참고 자료:
김영한의 실전 자바 - 중급 1편 | 김영한 - 인프런
김영한 | 실무에 필요한 자바의 다양한 중급 기능을 예제 코드로 깊이있게 학습합니다., [사진]국내 개발 분야 누적 수강생 1위, 제대로 만든 김영한의 실전 자바[사진][임베딩 영상]단순히 자바
www.inflearn.com
객체지향 프로그래밍의 대표적인 특징으로는 캡슐화, 상속, 다형성이 있다. 그 중 다형성은 객체지향 프로그래밍의 꽃이라 불린다.
캡슐화나 상속은 직관적으로 이해하기 쉽다. 그러나 다형성은 제대로 이해하기도 어렵고, 잘 활용하기는 더 어렵다. 하지만 좋은 개발자가 되기 위해선 다형성에 대한 이해가 필수다.
다형성(Polymorphism)
이름 그대로 "다양한 형태"를 뜻한다. 자바에서 다형성은 한 객체가 여러 타입의 객체로 취급될 수 있는 능력을 뜻한다. 보통은 하나의 객체는 하나의 타입으로 고정되어 있는데, 다형성을 이용하면 하나의 객체가 다른 타입으로 사용될 수 있다는 뜻이다.
다형성을 이해하기 위해서는 크게 2가지 핵심 이론을 알아야 한다.
- 다형적 참조
- 메서드 오버라이딩
다형적 참조
다음과 같은 관계를 가지는 두 클래스를 생각해보자.
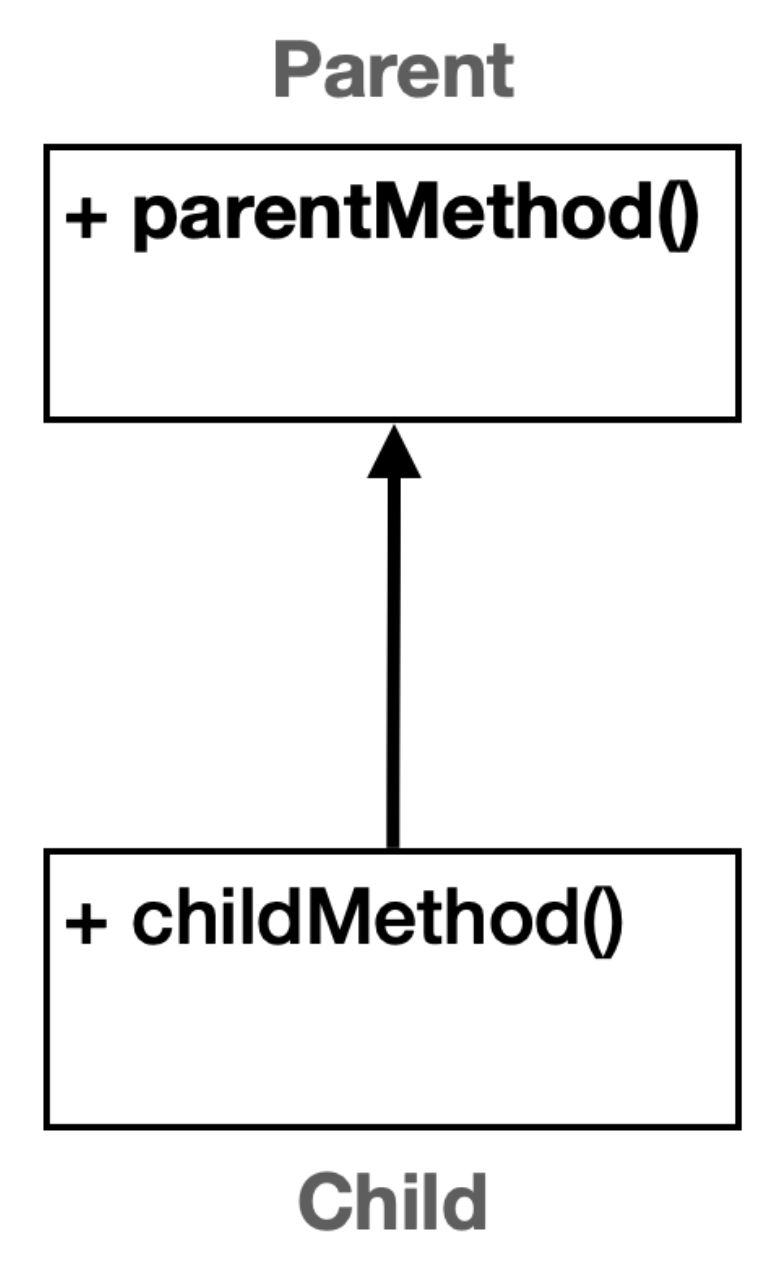
부모와 자식이 있고 각각 다른 메서드를 가진다.
Parent
public class Parent {
public void parentMethod() {
System.out.println("Parent.parentMethod");
}
}
Child
public class Child extends Parent {
public void childMethod() {
System.out.println("Child.childMethod");
}
}
Main
public class Main {
public static void main(String[] args) {
System.out.println("Parent -> Parent");
Parent parent = new Parent();
parent.parentMethod();
System.out.println("Child -> Child");
Child child = new Child();
child.parentMethod();
child.childMethod();
// 부모 변수가 자식 인스턴스를 참조 (다형적 참조)
System.out.println("Parent -> Child");
Parent poly = new Child();
poly.parentMethod();
// poly.childMethod(); 자식의 메서드는 호출할 수 없다.
