추후에 설정 내용이 더 추가될 예정이다. 지금은 저 csrf를 disable()하는것에 초점을 두자. 우선 csrf는 무엇인지부터 확인해보자.
csrf
Cross Site Request Forgery의 약자로 사이트 간 위조 요청을 말한다. 이는 정상적인 유저가 의도치 않게 비정상적인 요청을 하는 것을 말하는데 특정 사이트에 정상 권한을 가지고 있는 유저에게 비정상적인 링크를 누군가가 보내고 그 링크를 아무런 의심없이 해당 유저가 클릭할 때 역시 이 비정상적인 요청을 할 수 있다. 그리고 해당 사이트는 이러한 요청에 대해 이 사용자가 악용된 사용자인지 일반 유저인지 구분할 수 없다.
그래서 이를 방어하기 위해 csrf 토큰을 웹 사이트에서는 부여하여 이 토큰이 요청에 포함되어야만 요청을 받아들인다. 그럼 csrf를 왜 disable()했을까?
REST API만을 사용한다면 CSRF는 의미가 없다. Spring security 문서를 보면 non-browser-clients만을 위한 서비스라면 csrf를 disable해도 상관이 없다. REST API만을 이용하는 클라이언트는 요청 시 요청에 인증 정보(예: JWT)를 포함하여 요청하고 서버에서 인증 정보를 저장하지 않기 때문에 굳이 불필요한 csrf 코드들을 포함할 필요가 없는것이다.
그니까 결론은, 브라우저를 이용하지 않고 모든 요청은 REST API로 들어온다면 CSRF 관련 코드를 빼주는 게 더 효율적인 서비스가 될 수 있다.
authorizeHttpRequests()
두번째 라인은 특정 패턴의 요청이 들어왔을 때 요청을 허용할지에 대한 코드이다. 다음 코드를 보자.
findUserById(Long id)와 findAll() 메서드를 구현하는데 내용은 간단하다.
findAll()은 repository에 위임하는것이 끝이고 findUserById(Long id)는 유저 아이디를 파라미터로 받으면 repository에서 먼저 유저를 찾은 후 있다면 ModelMapper를 이용해서 DTO로 변환한다. 유저는 추후에 만들 Order MicroService에 존재하는 주문 내역을 가지는데 우선은 Order MicroService를 만들지 않았으니 유저가 가지고 있는 주문 내역은 빈 리스트로 넣어 반환한다.
컨트롤러를 보면 getUsers()와 getUser(@PathVariable Long id)가 있다.
전체 조회 코드를 먼저 보면, 서비스로부터 전체 유저 데이터를 받아온다. 그 다음 받아온 결과를 DTO로 변환해주는 코드가 필요하다.
항상 컨트롤러에서 데이터를 반환할 땐 엔티티 자체가 아닌 DTO로 변환하여 돌려주어야 한다. 그래야 해당 엔티티의 변화에도 API 스펙에 영향이 가지 않을 뿐더러 (사실 이게 제일 중요) 엔티티를 리턴하는 것 자체가 좋은 방법이 아니다. 불필요한 데이터까지 API에 모두 태울 수 있으니.
단일 조회 코드를 보면, URI로부터 유저 ID를 받아온다. 그 ID로 서비스로부터 유저를 조회하여 받아온다. 받아온 유저를 역시나 DTO로 변환한다. 굳이 ResponseUserDto와 ResponseUsersDto로 구분지은 이유는 전체 유저를 조회할 땐 유저의 주문 내역을 반환하지 않기 위해서다.
package com.example.tistoryuserservice.vo;
import jakarta.validation.constraints.Email;
import jakarta.validation.constraints.NotNull;
import jakarta.validation.constraints.Size;
import lombok.Data;
@DatapublicclassCreateUser{
@NotNull(message = "Email must be required")@Size(min = 2, message = "Email should be more than two characters")@Emailprivate String email;
@NotNull@Size(min = 2, message = "Name should be more than two characters")private String name;
@NotNull@Size(min = 8, message = "Password should be more than 8 characters")private String password;
}
@NotNull, @Size, @Email과 같은 어노테이션은 방금 내려받은 dependency에 의해 사용할 수 있다. 이런 제약조건을 걸어놓으면 payload로 받은 데이터를 이 클래스에 담으려고 할 때 조건에 해당하지 않으면 담지 못한다. 이와 같이 유효성 검사를 간단하게 적용할 수 있다.
DTO
이제 DTO를 만들 차례다. 즉, 외부 요청에 의해 전달된 새로운 유저를 만들 데이터를 DB에 저장하기 전 DB에 들어갈 알맞은 형식의 데이터가 필요한데 그때 사용되는 클래스라고 보면 된다.
dto 패키지를 추가한 후 CreateUserDto라는 클래스로 만들고 위와 같이 작성했다. CreateUser 클래스에는 없는 userId, createdAt, encryptedPassword 필드는 DB에 넣기 전 서비스 클래스에서 추가될 내용이고 나머지는 CreateUser 클래스에서 받아올 거다.
CrudRepository
이제 CrudRepository를 사용해서 기본적인 CRUD API를 제공하는 JPA의 도움을 받을 것이다.
repository라는 패키지를 하나 만들고 그 안에 UserRepository 인터페이스를 생성하자.
이 서비스 클래스에서 createUser()를 구현하고 있다. 여기서는 DTO에는 없는 userId와 encryptedPassword를 직접 추가해 준다. encryptedPassword를 만들어 내는 것을 구현하지 않았기 때문에 일단은 텍스트로 써넣는다. 이건 추후에 구현 예정이다.
DTO 데이터를 가지고 실제 데이터베이스에 들어갈 User라는 Entity로 타입 변환을 해준다. 그리고 그렇게 변환한 객체를 UserRepository를 주입받아서 save() 메서드를 호출한다. CrudRepository가 제공하는 save() 메서드에 어떠한 문제도 발생하지 않는다면 정상적으로 DTO 데이터를 다시 리턴한다.
이제 이 서비스 클래스를 호출할 Controller를 구현해야 한다. 실제로 유저가 사용할 API를 받아줄 수 있는.
@Configuration어노테이션을 추가하면 스프링 부트가 자동으로 이 클래스를 설정 처리해준다.
그리고 그 클래스 내부에 @Bean으로 등록한 메소드를 하나 만들고 RouteLocatorBuilder 인스턴스를 build()한다.
이 RouteLocatorBuilder로 라우트 별 설정을 할 수 있다. 이 gateway로 들어오는 요청의 path가 /user-service로 시작하는 모든 요청에 대해 RequestHeader와 ResponseHeader를 추가한다. Header를 추가할 때 key/value쌍으로 추가하면 되는데 이렇게 추가를 할 수 있고 그 요청에 대한 URL을 http://localhost:8081로 보낸다는 의미에 uri()가 있다.
이렇게 Config파일을 하나 만들고 서버를 재실행한 후 UserService에 새로운 Request Controller를 만들어보자.
UserService
package com.example.tistoryuserservice.controller;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestHeader;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@Slf4j@RestController@RequestMapping("/user-service")publicclassStatusController{
@GetMapping("/welcome")public String welcomePage() {
return"Welcome ! This is User Service.";
}
// 새롭게 추가한 부분@GetMapping("/message")public String message(@RequestHeader("user-request") String header) {
log.info("header: {}", header);
return"header check";
}
}
새로운 GetMapping 메소드를 추가했고 Parameter로 RequestHeader를 받는 header 하나를 넣었다. 이렇게 파라미터에 요청 헤더를 받아올 수 있는데 이 헤더값을 로그로 찍은 후 "header check" 이라는 문자열을 응답 메세지로 반환한다.
이제 /user-service/message로 요청을 해서 filter가 동작하는지 확인해보자.
