데이터베이스에서 빼놓을 수 없는 개념인 Index. 이 내용을 정리해보고자 한다.
우선 다음과 같이 데이터베이스에 데이터가 저장되어 있다고 가정해보자.
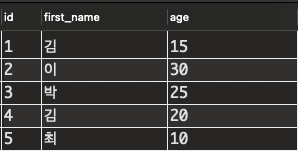
그리고 질문은 다음과 같다.
Q: age = 20인 행을 찾으려면?
간단한 쿼리를 통해 가져올 수 있다.
SELECT * FROM XXX WHERE age = 20;
이 쿼리를 날리면 컴퓨터는 age가 20인 행을 찾기위해 모든 행을 하나씩 다 뒤지게 된다. 뭐 지금처럼 레코드가 5개만 있으면 1초도 안 걸린다. 근데 1억개가 넘게 있으면 또는 그 이상 있으면 있을수록 느리게 동작할 것이다.
그러다가 어떤 특이점에 도달하게 되면 데이터베이스는 굉장히 무시무시한 일이 일어날 수 있다. 그렇기 때문에 이러한 특이점이 일어나기 전 컴퓨터에게 도움을 줄 수 있는데 그게 바로 index다.
index가 어떻게 동작하는지 쉽게 이해하기 위해 다음 그림을 보자.

1부터 100까지 숫자가 있는 카드가 있다고 치자. A와 B가 게임을 하는거다. A가 카드 한장을 뽑으면 B가 맞추는 형식이다.
이 때 B는 A한테 1이야? 2야? 3이야? 4야? ... 100이야? 이렇게 순차적으로 물어보는게 효율적일까? 물론 뽑은 카드가 1이라면 그럴 수 있겠지만 뽑은 카드가 100이라면 절대 아니다. B는 A한테 이런식으로 질문해야 더 적은 질문으로 더 빠른 해답을 찾을 수 있다.
"50보다 커?" - "75보다 작아?" 이렇게 중간지점에서 대소를 비교하는 식으로 말이다.
데이터베이스도 이런식으로 질문을 하면 더 효율적이지 않을까? 맞다. 그러나 여기서 전제조건이 있다.
순서대로 정렬이 되어 있어야 저렇게 반씩 날릴 수 있는 질문이 가능하다라는 것.
그래서, 데이터베이스에서도 저렇게 질문을 하고 싶다면 같은 컬럼을 복사해서 순서대로 정렬해 놓음이 필요하다.
그리고 이 정렬해서 복사해둔 컬럼을 index라고 부른다.

근데, 이 정렬하는 방식이 궁금하다. 정말 순서대로 저렇게 정렬해서 index를 만들까?
그렇다면 다음과 같이 그냥 Array나 Linked List로 순서대로 정렬해도 될 것 같다.

그런데 실제 데이터베이스들은 index를 만들 때 이렇게 만들지 않고 Tree 형태로 만든다. 뭐 이렇게 말이지.