// Child child1 = new Parent(); // 자식은 부모를 담을 수 없다.
}
}
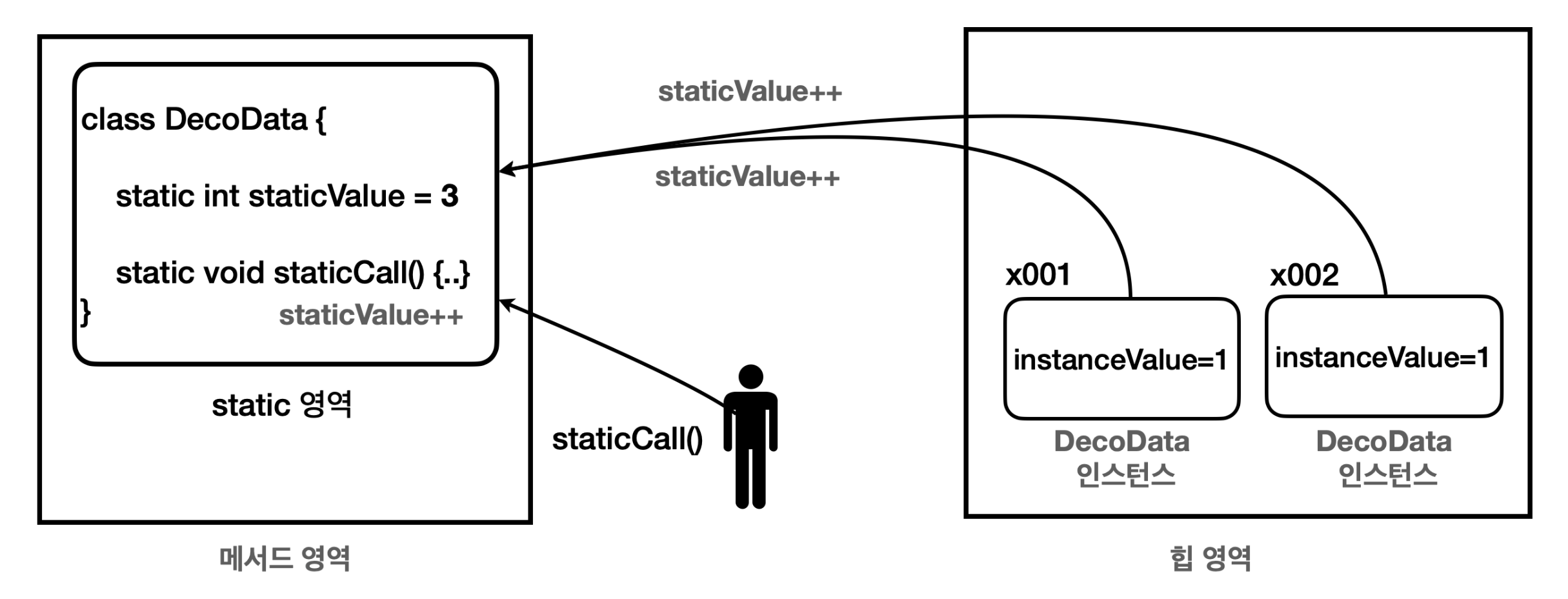
Main에서 보면 부모 타입 변수가 부모 인스턴스를 참조하거나, 자식 타입 변수가 자식 인스턴스를 참조하는건 참 많이 봐왔다. 그런데 그 아래 부모 타입 변수가 자식 인스턴스를 참조하고 있다. 이것을 다형적 참조라고 한다. 이게 어떻게 가능한지는 객체와 메모리 구조를 잘 떠올려보면 납득이 된다.
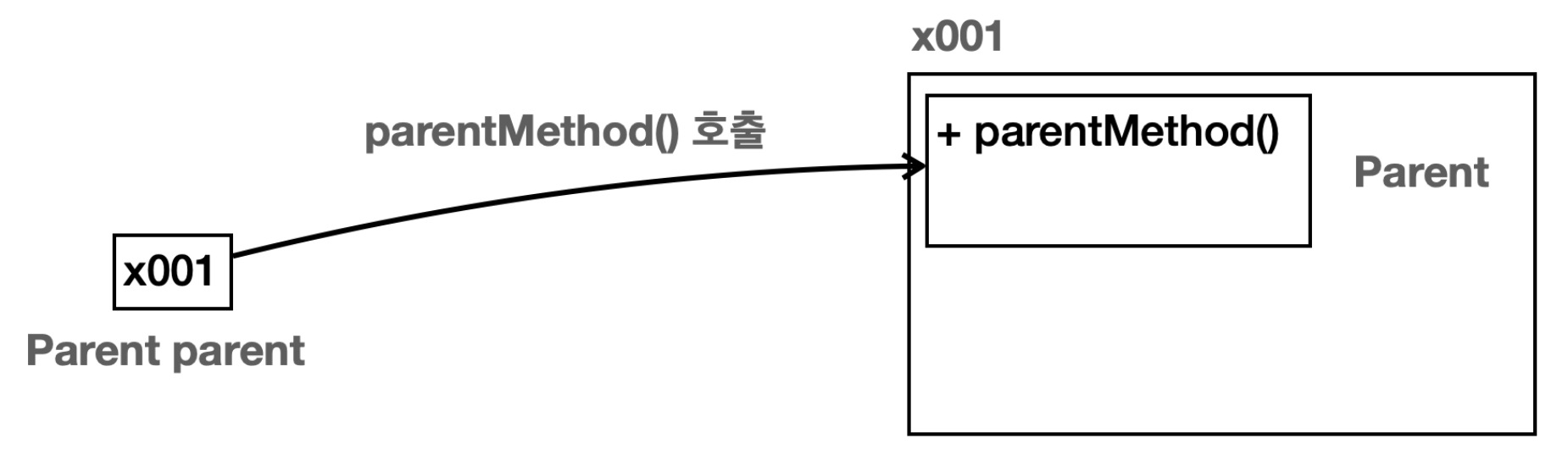
부모 타입의 변수가 부모 인스턴스 참조 Parent parent = new Parent();
1. 우선 부모 인스턴스를 새로 생성하고
2. 그 참조값(x001)을 부모 타입의 변수에 넣는다.