Filter 동작 확인하기
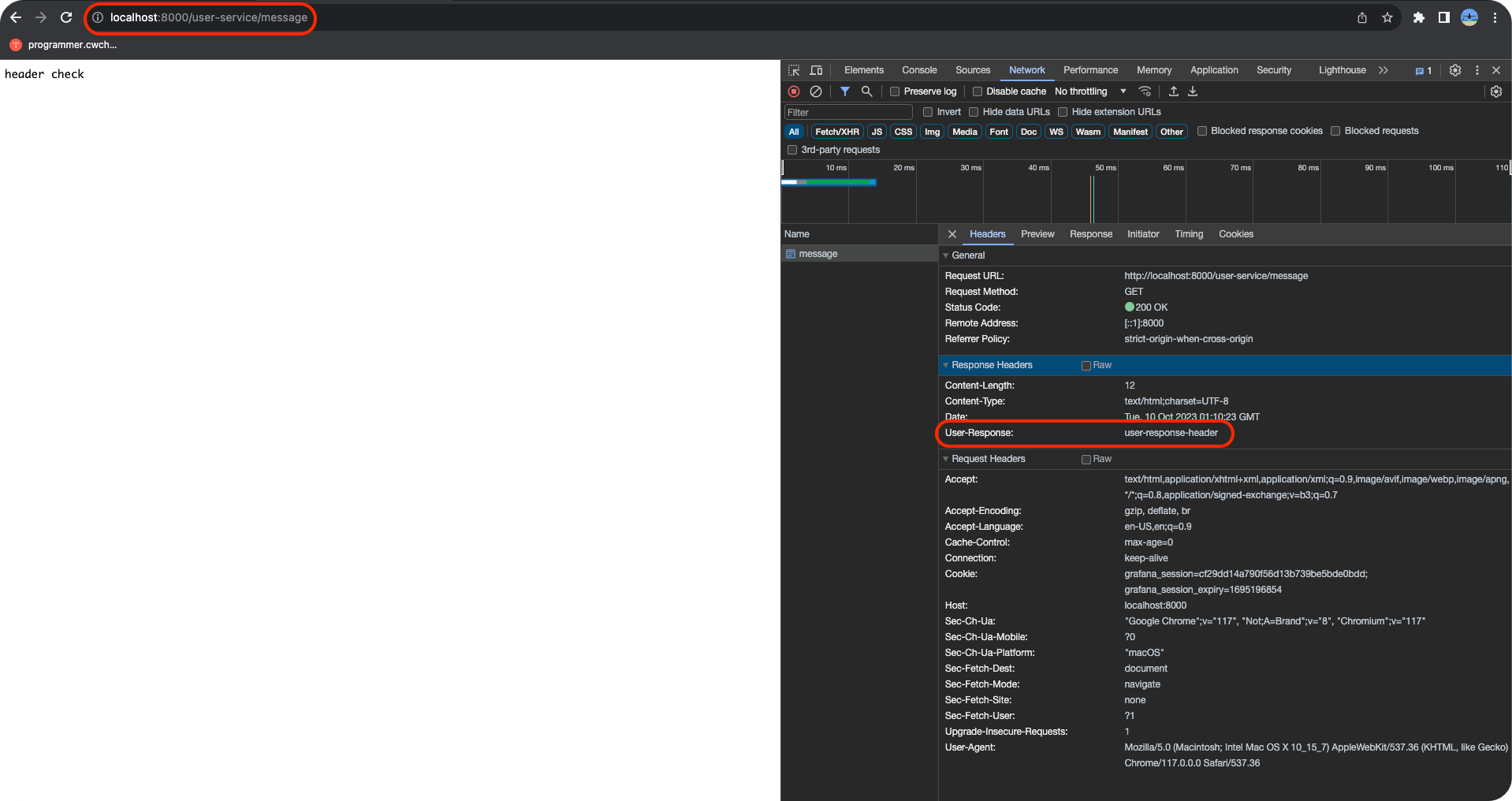
위 사진처럼/user-service/message로 요청을 보냈을 때 Response Headers에User-Response라는 key가 담겨있는것을 확인할 수 있다. key에 대한 value는 'user-response-header'라고 명시되어 있음을 확인할 수 있다.
여기서 한가지 더 확인할 수 있는건 Request Header에는 추가한"user-request"가 들어가 있지 않는것을 볼 수 있는데 이는 filter를 거치기 전 request header에 정보이기 때문이다. 완벽하게 filter가 정상적으로 동작하고 있는것이다.
그 filter를 거친 request header의 값은 어디서 확인하냐면 UserService의 Controller에서 파라미터에 넣었던 @RequestHeader를 통해 확인할 수 있다.
그러니까 흐름은외부 요청 -> Gateway -> Filter -> UserService이렇게 진행되고 위 브라우저에서는 외부 요청단계에 머물러 있는것이고 로그로 찍힌 상태에서는 UserService에 도달한 상태. 이렇게 외부 요청을 중간에 가로채서 추가적인 작업을 Filter를 통해서 수행할 수 있다.
이렇게 Filter를 설정할 수도 있고 application.yml 파일로도 Filter를 추가할 수 있다. 그것도 한 번 해 볼 생각이다.
application.yml 파일로 filter 추가하기
우선 위에서 등록해봤던 @Configuration을 주석처리하자. filter를 application.yml 파일로 설정할 생각이니까.
spring.cloud.gateway.routes.filters에CustomFilter를 추가했고 그 전에 입력한 AddRequestHeader와 AddResponseHeader는 주석처리했다. 이렇게 설정한 후 재실행 시켜서 다시 UserService에 요청을 보내보자.
UserService가 응답할 수 있는 어떤 요청도 상관없이 요청을 보내보면 gateway service에서 확인할 수 있는 로그가 있다.
필터가 적용된 UserService에 대한 요청이 들어왔을 때 찍힌 로그가 보인다. 이렇듯 사용자 정의 필터를 원하는 서비스마다 적용시킬 수 있다.
GlobalFilter 추가하기
GlobalFilter는 gateway service로부터 들어오는 모든 요청에 대해 필터를 적용하는 것이다.
이 또한 CustomFilter를 만드는것과 비슷하게 만들 수 있다.
filter 패키지 안에 GlobalFilter.java 파일을 만들고 다음과 같이 작성했다.
GlobalFilter는 CustomFilter 만들 때와 거의 유사하다. 똑같다고 봐도 되는데 코드에서 달라지는 부분은 Config 클래스에 properties가 추가됐다. baseMessage, preLogger, postLogger 세 개의 필드를 추가했고 이 값은 application.yml 파일에서 지정해 줄 것이다.
application.yml 파일에서 spring.cloud.gateway.default-filters에 GlobalFilter가 추가됐음을 확인할 수 있다. 이렇게 default-filters로 추가하면 어떤 라우트가 됐던간 이 gateway를 통과하는 모든 요청은 저 필터를 거친다.
그리고, args로 Config 클래스에서 만든 세 가지 필드 baseMessage, preLogger, postLogger 값을 설정했다.
이렇게 작성하고 gateway-service를 재실행해서 UserService에 요청을 날려보자. 그럼 gateway service에서 이런 로그를 확인할 수 있다.
보면 GlobalFilter가 가장 먼저 시작하고 GlobalFilter가 끝나기 전 CustomFilter가 동작해서 끝나고 난 후 GlobalFilter가 마지막으로 끝난다. 모든 필터는 이렇게 동작한다. GlobalFilter로 설정한 필터가 제일 먼저 시작해서 제일 나중에 끝난다.
LoggingFilter 추가하기
필터를 하나 더 추가해서 적용했을 때 필터의 우선순위에 따라 필터가 적용되는 순서가 달라짐을 확인해보고 적절하게 사용할 수 있도록 해보자. CustomFilter, GlobalFilter를 만든 패키지에 LoggingFilter.java 파일을 만든다.
이번에는 Lambda식이 아니고 인스턴스 생성 후 인스턴스를 리턴하는 방식으로 구현해보자. 정확히 같은 내용인데 이렇게 된 코드를 Lambda 표현식으로도 사용할 수 있음을 이해하기 위해서 이렇게 작성했다.
다른건 다 똑같고 OrderedGatewayFilter()의 두번째 인자로 Ordered.LOWEST_PRECEDENCE를 적용하면 이 LoggingFilter가 가장 나중에 실행된다. Ordered.HIGHEST_PRECEDENCE도 있는데 이는 GlobalFilter보다도 더 먼저 실행된다. 그래서 그 차이를 확인해보자.
API Gateway를 구현해보자. 그 전에 API Gateway가 있을 때 얻는 이점이 무엇이길래 이 녀석을 구현하는지 알아보자.