즉, 모든 데이터들을 다 가져와서 일렬로 순서대로 정렬하는게 아니라, 아무렇게나 흩뿌려져 있는 데이터들을 가지고 와서 이렇게 가지치기 형식으로 정렬을 한다. 이렇게 해도 반으로 갈라낼수가 있기 때문이다. 예를 들어, 다음과 같은 질문을 받았다고 하자.
Q: 저는 5가 어디 저장되어 있는지 알고 싶어요.
1. 그럼 가장 상단에 있는 4한테 물어본다. 5는 4보다 큽니까? Yes
2. 위 질문에 Yes가 나왔으니 오른쪽으로 빠진다. 그리고 만난 6한테 물어본다. 6보다 작습니까? Yes
두 번의 질문으로 원하는 답을 찾게 된다.
결론은 데이터베이스에서 index를 만들라고 하면 트리형태로 위 그림처럼 만들어준다는 얘기다.
이를 전문용어로 Binary Search Tree라고 한다.
근데, 저기서 조금 더 개선시킬 방법이 보인다. 저 하나 하나의 카드를 Node라고 부르는데, 이 노드에 숫자 하나만을 담는게 아니라 숫자를 두 개씩 넣어버리면 데이터가 많아지면 많아질수록 더 시원하게 날려버릴 수 있지 않을까? 다음 그림처럼 말이다.
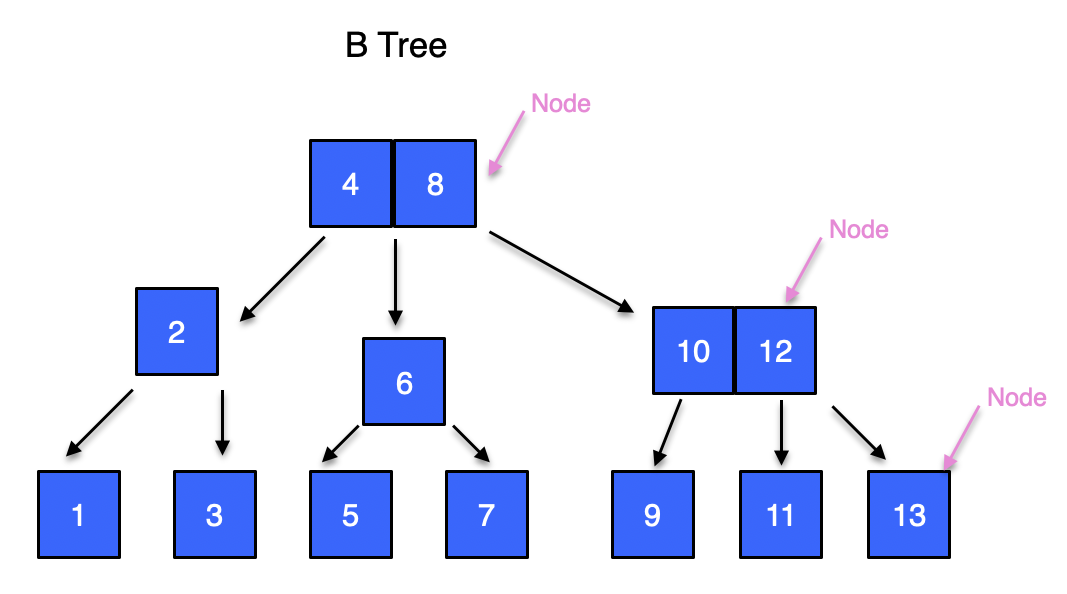
이렇게 한 노드에 여러 데이터를 넣어서 한번에 많은 양의 필요없는 데이터를 쳐낼 수 있다.
예를 들어 또 같은 질문이 들어왔다고 가정해보자.
Q: 저는 5가 어디 저장되어 있는지 알고 싶어요.
1. 4/8 이 들어있는 최상단 노드에 5보다 큰가?를 물어봤을 때 4는 No, 8은 Yes를 답하게 되니 중간 다리로 내려간다.
2. 6한테 5보다 작니?를 물어봤을 때 No를 답하니 5를 찾게 된다.
데이터가 위 사진보다 더 많아졌음에도 불구하고 똑같이 2번의 질문만으로 답을 찾아낼 수 있게 된다.
근데, 여기서 또 다른 방식이 있다. B+Tree라는 구조인데 이건 다음과 같이 생겼다.

이 구조는 데이터는 전부 가장 밑바닥에 존재하고 (여기서 가장 하단의 노드를 가리키는 말로 '리프노드'라고한다) 가이드 라인만 제공하는 형식이다. 이렇게 되더라도 여전히 같은 맥락으로 절반씩 쳐내는 게 가능하다. 똑같이 2번의 질문 만으로 데이터를 찾아낼 수 있다.
근데 이 B+Tree의 다른점은 하단에 데이터끼리도 연결을 해 둔다는 것이다.

이렇게 하단에도 연결을 해두면 뭐가 좋을까? 범위 검색이 쉬워진다. 예를 들어 4부터 8까지의 데이터를 가져오고 싶으면 연결된 선으로 4부터 8까지 쭉 가져오기만 하면 된다. 4만 찾으면 말이지. B Tree랑 비교하면 훨씬 더 우월한 검색이 가능하다. B Tree로는 범위 검색 시 가지를 왔다리 갔다리 해야한다.
정리를 하자면
age = 20인 데이터를 찾아줘!
- index가 없는 경우: 모든 행을 다 뒤져서 찾아냈을 때 돌려준다.
- index가 있는 경우: 자동으로 index 컬럼부터 보고 적은 질문으로 더 빨리 찾아낸다. 찾아낸 후 인덱스에는 원래 행을 찾을 수 있는 주소가 있는데 그 주소를 통해 찾고자 하는 데이터를 돌려준다.
그러나, index가 장점만 있지는 않다.
index를 구현하면 어떤 단점이 있나? 같은 내용을 담는 컬럼을 복사한다. 그 말은 데이터베이스의 용량을 더 사용한다는 의미이다.
즉, index가 많아지면 많아질수록 더 많은 데이터베이스의 용량을 가져다 사용한다는 뜻이다. 또 다른 단점은 만약 원래 데이터베이스에 레코드가 삽입, 수정, 삭제가 된다면? 그 레코드를 인덱스에도 똑같이 삽입, 수정, 삭제의 과정을 겪어야 한다. (근데, 요즘은 뭐 컴퓨터 성능이 너무 좋아서 사실 이런것까지 고려할 필요가 있나 싶다)
참고: PK는 index 생성이 필요없다. 왜냐하면 자동으로 정렬이 되어 있기 때문에. 그리고 이를 clustered index라고 표현한다.
'Spring + Database' 카테고리의 다른 글
| [Renewal] 예외 (0) | 2024.12.05 |
|---|---|
| [Renewal] 스프링의 트랜잭션 (0) | 2024.11.24 |
| [Renewal] 트랜잭션, DB 락 이해 (0) | 2024.11.22 |
| [Renewal] 커넥션풀과 DataSource 이해 (2) | 2024.11.21 |
| [Renewal] JDBC 이해 (2) | 2024.11.20 |