3. 부모 인스턴스를 생성하면 해당 인스턴스가 힙 영역에 다음과 같이 생긴다.
4. 더 이상 설명할 내용이 없을 정도로 간결하다. 당연히 자식 인스턴스는 같은 참조에 속하지 않는다. 부모 입장에서는 자식이 누군지도 모르기 때문이다.
그리고 이런 이유 때문에 Child child = new Parent(); 는 불가한 것이다. 왜냐? Parent 인스턴스를 생성하면 Child는 만들어지지 않는다. Parent는 어떤 클래스가 나를 상속받는지 정보가 아무것도 없기 때문에 이런 구조에서 Child 타입의 변수는 해당 참조값을 가지고 있을 수 없는것.
자식 타입의 변수가 자식 인스턴스 참조 Child child = new Child();
1. 자식 인스턴스를 생성한다.
2. 그 참조값(x001)을 자식 타입의 변수에 넣는다.
3. 자식 인스턴스를 생성하면 자식 인스턴스와 함께 상속관계에 있는 부모 인스턴스도 같은 참조(x001)에 만들어진다.

이 구조가 만들어지기 때문에 자식 타입의 변수에서 부모의 메서드를 호출하더라도 참조값(x001)이 가르키는 참조에 찾아가서 첫번째로 본인의 타입인 Child부터 확인해서 없으면 부모로 계속 거슬러 올라가서 확인할 수 있으니 부모의 메서드 호출이 가능해진다.
다형적 참조: 부모 타입의 변수가 자식 인스턴스를 참조: Parent poly = new Child();
여기가 중요하다. 우선 메모리에 어떻게 올라갈지 먼저 생각해보자. 자식 인스턴스를 생성했다. 그럼 자식 인스턴스가 메모리에 올라갈텐데 자식 인스턴스는 상속받는 부모도 가지고 있다. 그럼 자식 인스턴스의 참조값(x001)에 가보면 메모리에는 다음과 같이 부모와 자식 인스턴스 모두가 생성된 상태일것이다. 그래서 타입을 부모 타입으로 선언해도 문제가 없는것이다. 해당 참조값이 가르키는 메모리 상엔 부모 객체도 존재하니까.

1. 부모 타입의 변수가 자식 인스턴스를 참조한다. Parent poly = new Child();
2. Child 인스턴스를 만들었다. 이 경우 자식 타입인 Child를 생성했기 때문에 메모리 상에 Child와 Parent가 모두 생성된다.
3. 생성된 참조값을 Parent 타입의 변수인 poly에 담아둔다.
Parent 타입의 변수는 다음과 같이 자신인 Parent는 물론이고, 자식 타입까지 참조할 수 있다. 만약 그 하위에 또 다른 자식이 있다면 그것도 가능하다.
- Parent poly = new Parent()
- Parent poly = new Child()
- Parent poly = new Grandson()
Grandson -> Child -> Parent 이런 구조로 상속받는 형태라면 new Grandson()을 실행하면 메모리에는 총 3개의 객체가 한 참조를 만들것이다. 그렇기 때문에 이 경우 Child, Parent 타입 변수 new Grandson()을 받아들일 수 있다.
즉, 자신을 기준으로 모든 자식 타입을 참조할 수 있다. 이것이 바로 다양한 형태를 참조할 수 있다고 해서 다형적 참조라고 한다.