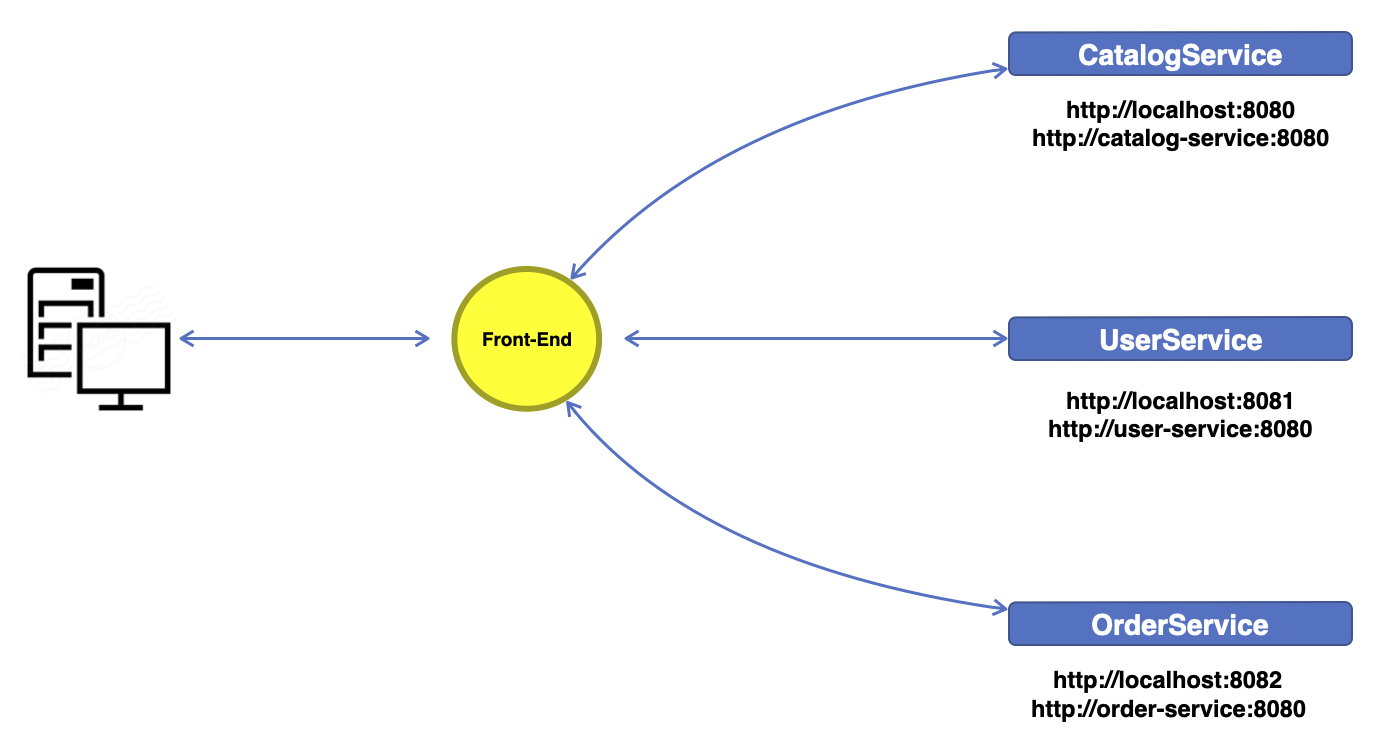
API Gateway가 없을 때 외부에서 어떤 요청을 하면 그 요청을 앞 단에서 해당 요청을 처리하는 서비스(뒷 단)와 통신하여 응답을 외부에게 돌려주는 구조가 될 것이다. 이 상태에서는 어떤 문제도 없지만 만약 기존에 있던 서비스들 중 어떤 것이 URL이 변경된다던지, 서비스를 운영하는 서버가 이전된다던지 등 어떤 변화가 생기게 되면 서비스의 URL같은 호출 정보가 변경된다. 호출 정보가 변경되면 그 변경 사항에 맞게 앞 단은 다시 설정 작업을 해야하고 그 작업으로 인해 서비스는 다운타임이 발생한다.
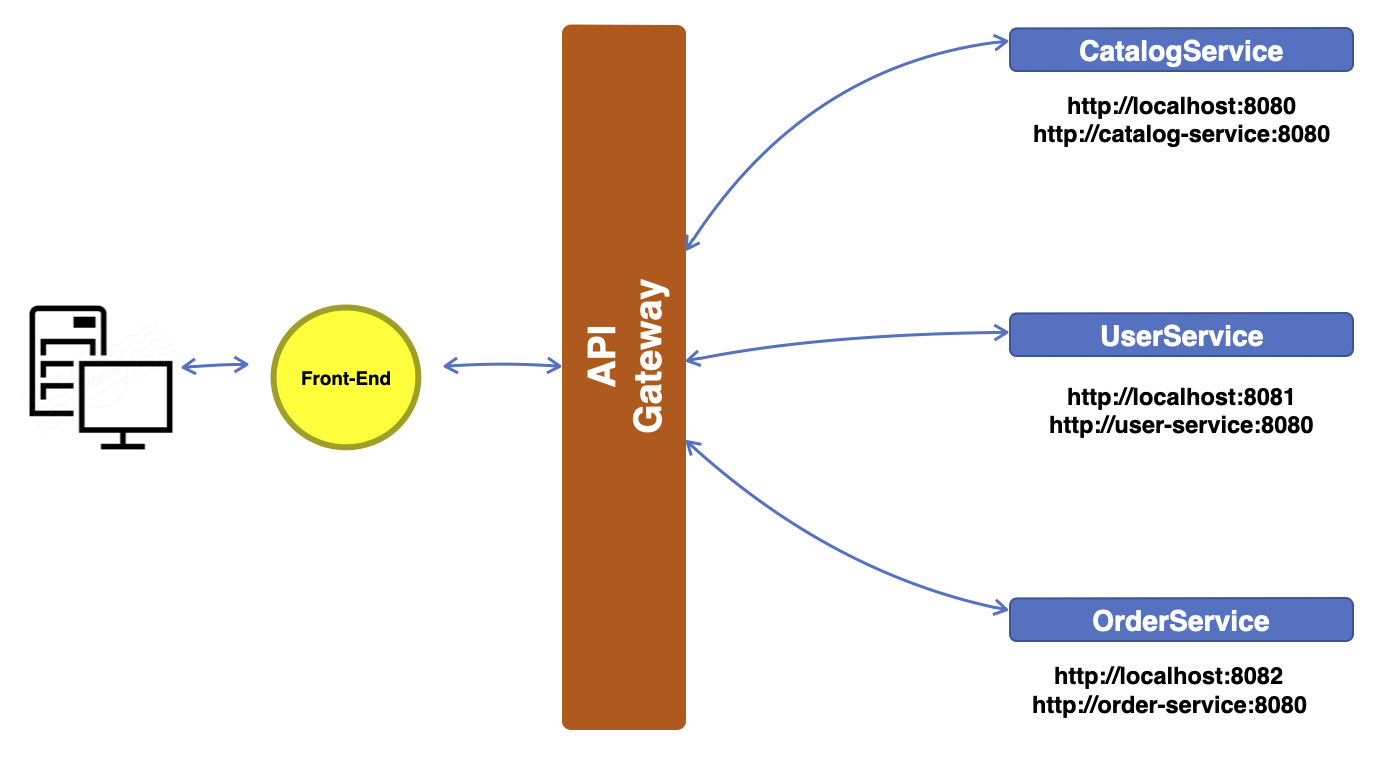
이와 반대로 API Gateway와 같은 중개자가 있는 구조를 살펴보자.
이런 구조를 가졌을 때 외부에서 요청이 들어오면 앞 단은 그 요청을 API Gateway에게 보내게 되고 API Gateway는 그 요청을 처리해주는 서비스에게 전달해주기만 하면 된다. 여기서 만약 위와 같은 상황인 서비스의 URL이 변경되거나, 서비스를 운영하는 서버가 이전된다거나 하더라도 앞 단에서 수정할 부분은 없다. 앞 단은 서비스가 무엇이 있는지조차 알 필요도 없다. 그저 API Gateway와 통신만 하면 되기 때문이다. 서비스를 운영하는 서버가 이전된 경우에 그 서버를 API Gateway에 등록(정확히는 Service discovery이지만 그림에서 표현하지 않았기에 편의상)하기만 하면 된다. 심지어 같은 서비스의 여러 인스턴스가 존재할 때 Load Balancing 처리도 해주기에 좋은 점은 늘어난다.
그럼 이제 API Gateway를 구현해보자.
Spring Cloud Gateway 생성
Spring Initializr로 빠르게 생성해보자.
이전과 전부 동일하고 이름만 변경한 뒤 Next
Dependencies는 Lombok과 Gateway를 선택하고 프로젝트 생성.
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.1.4</version><relativePath/><!-- lookup parent from repository --></parent><groupId>com.example</groupId><artifactId>tistory-gateway</artifactId><version>0.0.1-SNAPSHOT</version><name>tistory-gateway</name><description>tistory-gateway</description><properties><java.version>17</java.version><spring-cloud.version>2022.0.4</spring-cloud.version></properties><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring-cloud.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>
이번에는 전과 달리 Spring Initializr에서 모든 dependencies를 받아오는 게 아니라 직접 추가하는 법을 알아보자.
spring cloud gateway에 어떤 서비스들을 등록되어 라우팅될 것인지를 작성하는 부분인데 내가 만든 UserService를 이 gateway에 등록해서 UserService에 대한 요청이 들어오면 요청을 전달해준다. 그 때 작성하는 부분이 id, uri, predicates이다.
id는 고유값으로 서비스 이름을 설정했다. uri는 해당 서비스가 실행되고 있는 URL정보를 작성한다. predicates은 조건을 명시하는 부분인데 Path에 /user-service/**로 작성하게 되면 gateway로 들어오는 요청의 path 정보가 user-service가 붙고 그 뒤에 어떤 값이 들어오더라도 uri에 명시한 서비스로 요청을 전달한다.
이 application.yml 파일은 많은 변화가 있을 예정이지만 일단은 지금 상태로도 충분하다.
Start Gateway Server
이렇게 작성해놓고 Gateway Service를 실행시켜보면 다음처럼 정상적으로 실행됐다는 로그가 찍혀야한다.
정상적으로 Gateway Service가 올라왔고 이 Gateway를 통해 UserService를 호출했을 때 UserService로 요청이 전달되는지 확인해본다. 그러기 위해서는 UserService에 Controller가 필요하다.
