함이 있다. 그리고 설정값이 변경되면 또 10대 모두 다 변경해줘야 한다.
그럼 어떻게 해결할까?
설정 데이터2 - 내부 파일 분리
이 외부 파일을 관리하는 것은 상당히 쉽지 않은 일이다. 설정을 변경할 때 마다 서버에 들어가서 각각의 변경 사항을 수정해두어야 한다. (물론 이것을 자동화 하기 위해 노력을 할 수는 있다)
이런 문제를 해결하는 간단한 방법은 설정 파일을 프로젝트 내부에 포함해서 관리하는 것이다. 그리고 빌드 시점에 함께 빌드되게 하는 것이다. 이렇게 하면 애플리케이션을 배포할 때 설정 파일의 변경 사항도 함께 배포할 수 있다. 쉽게 이야기해서 jar 하나로 설정 데이터까지 포함해서 관리하는 것이다.
위 그림을 보면 프로젝트 안에 설정 데이터를 포함하고 있다.
개발용 설정 파일: application-dev.properties
운영용 설정 파일: application-prod.properties
빌드 시점에 개발, 운영 설정 파일을 모두 포함해서 빌드한다.
app.jar는 개발, 운영 두 설정 파일을 모두 가지고 배포된다.
실행할 때 어떤 설정 데이터를 읽어야 할지 최소한의 구분은 필요하다.
실행할 때 외부 설정을 사용해서 개발 서버는 dev라는 값을 제공하고, 운영 서버는 prod라는 값을 제공하면 된다. 그리고 스프링에서 이것을 프로필이라고 미리 정의해두고 사용자들에게 제공하고 있다.
"그럼 이 프로필 정보는 어떻게 넘겨요?" 지금까지 했던 커맨드 라인 옵션 인수, VM 옵션 등으로 넘길 수 있다.
우선, 이 내부 설정 파일을 만들어보자. main/resources 경로에 다음 파일을 추가하자.
.properties 파일로 사용해도 되고 .yml 파일로 사용해도 된다. 이것도 취향 차이인데, 개인적으로 .yml 파일을 더 선호한다.
그 이유는 크게 2가지가 있다.
들여쓰기를 통한 가시화 증대 (본인 취향)
중복 키가 존재하면 .properties는 가장 마지막에 작성한 값이 적용되는 반면, .yml 파일은 에러를 발생시켜준다.
난 이 두번째 이유가 너무 좋다. 다음 예시를 보자.
application-dev.properties
이 파일에 `url` 이라는 키를 세 개나 중복해서 작성했다. 지금이야 한 눈에 보이지만 이 파일이 꽤나 커져서 위에서 작성했는지 까먹고 아래에서 또 작성할 여지가 분명히 존재한단 말이다. 아마 이 빨간줄은 인텔리제이 유료 버전이 똑똑하게 알려주는 것 같은데 다른 IDE나 기본 파일 에디터는 이런 것도 안 알려줄거다.
이 상태로 실행해보면 결과가 다음과 같다.
가장 마지막에 선언한 값이 적용된다. 뭐 어떻게 보면 유연하다고 볼 수도 있는데 난 이런 유연함은 싫다.
application-dev.yml
이 상태로 실행해보자. 다음과 같이 에러가 발생한다. 그리고 친절하게 DuplicateKeyException 이라고 알려준다. 얼마나 좋은가!
아무튼 이런 이유로 .yml 파일을 선호하고 .yml 파일로 작성했고 계속 진행해보자.
스프링은 이런 곳에서 사용하기 위해 프로필이라는 개념을 지원한다. `spring.profiles.active`외부 설정에 값을 넣으면 해당 프로필을 사용한다고 판단한다. 그리고 프로필에 따라 다음과 같은 규칙으로 해당 프로필에 맞는 내부 설정 파일을 조회한다.
java -jar Xxx.jar --spring.profiles.active=dev (커맨드 라인 옵션 인수)
한번 더 주의! VM 옵션은 -jar 앞에 작성해야 하고, 커맨드 라인 옵션 인수는 -jar 뒤에 작성해야 한다.
실행결과
이제 정말 간단하게 설정 데이터를 프로젝트 내에 위치시켜 외부로 빼서 서버마다 설정값이 변경되면 적용해줄 필요도 없고 빌드 파일 자체에 모든것이 담겨있게 됐다. 그러나 인간의 욕심은 끝이 없다. 이제 이 파일이 나뉘어져 있다 보니 각각의 설정값이 어떤 대조점이 있는지 한눈에 보기 어렵다는 점이 있다. 그럼 이건 또 어떻게 해결할까?
설정 데이터3 - 내부 파일 합체
스프링은 또 이 설정 파일을 각각 분리해서 관리하면 한눈에 전체가 들어오지 않는 단점이 있다는 것을 알고 물리적인 하나의 파일 안에서 논리적으로 영역을 구분하는 방법을 제공한다. 그리고 이 방법을 대부분 실무에서 많이 사용하고 있다.
대부분 실무에서 많이 사용하고 있다는 말은 통상적이지 절대적은 아니다. 파일을 application-prod.yml, application-dev.yml로 구분하는 방식도 많이 사용한다. 난 오히려 이게 더 편하기도 하다. 약간 취향의 차이로 생각하면 좋을 것 같다.
결과를 보면 알 수 있듯 두개의 프로필이 활성화됐다. 그럼 위에서 말한것처럼 위에서 아래로 읽어 들이는 설정 파일은 결국 'dev'도 읽고 'prod'도 읽으니까 최종적으로 url, username, password의 값은 'prod'값으로 적용이 될 수 밖에 없다는 것을 안다.
결론과 우선순위 - 전체
이제 전체적으로 외부 설정을 읽어 들일 때 우선순위가 어떻게 적용되는지 확인해보자.
아래로 내려갈수록 우선순위가 높은것이다.
설정 데이터(application.yml)
OS 환경 변수
자바 시스템 속성
커맨드 라인 옵션 인수
@TestPropertySource (테스트에서 사용)
이걸 외우는게 아니라, 그냥 두가지 큰 틀을 알고 있으면 된다.
더 유연한 것이 우선권을 가진다. (변경하기 어려운 파일보다 실행 시 원하는 값을 줄 수 있는 자바 시스템 속성이 더 우선권을 가진다)
범위가 넓은 것보다 좁은 것이 더 우선권을 가진다. (다른 말로, 더 디테일한게 우선권을 가진다)