다형적 참조의 한계
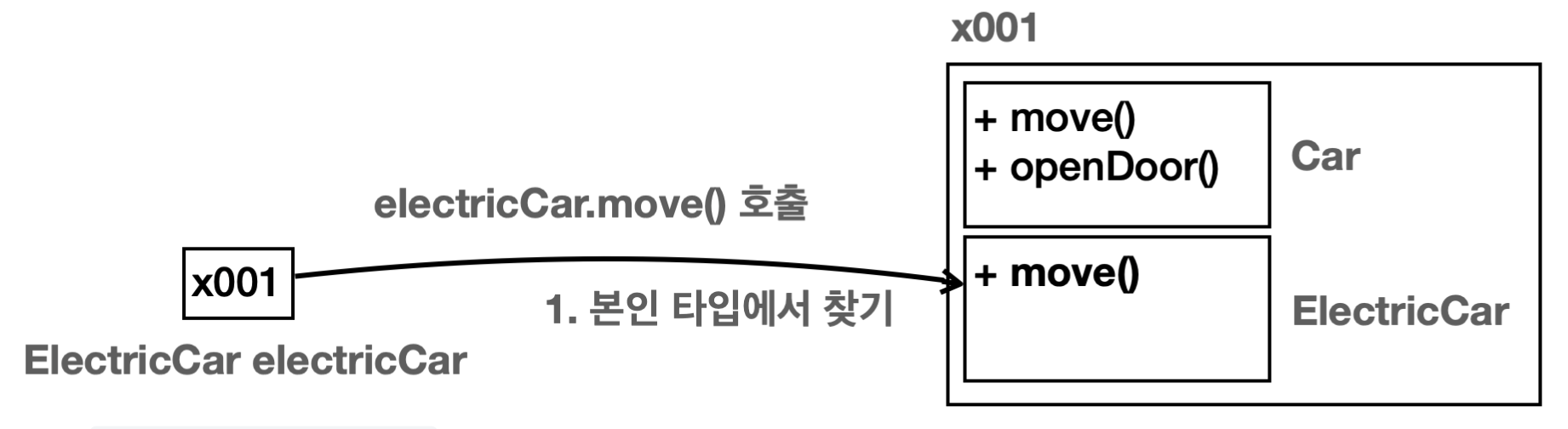
Parent poly = new Child() 이렇게 자식 인스턴스를 참조한 상황에서 poly가 자식 타입인 Child에 있는 childMethod()를 호출하면 어떻게 될까? 호출할 수 없다. 아래는 그 흐름인데 한번 보자.
1. poly.childMethod()를 실행하면 먼저 참조값을 통해 인스턴스를 찾는다.
2. 그리고 다음으로 인스턴스 안에서 실행할 타입을 찾아야 한다. 타입이 Parent이므로 Parent 클래스부터 시작해서 필요한 기능을 찾는다. 그런데 상속 관계는 부모 방향으로 찾아 올라갈 수는 있지만 자식 방향으로 찾아 내려갈 수 없다. Parent는 부모 타입이고 상위에 부모가 없다. 따라서 childMethod()를 찾을 수 없으므로 컴파일 오류가 발생한다.
아니 그럼, childMethod()를 못쓰는데 이거 어쩐담?
다형성과 캐스팅
Parent poly = new Child();이 코드 한 줄은 poly라는 Parent 타입의 변수에 Child 인스턴스를 참조하게 한다. Child 인스턴스를 만들 때 부모인 Parent 인스턴스 역시 하나의 참조값에 포함되어 만들어지는데 이때 poly라는 변수의 타입이 Parent이므로 Child가 가지는 메서드는 실행할 수 없다. 상속 관계는 부모로만 찾아서 올라갈 수 있다.
그러면 childMethod()를 정말 너무 쓰고 싶은데 어떻게 하면 좋을까? 다운캐스팅을 하면 된다. 다음 코드를 보자.
public class Main {
public static void main(String[] args) {
Parent parent = new Child();
// parent.childrenMethod(); 컴파일 에러
Child child = (Child) parent;
child.childMethod();
}
}Parent 타입의 변수 parent에 들어있는 참조값을 가지고 Child 타입의 변수 child에 대입을 한다. 근데 대입할 때 앞부분에 (Child)를 추가해주면 이게 바로 다운 캐스팅이다. 다운 캐스팅은 자식으로 형변환을 하는것이다. 이러면 childMethod()를 호출할 수 있다.
1. Child 인스턴스를 생성한다. 생성할 때 부모인 Parent도 같이 생성된 하나의 참조가 만들어진다.
2. 만들어진 참조의 참조값을 Parent 타입의 변수에 넣는다.
3. 해당 변수는 타입이 Parent이므로 자식의 메서드를 사용하지 못한다.
4. 자식의 메서드를 기어코 사용하기 위해 자식 타입으로 다운캐스팅을 한다.
5. 자식 메서드를 사용한다.
참고로 캐스팅을 한다고 해서 Parent poly의 타입이 변하는 것은 아니다. 해당 참조값을 꺼내고 꺼낸 참조값이 Child 타입이 되는것이다. 따라서 poly의 타입은 Parent로 기존과 같이 유지된다.
캐스팅시 주의
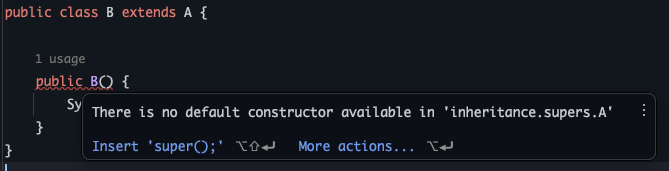
근데 위 코드를 파헤쳐보면 많은 것들이 나온다. 일단 첫번째, 다운캐스팅이란 단어가 있다는 것은 업캐스팅도 있다는 것을 내포한다. 맞다. 업캐스팅도 있고 업캐스팅은 부모로 캐스팅하는 것이다. 그리고 우리 이미 이건 해봤다.
Parent parent = new Child();이 코드가 바로 업캐스팅이다. 왜냐고? 자식 인스턴스를 부모 타입의 변수에 참조하니까. 저 코드는 사실 이런 모양이다.