UserService Controller
controller 패키지 하나를 만들고, 그 안에 StatusController.java 파일을 생성
package com.example.tistoryuserservice.controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController@RequestMapping("/")publicclassStatusController{
@GetMapping("/welcome")public String welcomePage(){
return"Welcome ! This is User Service.";
}
}
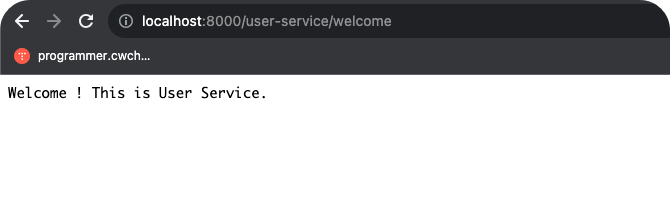
간단한 Welcome page를 만들었다. UserService의 /welcome으로 요청하면 "Welcome ! this is User Service."라는 문장이 노출되어야 한다. 그러나, gateway를 통해 요청해보면 다음과 같은 404 에러 화면을 마주하게 된다.
이런 현상이 발생하는 이유는 gateway를 통해 호출하는 경로 http://localhost:8000/user-service/welcome 이는 곧 gateway에서 routing 설정대로 http://localhost:8081/user-service/welcome으로 전달한다.
eureka.client.fetch-registry:true로 설정하면 eureka server로부터 갱신되는 서비스 정보들을 지속적으로 받겠다는 의미이다.
eureka.client.service-url.defaultZone: http://127.0.0.1:8761/eureka eureka server 정보를 기입하는 부분이다.
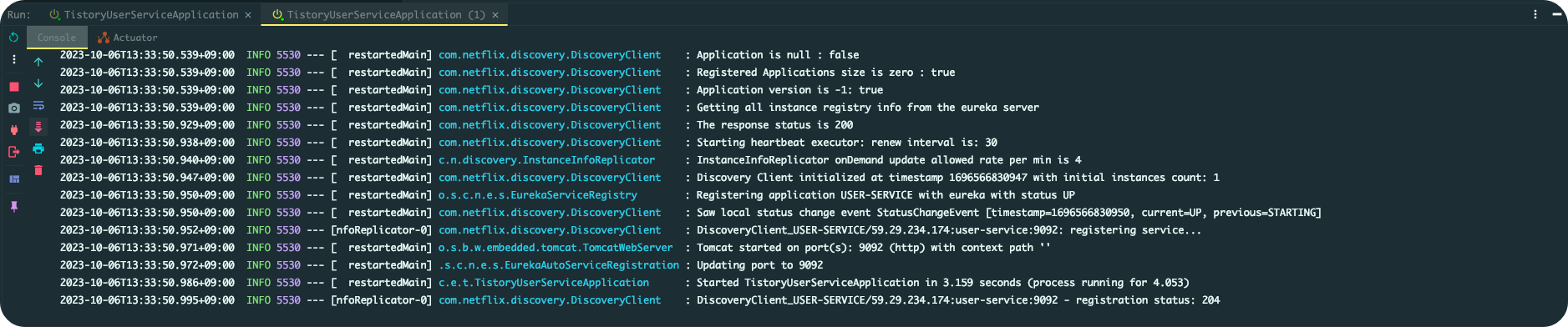
UserService 실행
이제 User Service를 실행해보자. 다음과 같은 로그가 출력되면 된다.
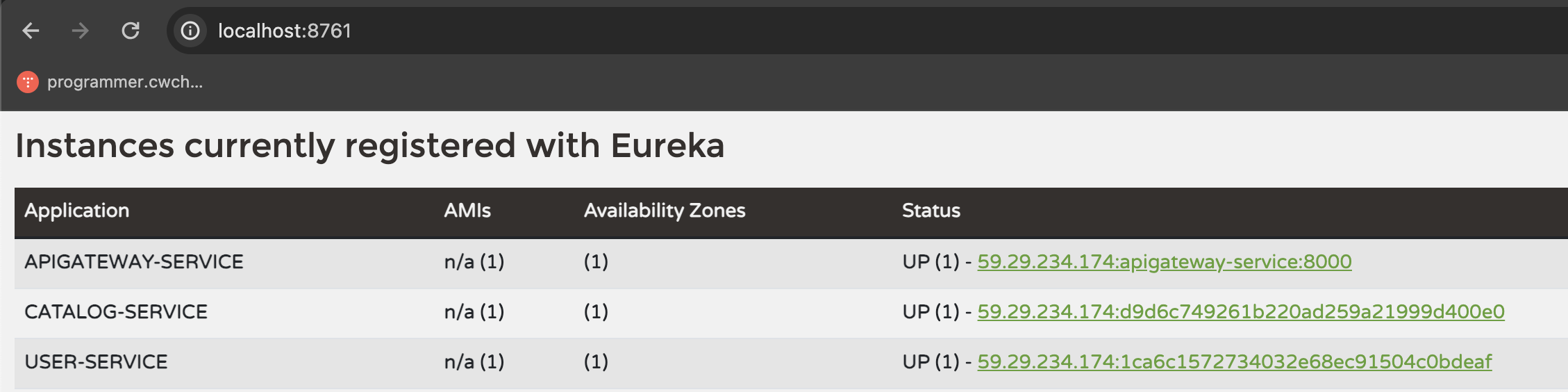
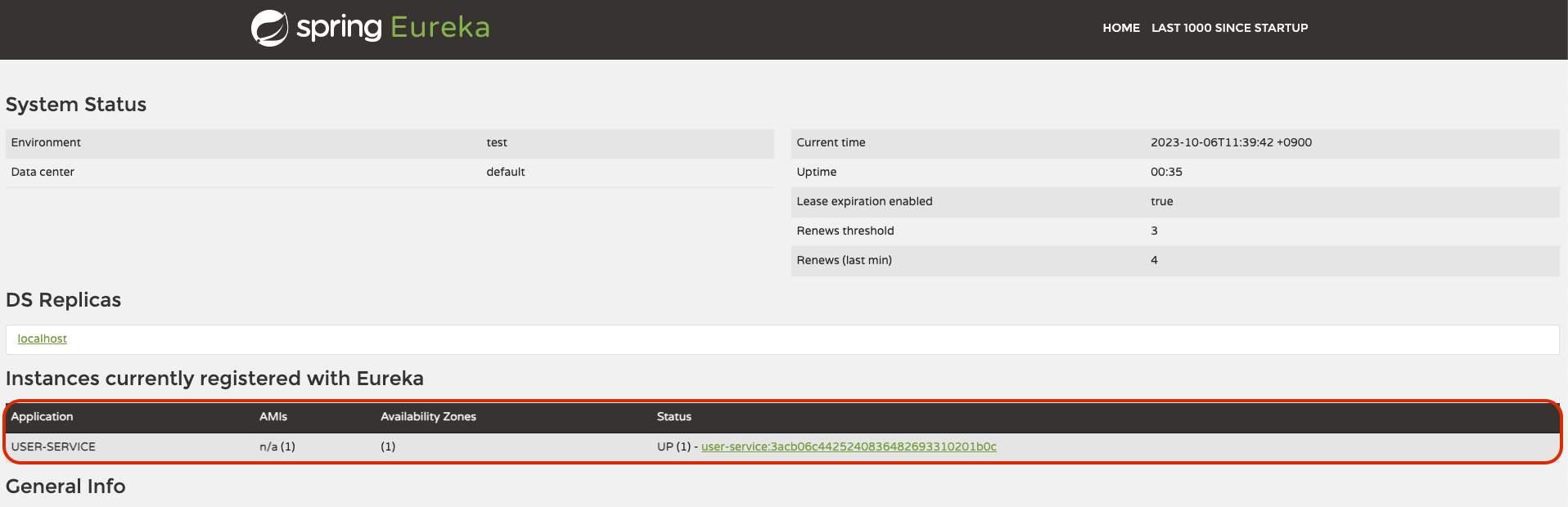
그리고 이렇게 정상 실행이 됐으면 Eureka server를 열어보자. User Service가 등록된 모습을 확인할 수 있다.
해당 라인에서 우측 Status 칼럼에 보면 UP(1)이라고 보인다. 한 개의 인스턴스가 띄워져 있는 상태란 의미이다. 한번 여러개를 띄워보자. 같은 서비스라 할지라도 포트를 나누어 더 많은 인스턴스를 띄울 수 있다. 그리고 이렇게 여러개의 인스턴스를 띄워서 부하 분산 처리가 가능해진다.
Start Multiple Instance
기본적으로 IntelliJ에서 상단 아이콘바에 실행버튼을 클릭하면 서버가 실행되는데 이 외 여러 방법으로 실행이 가능하다. 그리고 그 방법을 통해 여러개를 띄워보자.
첫번째는 Run/Debug Configurations이다.
사진처럼 실행할 애플리케이션 선택창을 클릭해서 Edit Configurations를 누르면 아래처럼 Run/Debug Configurations 창이 하나 노출된다.
위 창에서 빨간색 네모칸으로 표시한 "Copy configurations" 버튼을 누르면 현재 실행하고 있는 애플리케이션 구성과 동일한 또 다른 인스턴스의 애플리케이션 구성을 만들 수 있다. 그렇게 하나 추가하면 다른 인스턴스로 또 하나를 실행할 수 있다. 근데 그대로 복사해서 실행하면 같은 포트를 사용할 거기 때문에 포트 충돌 에러가 발생할것이다. 그래서 포트를 변경해줘야 한다. 다음 사진을 보자.
실행할 때 VM option을 추가해줄 수 있다. VM option에 application.yml 파일에 설정한 server.port값을 위 사진처럼 변경한다.
