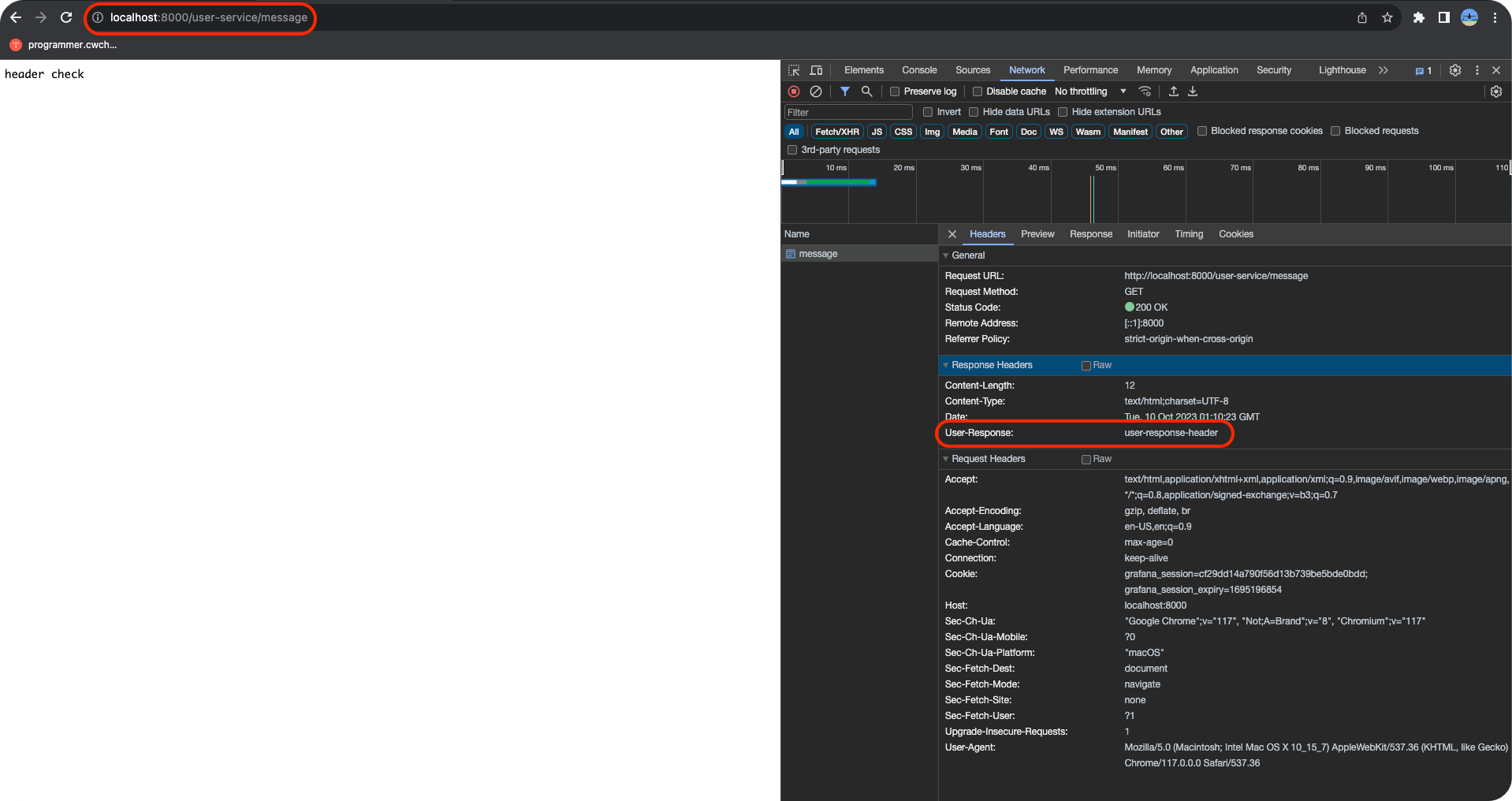
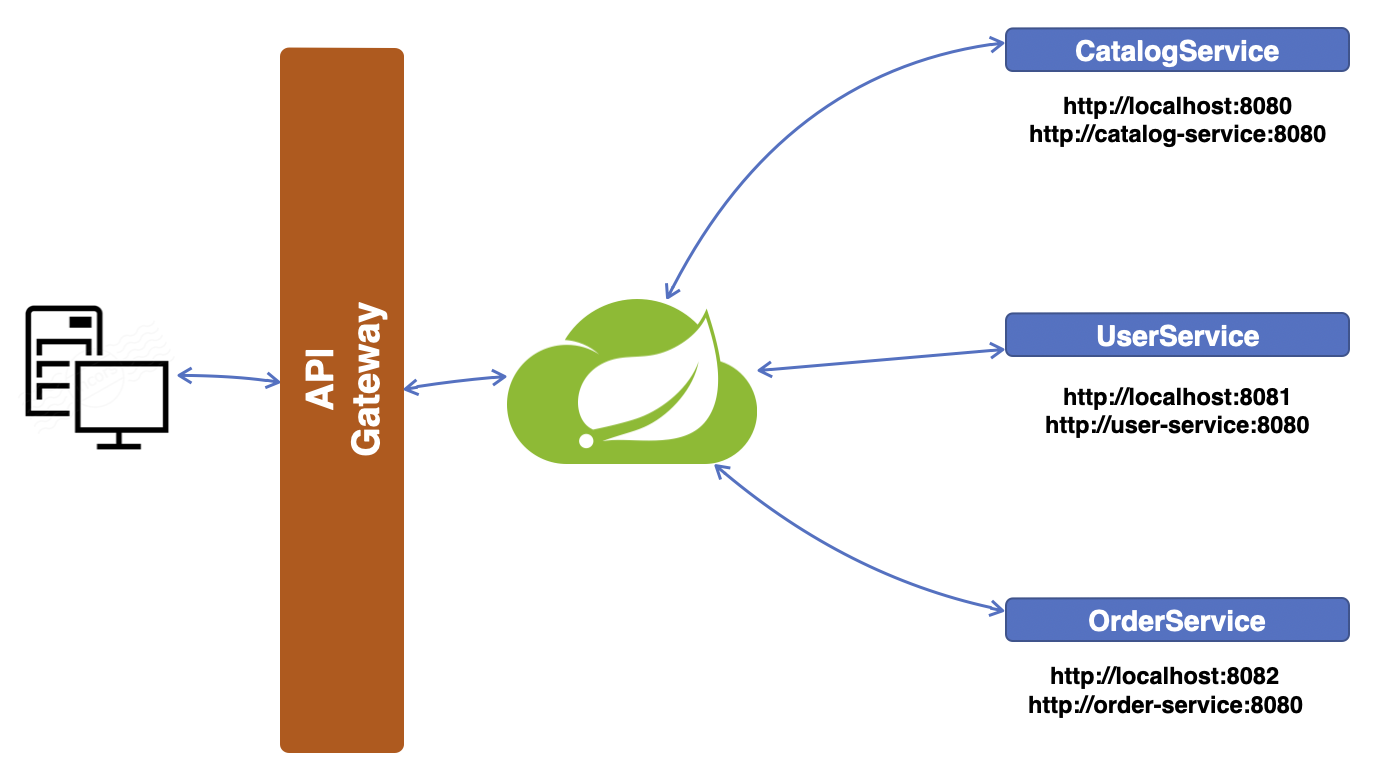
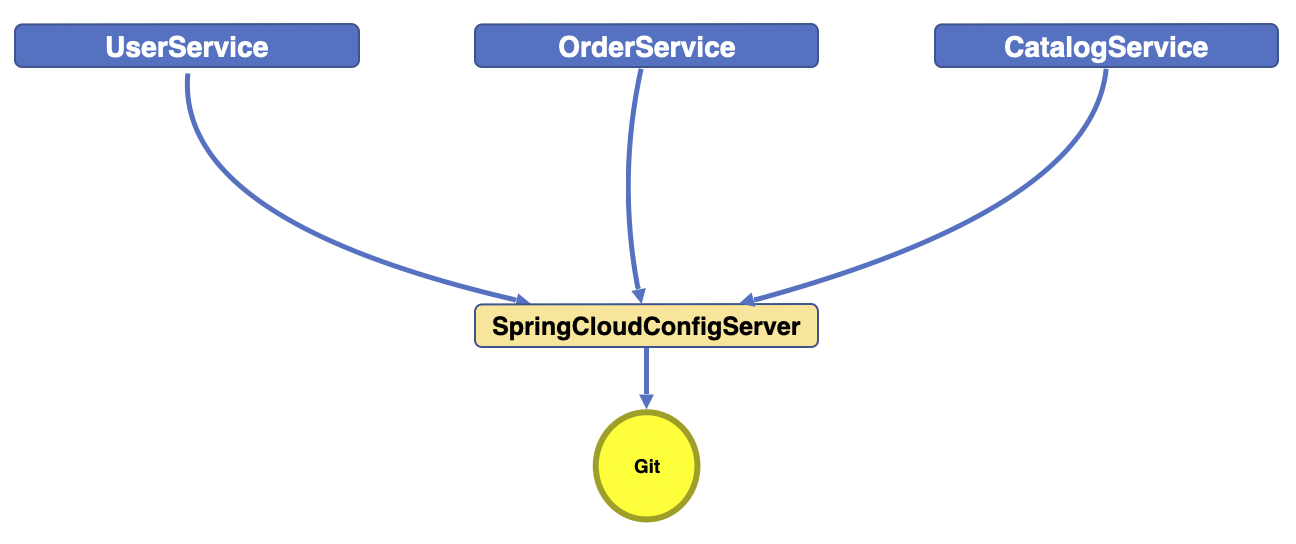
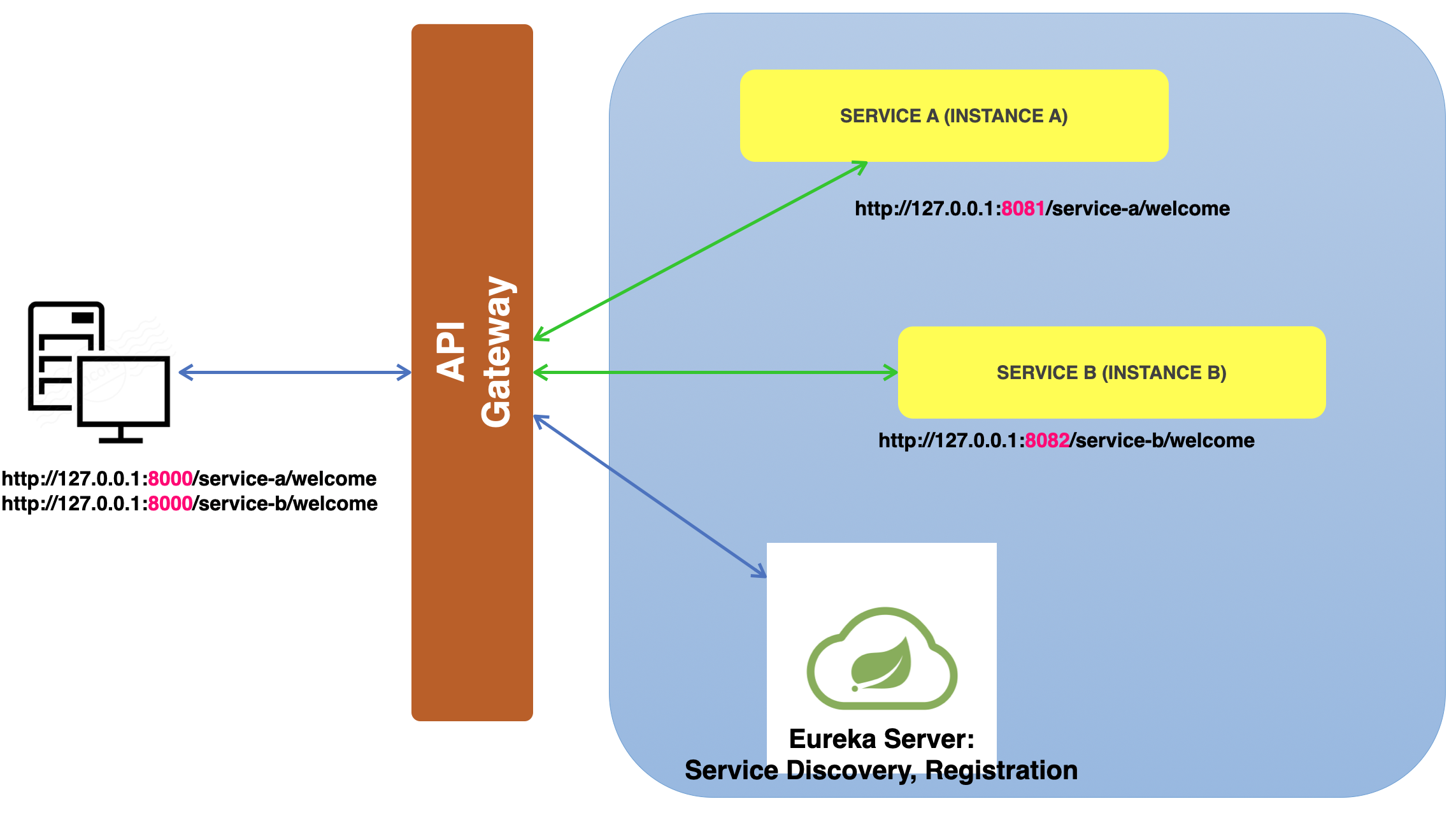
이전 Part 6 까지는 API Gateway Service는 Eureka에 등록하지 않았다. 이제 이 Gateway도 등록을 해야한다. 등록해서 Load Balancer를 사용해보자. API Gateway Service의 application.yml server: port: 8000 eureka: client: register-with-eureka: true fetch-registry: true service-url: defaultZone: http://localhost:8761/eureka spring: application: name: api-gateway-service cloud: gateway: default-filters: - name: GlobalFilter args: baseMessage:..