Parent parent = (Parent) new Child();근데 자바에서 생략이 가능하게 해준다. 실제로 IDE에서 작성해보면 다음과 같이 회색 불빛으로 굳이 쓸 필요없다고 말해준다.

그럼 업캐스팅은 생략을 해주는데 왜 다운캐스팅은 생략을 안해줄까? 다운 캐스팅은 런타임 에러가 발생할 가능성이 있기 때문이다.
자 다음 코드를 보자. Parent 타입의 parent를 Child로 다운캐스팅한다. 그리고 다운캐스팅을 했으니 자식 타입의 메서드 cMethod()를 호출할 수 있다.
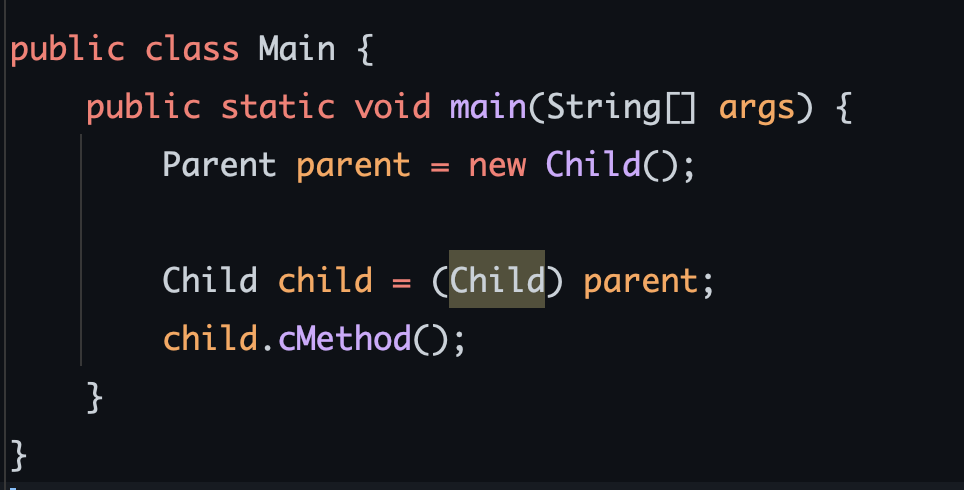
아, 그리고 이 과정이 귀찮다. 그래서 일시적 캐스팅이란게 있다. 다음 코드를 보자. 이렇게 하면 변수를 굳이 만들지 않아도 된다.

자 위 코드는 문제없이 잘 동작한다. 근데 다음 코드를 보자. 중요!

위 코드가 동작할까? 아니다. 런타임 에러가 발생한다.

에러 내용은 ClassCastException이다. 왜 이런 에러가 발생할까? 근데 우리는 알고 있다. 객체와 메모리 구조를 다시 한번 떠올려보자.
new Parent()는 Parent 인스턴스를 메모리 상에 만들어낸다. 그러나 본인을 상속하는 자식은 알 길이 없기 때문에 참조에 어떠한 자식도 같이 만들어지지 않는다. 그러니까 그 참조에서 Child는 없기 때문에 Child로 다운캐스팅은 할 수가 없는것이다. 다음이 그 그림이다.
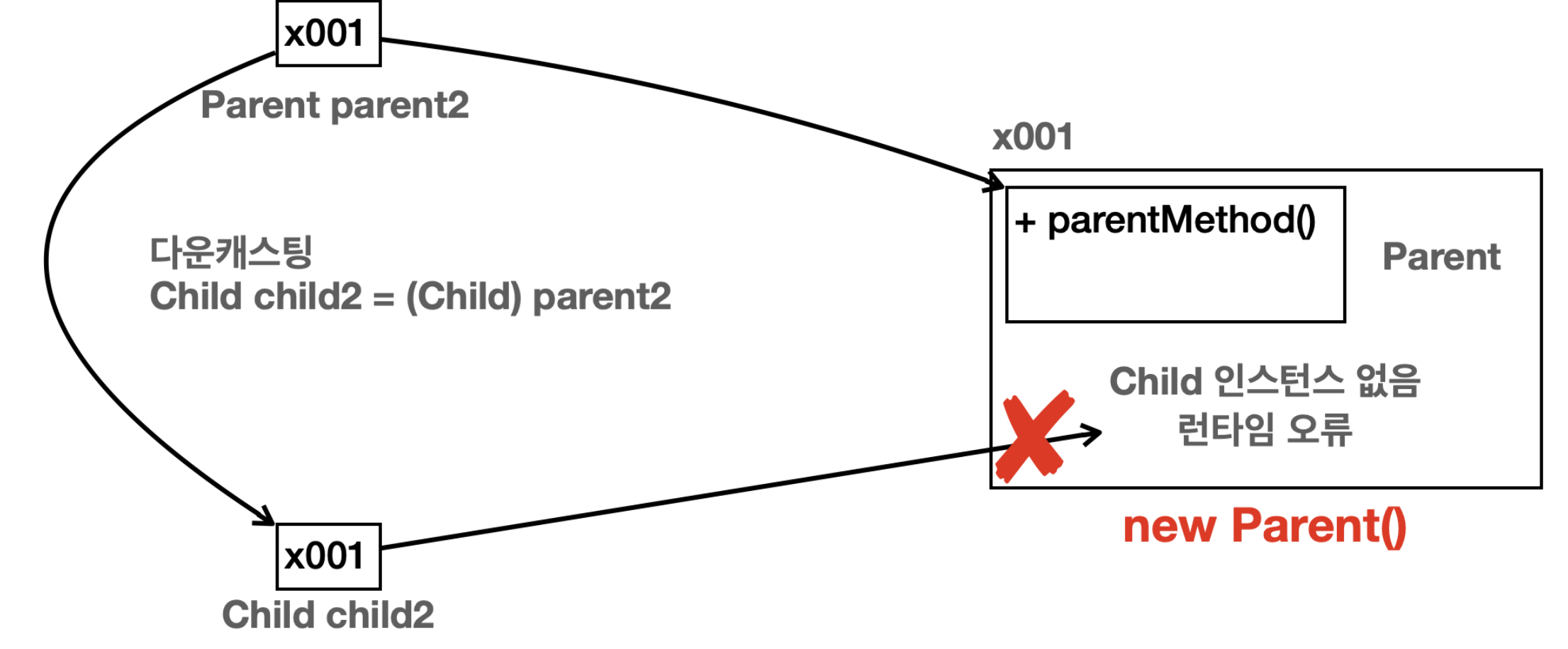
그러나 Parent parent = new Child();는 문제가 없다. 이것도 메모리 구조를 잘 떠올려보면 Child 인스턴스를 만들 때 부모 클래스에 대한 인스턴스 역시 같이 만들어진다. 그렇기 때문에 부모 타입의 parent라는 변수가 자식으로 다운캐스팅이 되어도 아무런 문제가 없이 잘 동작할 수 있게된다. 그 그림은 다음과 같다.

이러한 이유 때문에 다운 캐스팅은 위험하다고 하는 것이다. 그럼 왜 업캐스팅은 안전할까?
업캐스팅은 에러가 날 수가 없다. 왜냐면 더 상위 타입으로 형변환을 하는것인데 그 말은 자식 인스턴스를 만들어낸다는 것이고 자식 인스턴스를 만들 때 당연히 부모 인스턴스도 하나의 참조에 만들어지기 때문에 무조건 캐스팅이 잘된다.
다음 코드가 대표적인 업캐스팅 코드이다.
Parent parent = new Child();Child 인스턴스를 만들 때 메모리 상에 참조 내에는 Child, Parent 인스턴스 둘 다 만들어진다. 부모를 같이 만드니까.