설정 후 Apply > OK
이렇게 새로운 Configurations이 생겼고 역시 실행 버튼 또한 활성 상태가 된다. 이 인스턴스도 실행해보자.
정상 실행이 되었고 9092 포트로 실행됐다는 로그가 보인다. 이 인스턴스 역시 Eureka Server에 등록될 것인데 한번 Eureka Server를 띄워보자. Status를 보면 UP(2) 라는 표시가 보인다.
2개의 유저 서비스가 띄워져있음을 그리고 그 서비스가 모두 같은 Eureka Server에 등록되어 있음을 확인할 수 있다.
Maven으로 빌드 후 패키징하는 명령어인데 clean은 기존에 패키징했던 것들을 전부 말끔히 지우고, compile은 빌드를 한다. package는 말 그대로 패키징을 하는 것이고 -DskipTests=true는 프로젝트 내 테스트 파일이 있을 때 테스트를 스킵한다는 의미이다.
그럼 프로젝트 루트 경로에 target이라는 폴더가 생기고 해당 폴더 안에 .jar파일이 생긴다.
.jar파일의 이름은 pom.xml파일에서 설정한 값으로 그대로 만들어지는데, 앞 부분은 <name></name>안에 설정된 값이고 뒷 부분은 <version></version>안에 설정된 값이다.
실행해보면 포트를 49318이라는 포트로 잡은 것을 확인할 수 있다. Eureka Server에서도 확인해보자.
여기서 0번 포트라고 표시되어 있다. 실제로 포트를 0번으로 잡은건 아니고 우리가 설정한 0이라는 값이 그대로 출력된 모습인데 이 링크를 실제 클릭해보면 같은 49318로 연결됨을 확인할 수 있다.
하나 더 띄워보자. 터미널에서 실행한 방법 그대로 실행해보는데 이번엔 포트를 명시하지 않고 실행해보자.
mvn spring-boot:run
역시나 임의의 포트로 자동 할당된 모습이다. 이렇게 일일이 포트를 직접 명시하는 게 아닌 랜덤 포트를 할당받는 방법으로 인스턴스를 여러개 기동시킬 수 있다.
근데 이대로는 문제가 있다. 어떤 문제냐면 Eureka Server를 다시 보면 분명 인스턴스를 두 개 띄웠지만 하나만 보여진다.
이는 왜일까? Eureka Server에서 서비스를 등록할 때 서비스를 표시하는 방법에서 원인이 있다.
서비스를 등록할 때 서비스 표현 방법을 59.29.234.174:user-service:0 이렇게 표현 하는데 이는 서비스가 띄워진 IP:서비스의 이름:서비스의 포트이다. 서비스의 이름과 서비스의 포트는 application.yml파일에서 설정한 spring.application.name값과 server.port값인데 이 두개의 차이가 인스턴스별 존재하지 않기 때문에 아무리 많이 몇 개를 띄우더라도 Eureka Server는 하나만을 표시할 것이다.
이를 수정하기 위해, eureka.instance.instance-id 값을 부여해야한다.
이렇게 application.yml파일을 수정 후 다시 인스턴스 두 개를 실행한 뒤 Eureka Server를 다시 확인해보자.
이제는 서버의 IP뒤에 알수없는 랜덤값이 표시된 것을 확인할 수 있고 띄운 인스턴스 개수만큼 표시됨을 확인할 수 있다. 이렇게 여러개의 인스턴스를 띄우고 같은 Eureka Server에 등록하는 방법을 알아봤다. 이렇게 여러개의 인스턴스를 띄워서 서비스를 운영하면 유저가 요청을 했을 때 해당 요청을 처리할 수 있는 인스턴스들 중 남는(놀고있는) 인스턴스를 찾아 그 인스턴스에게 요청을 할당하는 Load Balancing기술을 사용할 수 있게 된다.
User Service 내 API 및 비즈니스 로직을 구현하기 전 API Cloud Gateway를 구현해보자.
Spring Cloud Netflix Eureka는 Service discovery tool을 말한다. Service discovery는 분산 시스템에서 각 인스턴스(서비스)들을 등록하고 관리해 주는데 관리해 준다는 건 외부에서 요청이 들어올 때 그 요청을 처리할 수 있는 인스턴스(서비스)가 어떤 서비스인지를 찾아주는 것을 포함한다.
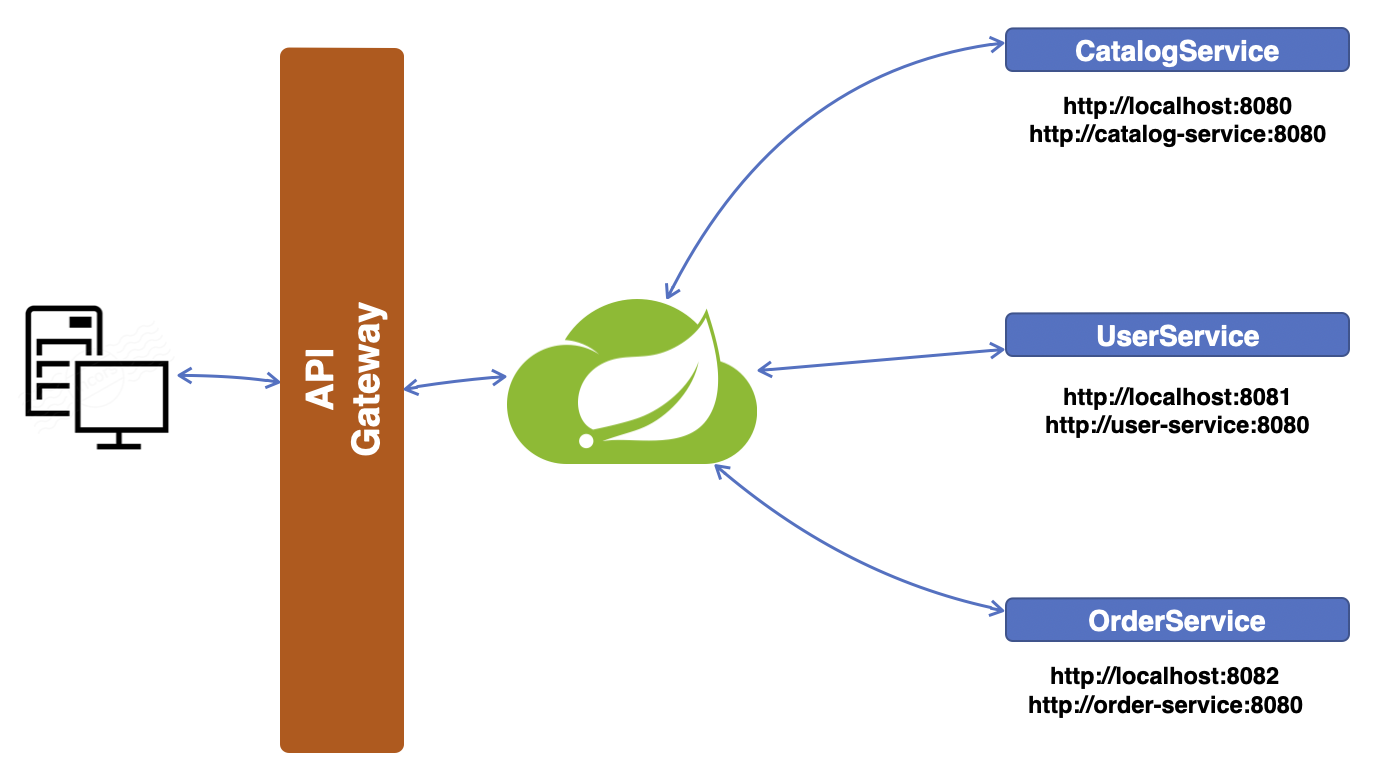
위 그림에서 Netflix Eureka는 API Gateway 바로 다음 단계에 존재하는데, 서비스에 외부 요청이 들어오면 API Gateway는 요청을 받아 해당 요청을 처리할 수 있는 서비스를 찾기 위해 Eureka에게 물어본다. Eureka는 해당 요청을 처리할 수 있는 서비스가 본인한테 등록된 게 있는지 확인 후 있다면 해당 서비스에게 요청을 전달한다. 이렇게 각 서비스들을 관리하고 등록하는 작업을 하는 게 Service discovery고 Spring에서는 Netflix Eureka를 사용할 수 있다.
위 그림에서 각 서비스는 각기 다른 서버에서 구현될 수도 있고 같은 서버내에 포트번호를 다르게 설정하여 동시에 띄울 수 있다. 그에 따라 각 서비스별 호출 URL이 달라질 수 있음을 그림에서 표현한다. 이제 이 Service discovery를 직접 구현해 보자.