그러니까 당연히 부모타입으로 업캐스팅이 가능한 것. 절대 문제가 발생할 수가 없는 것.
그러면, 다운 캐스팅을 하고 싶은데 너무 하고 싶은데 이게 문제를 발생시킬까? 아닐까?를 IDE에서 조차 알려주지 않기 때문에(런타임 에러) 아예 사용하지 말아야할까? 내가 다운캐스팅하려고 하는 이 녀석이 참조하는 참조 인스턴스가 다운 캐스팅할 녀석보다 상위 클래스인지 알 방법은 없을까? 그러니까 아래 코드처럼 parent를 Child로 다운캐스팅하고 싶을 때 이 parent가 참조하는 인스턴스가 Child보다 상위 클래스인지 아닌지 알 수 있는 방법 말이다.
Parent parent = new Child();
instanceof
어떤 인스턴스를 참조하고 있는지 알 수 있는 방법이다. 다음 코드를 보자.
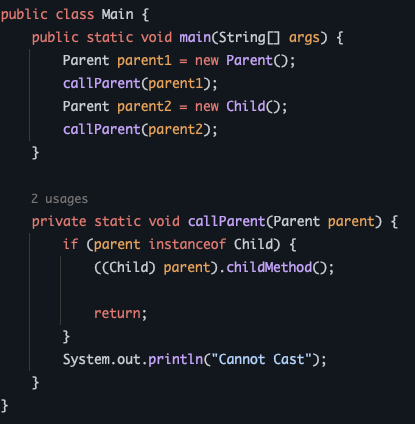
callParent() 메서드는 파라미터로 Parent parent를 받는다. 이 때 변수 parent는 Parent 인스턴스를 참조하고 있을수도 있고 Child 인스턴스를 참조할 수도 있다. Child는 Parent를 상속받기 때문에 가능한 일인데, 원하는 것은 Parent 타입의 변수가 자식 클래스의 메서드를 사용하고 싶은 것이다. 그러려면 다운캐스팅을 해줘야한다. 그러나 위에서 말했지만 다운캐스팅은 위험하다. 에러가 발생할 소지가 있기 때문인데 그래서 에러를 방지하기 위해 instanceof로 Child 인스턴스를 참조하는 변수인지 확인을 하는 코드다.
참고로, instanceof 키워드는 왼쪽에서 참조하는 인스턴스가 오른쪽 타입에 대입될 수 있는지를 확인해보면 된다.
new Parent() instanceof Parent // true
new Parent() instanceof Child // false
new Child() instanceof Parent // true
new Child() instanceof Child // true
그러니까 이것도 객체와 메모리 구조를 떠올려보자. 왼쪽에 인스턴스가 메모리 상에 어떻게 올라가는지 확인해보자.
new Parent()를 하면 메모리에는 Parent 인스턴스만 참조 공간에 만들어진다. 이 상태에서 Parent 타입에는 대입이 가능하고 Child 타입에는 당연히 불가능하다. new Child()를 하면 메모리에는 Parent, Child 두 개의 인스턴스 모두 참조 공간에 만들어진다. 그래서 Parent 타입으로 대입도 가능하고 Child 타입으로 대입도 가능하다.