Spring Eureka Server 생성
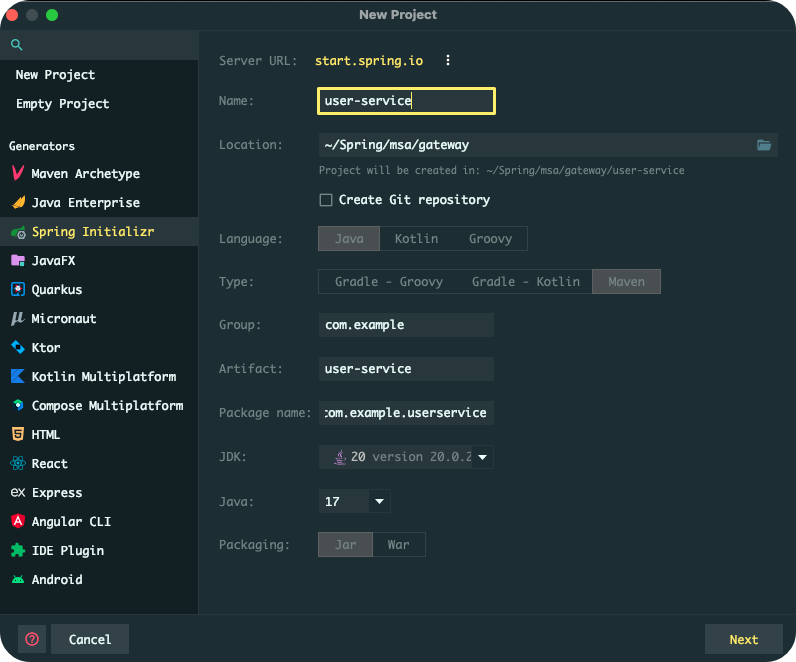
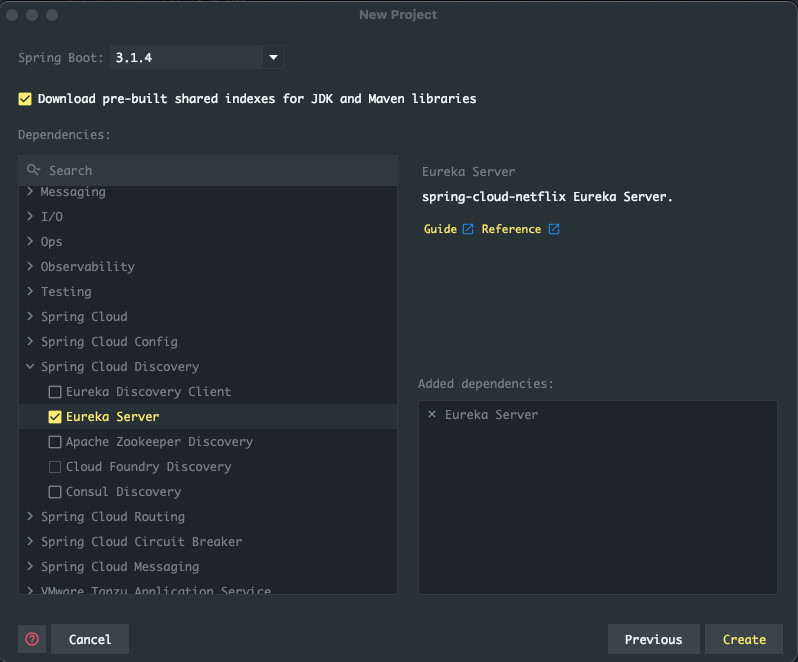
IntelliJ IDEA를 이용해서 프로젝트를 생성할 거다. 우선 New Project로 프로젝트를 만들기 시작하면 좌측 Generators 섹션에 Spring Initializr가 보인다.
여기서 나는 다음과 같이 설정을 했다.
Name, Location은 원하는 대로 설정하면 되고 Language는 Java를 Type은 Maven을 설정했다.
Group은 회사라면 회사 도메인을 거꾸로 쓰는 게 일반적이다. 여기서는 그냥 com.example로 설정했다.
Artifact는 애플리케이션 이름을 작성하면 되며
Package name은 Group.Artifact를 이어 붙여서 설정한다.
JDK는 20으로 설정했고 Java 버전은 17로 설정했다.
Packaging은 Jar를 선택하면 된다.
Next를 누르면 Spring Boot 버전과 Dependencies를 설정할 수 있다.
Spring Boot는 3.1.4 버전을 선택했고 좌측 Dependencies에서 Spring Cloud Discovery > Eureka Server를 선택한다.
선택하면 우측 Added dependencies 항목에 선택한 dependencies들이 추가되는 것을 확인할 수 있다.
Create 누르면 프로젝트가 생성된다.
pom.xml
프로젝트가 생성되면 가장 먼저 확인할 것은 pom.xml 파일이다. 내가 선택한 Eureka dependency가 잘 추가되었는지, 다른 설정에 이상은 없는지 확인해 보자.
<?xml version="1.0" encoding="UTF-8"?>
<projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.1.3</version><relativePath/><!-- lookup parent from repository --></parent><groupId>com.example</groupId><artifactId>discovery-service</artifactId><version>0.0.1</version><name>discovery-service</name><description>discovery-service</description><properties><java.version>17</java.version><spring-cloud.version>2022.0.4</spring-cloud.version></properties><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring-cloud.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>
spring-cloud-starter-netflix-eureka-server가 dependency로 잘 등록되어 있는 것을 확인할 수 있으며 아래쪽 spring-cloud-dependencies로 version이 ${spring-cloud.version}으로 명시된 것을 확인할 수 있는데 이는 위에 properties안에 <spring-cloud.version>2022.0.4<spring-cloud.version>로 세팅된 값을 가져온다.
문제없이 잘 등록된 것 같다.
@SpringBootApplication
다음으로 확인할 것은 현재 상태에서 유일하게 생성되어 있는 .java 파일이다. 이 파일에서 main()이 있고 스프링은 최초의 시작점을 이 파일로 시작하는데 그때 필요한 Annotation이 @SpringBootApplication이다. 이 어노테이션이 있는 파일을 Spring Boot가 찾아서 최초의 시작을 한다.
server.port는 8761로 spring.application.name은 discoveryservice로 설정했다. 일반적인 설정 내용이고 중요한 부분은 eureka항목이다. 두 가지 설정을 해줬다.
eureka.client.register-with-eureka: false
eureka.client.fetch-registry: false
Eureka server로 기동 할 서버인데 왜 client값을 설정해야 하는가에 대한 의문이 생기는데 이 내용은 spring boot가 기본적으로 eureka server를 띄우면 본인도 eureka에 서비스로 등록이 된다. 그러나 본인은 서버이기 때문에 eureka에서 서비스로 등록할 필요가 없기 때문에 본인은 client로 등록하지 않을 것을 명시하는 설정값이라고 생각하면 된다.
Started Eureka Server
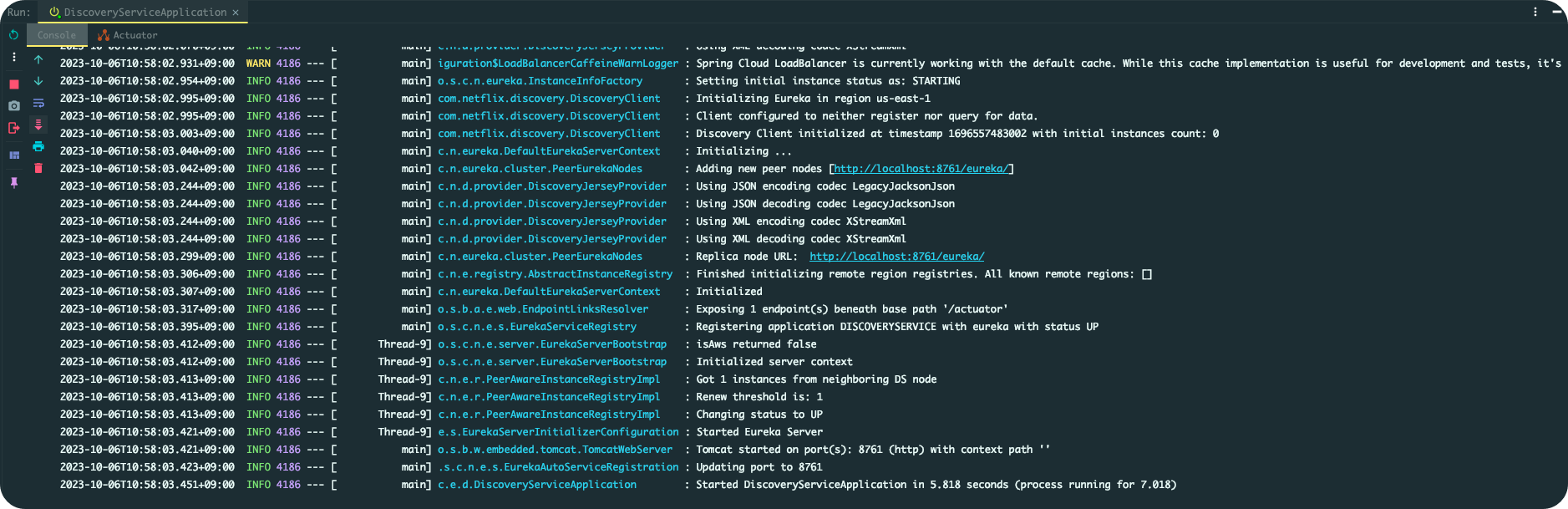
이제 필수적으로 수행할 설정을 다 끝냈으니 서버를 시작해 보자. 서버를 시작하면 하단에 Console창에 아래 같은 로그가 출력되어야 한다.