그리고 자바 16부터 가능한 기능인데 뭐 그냥 알아두면 나쁠건 없는 기능이다. 다음 코드를 보자.

여기서 parent가 참조하는 참조값이 Child 인스턴스라면 다운 캐스팅을 하는데 이걸 이렇게 한번에 쓸 수 있다. 변수를 선언해버리는 것이다.

다형성의 메서드 오버라이딩
다형성은 하나의 변수 타입으로 여러 자식 인스턴스를 참조할 수 있는 것을 말한다. 이것을 다형적 참조라고 하는데 다형성의 또 다른 핵심 주제 하나는 메서드 오버라이딩이다. 다음 코드를 보자.
Parent
public class Parent {
public String value = "parent";
public void method() {
System.out.println("Parent method");
}
}
Child
public class Child extends Parent {
public String value = "child";
@Override
public void method() {
System.out.println("Child method");
}
}
Parent와 Child 클래스 모두 value라는 필드를 가진다. 필드는 오버라이딩의 개념이 없다. 둘 다 각자 가지고 있는 필드인거고 method()라는 메서드를 Child에서 오버라이딩했다. 코드 자체는 굉장히 간단하다.
Main
public class Main {
public static void main(String[] args) {
Parent parent = new Parent();
System.out.println(parent.value);
parent.method();
Child child = new Child();
System.out.println(child.value);
child.method();
Parent poly = new Child();
System.out.println(poly.value);
poly.method();
}
}
실행결과:
parent
Parent method
child
Child method
parent
Child method
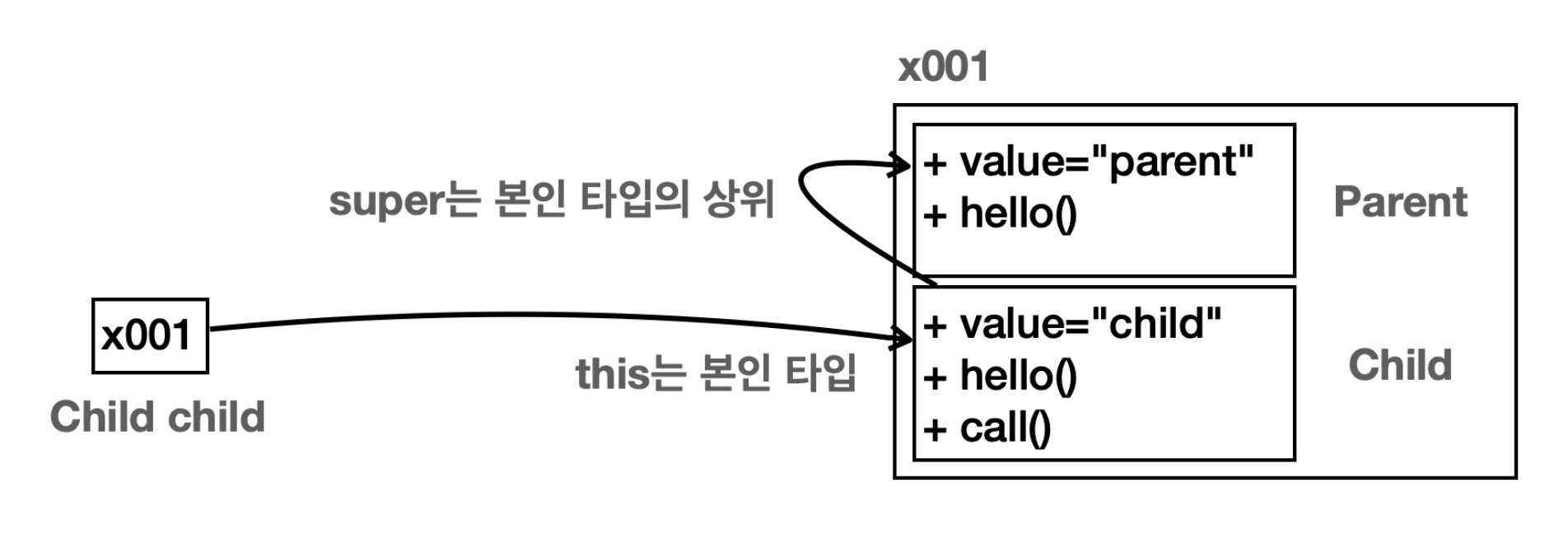
신기한 일이 벌어졌다. 당연히 위에 두 실행결과는 납득이 된다. Parent 타입 변수에 Parent 인스턴스를 참조했으니 Parent가 가지고 있는 value와 method()가 호출될테고 Child도 마찬가지다. 그림을 통해서 좀 더 명확히 확인해보자.