2023-10-06T10:58:50.210+09:00 INFO 4334 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8761 (http) with context path ''
2023-10-06T10:58:50.212+09:00 INFO 4334 --- [ main] .s.c.n.e.s.EurekaAutoServiceRegistration : Updating port to 8761
2023-10-06T10:58:50.214+09:00 INFO 4334 --- [ Thread-9] e.s.EurekaServerInitializerConfiguration : Started Eureka Server
2023-10-06T10:58:50.244+09:00 INFO 4334 --- [ main] c.e.d.DiscoveryServiceApplication : Started DiscoveryServiceApplication in 4.949 seconds (process running for 6.551)
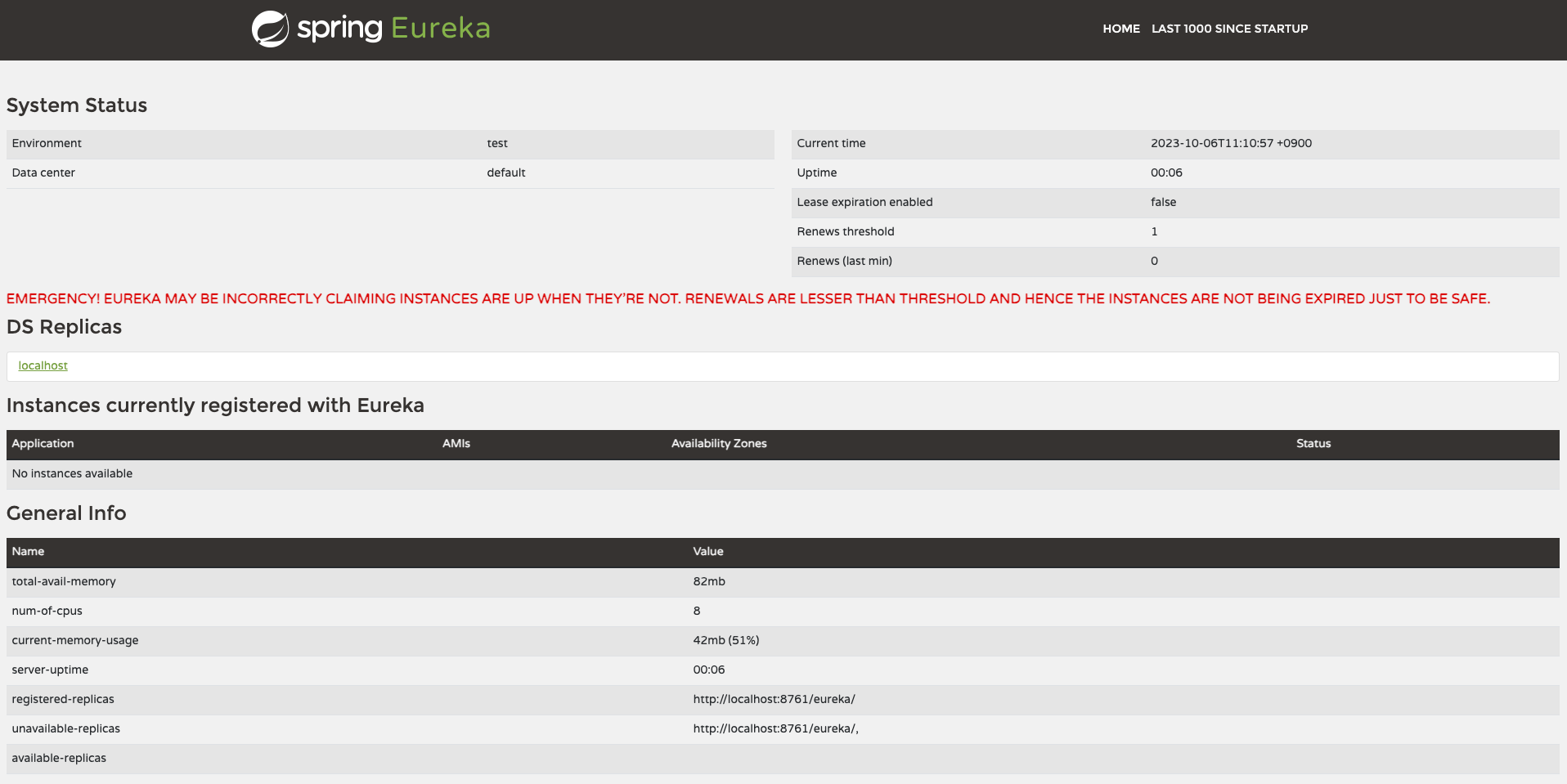
서버를 띄웠으니 웹 브라우저에서 http://localhost:8761을 입력해 진입해 보면 다음과 같이 Eureka server가 띄워진다.
Spring Cloud는 분산 시스템 (MSA 역시 포함)에서 흔하게 사용되는 구조 및 패턴을 쉽게 빌드 및 배포할 수 있도록 도와주는 툴을 제공해 준다. 그런 분산 시스템에서 흔하게 사용되는 기능(툴)이란 건 configuration management, service discovery, circuit breakers, routing, proxy, control bus, authentication, cluster 등 여러 기술이 있다.
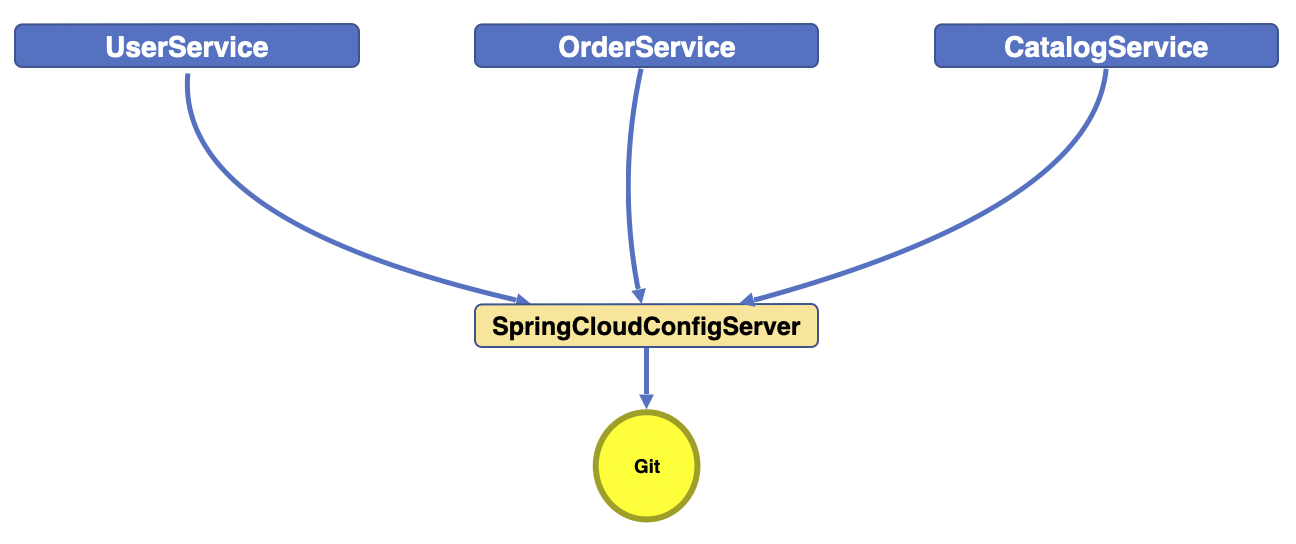
Distributed/versioned configuration은 각 서비스마다 필요한 세팅 및 환경변수가 존재하기 마련인데 이런 모든 필요한 세팅을 한 곳에서 관리하여 유지보수 및 환경 세팅의 변화가 생겼을 때 서비스의 재빌드 및 재배포를 거치지 않고 서비스를 다운타임 없이 지속 운영할 수 있는 방법을 말한다. 아래 그림을 보자.
위 그림처럼 각 서비스마다 필요한 환경과 세팅 내용을 한 곳에서 관리하고 그 관리하는 서버를 Git과 연동하여 Spring Cloud Config Server는 Git으로부터 저장되어 있는 환경 정보를 불러와 각 서비스들에게 제공한다.
Service discovery, registration은 Part 1에서 말한 Spring Eureka와 같은 도구를 말한다. 각 서비스들을 등록, 관리하여 이 분산 시스템에서 사용되는 서비스들은 어떤것들이 있고 각 서비스들을 상황에 맞게 관리해 주는 역할을 한다.
Routing, Load Balancing, Service to service calls은 Spring Cloud Gateway로 구현할 수 있는데 클라이언트로부터 요청을 받아 해당 요청을 처리할 수 있는 서비스에게 요청을 전달하며 전달할 때 부하를 분산해주며 각 서비스와 서비스 사이에서 요청을 전달하고 전달받을 수 있게 도와준다.