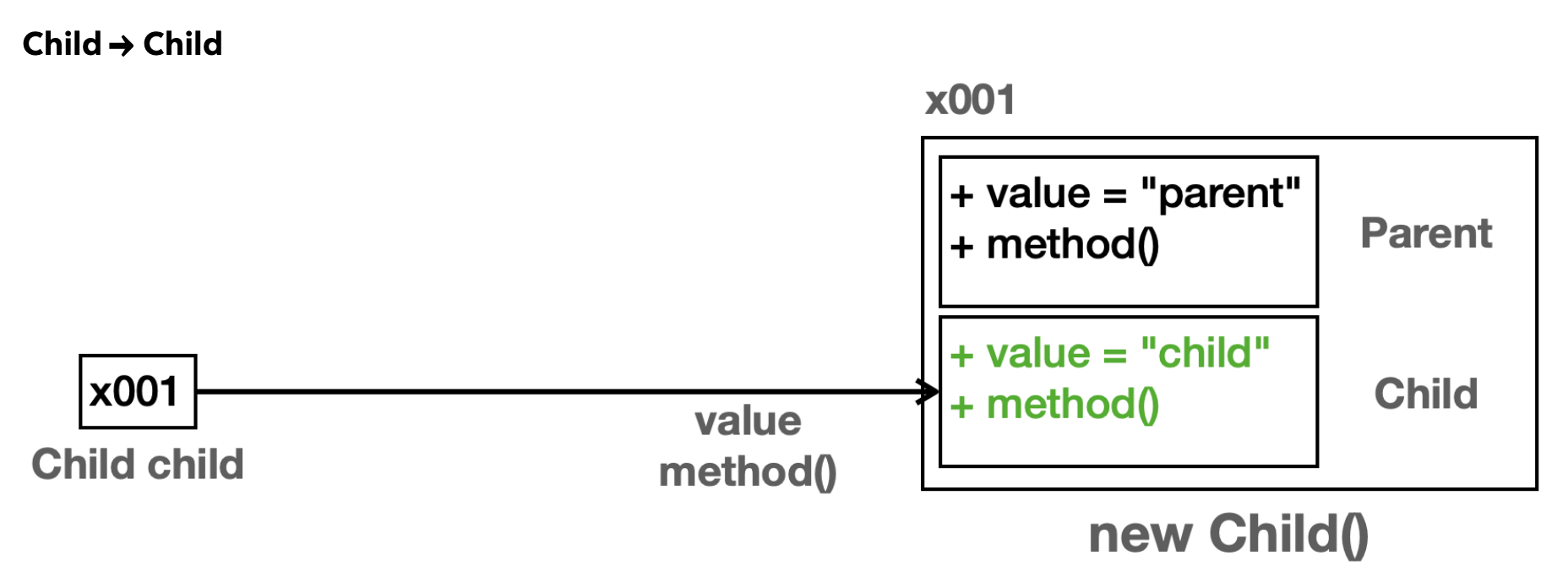
child 변수는 Child 타입이다. 따라서 child.value, child.method()를 실행하면 인스턴스의 Child 타입에서 기능을 찾아서 수행한다.


parent 변수는 Parent 타입이다. 따라서 parent.value, parent.method()를 호출하면 인스턴스의 Parent 타입에서 기능을 찾아 수행한다. 사실 new Parent()로 인스턴스를 만들면 인스턴스 공간에 Child 자체가 없기 때문에 Child의 뭐든 가져올수도 없다.
여기서가 중요하다. Parent 타입 변수에 Child 인스턴스를 참조했더니 필드는 그대로 Parent의 필드를 반환했지만 method()는 Child의 method()를 반환했다.
무슨 일일까? 객체와 메모리 구조를 상기해보면 Child라는 인스턴스를 생성할 때 부모인 Parent도 같은 참조 공간에 만들어지고 변수 타입이 Parent니까 분명 참조 공간에서 Parent를 바라보면 Parent의 method()가 실행됐어야 했는데 Child method()가 실행됐다.
메서드는 오버라이딩 한 메서드가 무조건 우선순위를 가진다.

이 다형성과 메서드 오버라이딩이 강력하고 어마어마한 코드 작성을 도와준다. 이제 이 개념을 사용해볼 차례다.
사실, 이 내용이 스프링의 핵심 패턴인 전략 패턴과 매우 밀접한 관계가 있다. 생각해보자. 인터페이스를 만들고 그 인터페이스에서 추상 메서드를 정의했다. 그리고 그 인터페이스를 구현한 구현클래스를 만들었다. 그 구현 클래스에 "@Service" 애노테이션을 붙이면 스프링이 자동으로 해당 클래스를 인터페이스 타입의 참조값으로 빈으로 등록하잖아? 그리고 우리가 특정 서비스나 컨트롤러에서 DI를 하면 그 DI되는 인스턴스는 빈으로 등록한 그 녀석이 된다. 그래서 인터페이스의 메서드를 호출하면 빈으로 등록한 클래스의 메서드가 실행되는게 이 원리이다. 인터페이스는 하나, 그것을 구현한 구현클래스는 여러개일지언정 이 코드를 사용하는 클라이언트 소스에서는 전혀 변경할 필요없이 빈 등록만 다른걸로 바꿔주면 되는것 이게 바로 OCP이고.
'JAVA의 가장 기본이 되는 내용' 카테고리의 다른 글
| OCP (Open-Closed Principle) 원칙 (0) | 2024.03.30 |
|---|---|
| 다형성 (Part.2) 사용하기 ✨ (0) | 2024.03.29 |
| 상속 (Part.2) (0) | 2024.03.28 |
| 상속 (Part.1) (0) | 2024.03.28 |
| final (0) | 2024.03.27 |