Circuit Breakers는 장애 처리를 도와주는 기술인데 위 그림이랑 똑같이 서비스가 총 3개가 있다고 가정했을 때, 유저가 유저 정보를 확인하기 위해서 유저 정보를 확인하는 요청을 했을 때 유저 정보에는 본인이 주문했던 또는 주문 중인 이력도 존재한다. 이때 주문 이력을 알아오기 위해 오더서비스를 호출하는데 오더서비스에 문제가 생겼을 때 오더서비스 하나 때문에 전체 유저 정보를 못 가져온다면 사용자 경험은 좋지 못할 것이다. 이때 서킷브레이커를 이용해서 오더서비스로부터 데이터를 받아오지 못하더라도 유저 정보만은 데이터를 가져올 수 있도록 처리해 줄 수 있다. 이 내용도 차차 구현해 보도록 하겠다.
요즘 한창 재미 들려 공부하는 MSA. 하나도 빠짐없이 배우고 공부한 내용을 기록해 보고자 한다.
MSA(MicroService Application)
우선 MSA는 Micro Service Application의 약자로, 어떤 서비스가 가진 기능을 제공할 때 하나의 큰 애플리케이션에서 모든 기능을 수행하는 것이 아니라 기능별, 특징별, 구성별로 서비스들을 작게 나누어 각 기능에 특화된 하나의 작은 서비스를 구축하고 그 구축한 여러 개의 서비스들이 모여 거대한 하나의 애플리케이션이 되는 형태를 말한다.
위 사진에서 우측 SERVICE A, SERVICE B가 있다. 이 두 개의 서비스들은 각자 자신이 수행해야 할 최소 단위의 기능들만을 모아 구성된 하나의 작은 서비스다. 예를 들어, 쇼핑몰 기능을 제공하는 하나의 서비스에 결제 관련 기능을 담당하는 SERVICE A, 장바구니 관련 기능을 담당하는 SERVICE B로 나뉘어 그렇게 각 모든 작은 서비스들이 모여 하나의 큰 서비스를 이루는 것처럼 말이다.
사용자는 이 쇼핑몰이 어떤 구조로 서비스를 제공하는지 알 필요 없이 단순하게 쇼핑몰 사이트에 들어가 원하는 행위를 하면 그 각각의 행위가 필요한 기능, API를 서비스 내에서 알아서 관리하고 호출, 신청, 반환, 응답하면서 서비스가 수행된다.
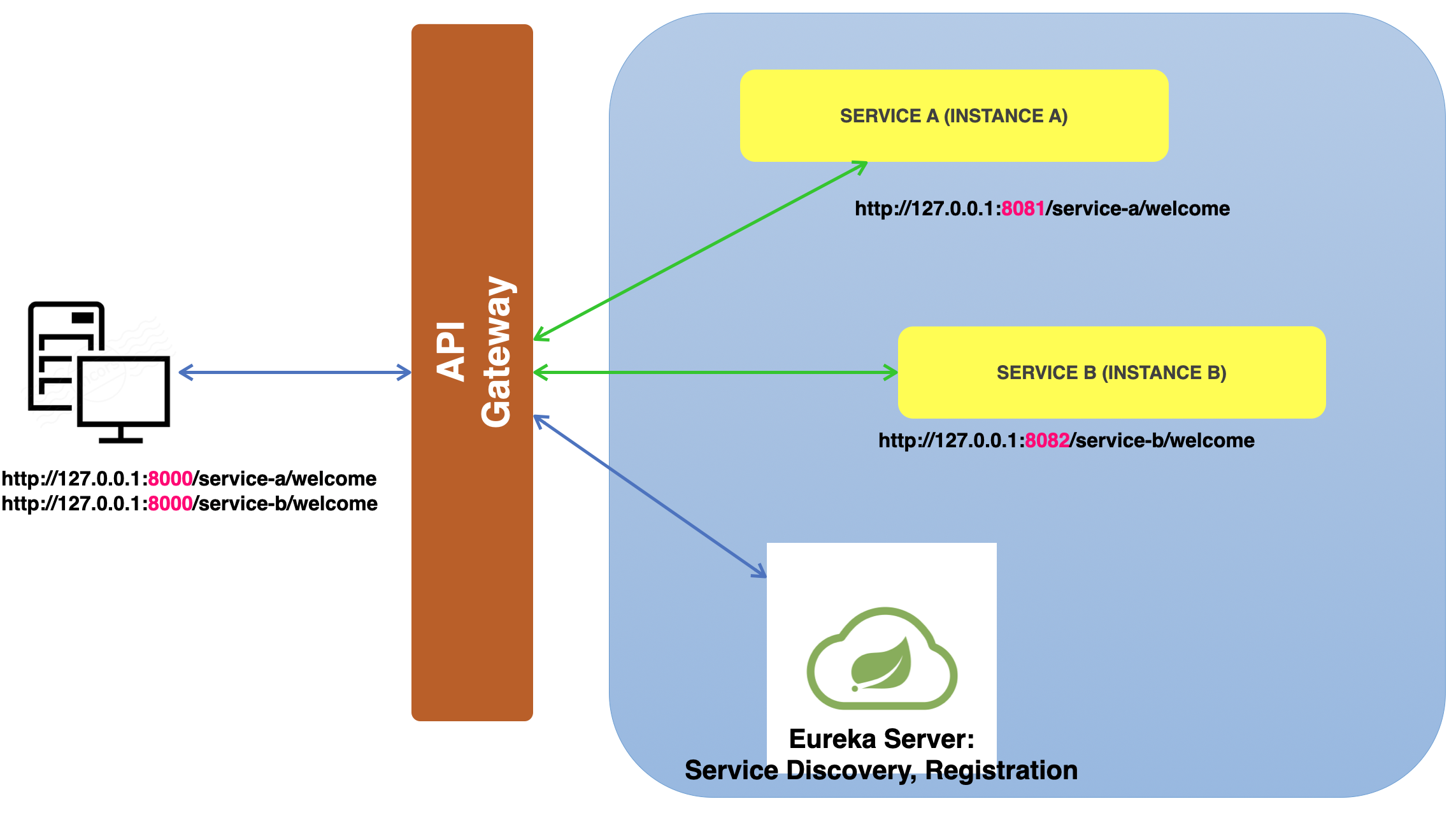
위 사진에서는 클라이언트에서 요청을 하는 게 첫 번째 흐름인데 요청을 SERVICE A 또는 SERVICE B에 직접적으로 하는 게 아닌 중간에 있는 API Gateway에게 요청한다. API Gateway 역시 Microservice가 된다. API Gateway는 외부의 모든 요청을 이 녀석이 책임지고 받아 이 요청을 처리할 수 있는 서비스를 찾아서 그 서비스에게 돌려주는 Service Discovery Server(Netflix Eureka)에게 전달한다.
여기서 잠깐 Eureka에 대해 얘기하자면, Eureka는 Netflix에서 분산된 서비스들을 등록하고 관리하는 도구이다. 이 Eureka는 분산된 시스템 구조에서 각 서비스들을 등록, 관리, 소통하게 해준다. 이 Eureka를 Service discovery tool이라고 한다.
Eureka 서버는 해당 요청을 처리할 수 있는 서비스를 찾아서 API Gateway에게 그 서비스를 알려주면 API Gateway는 해당 서비스에게 요청을 전달해 준다. 받은 요청을 처리할 수 있는 서비스는 해당 서비스를 처리 후 응답할 결과를 API Gateway에게 다시 돌려주고 최종적으로 클라이언트에게 돌아가게 된다.
전반적인 흐름을 봤을 때 이런 구조를 왜 굳이 가져야 하나 싶지만 이런 구조를 가지는 이유는 다음과 같다.
만약 각 마이크로서비스가 가져야 할 기능을 하나의 서버에서 전부 담당한다면 A가 처리할 기능 A, B가 처리할 기능 B를 모두 담당하고 있을 것이다. 이때 A가 처리할 기능 A를 수정 작업하는 상황이 생겼을 때 B는 어떠한 작업도 필요하지 않지만 서비스의 빌드와 배포가 다시 일어나야 하고 그렇기에 서버의 다운타임이 생긴다. 그 반대도 역시 마찬가지. 그 결과 사용자는 좋지 않은 사용자 경험을 할 수 있다. 그렇다면 이를 작은 단위로 서비스를 분리하여 특정 기능의 수정 및 추가가 일어날 때 해당 서비스만 변경 작업을 하고 해당 서비스가 제공하는 기능을 사용하는 서버 및 게이트웨이는 변경의 진행 여부조차 알 필요 없이 서비스는 계속해서 실행 상태를 유지할 수 있다.
API Gateway는 사용자의 요청을 받아 해당 요청에 대한 라우팅, 필터링, 요청에 대한 트래픽 관리를 해준다. 요청에 대한 트래픽 관리는 부하 분산과 관련이 있는데 이는 사용자에게 받은 요청에 대한 Load Balancing 처리를 해준다. 예를 들어, 쇼핑몰 서비스의 유저 관련 기능을 제공하는 하나의 마이크로서비스가 3개의 다른 포트로 실행되어 Eureka에 등록되면 사용자가 유저 조회와 같은 유저 관련 API를 호출할 때 현재 각 3개의 마이크로서비스 중 이 요청에 응답할 수 있는 서비스를 알아서 찾아 그 서비스로부터 데이터 요청 및 응답을 받는다.