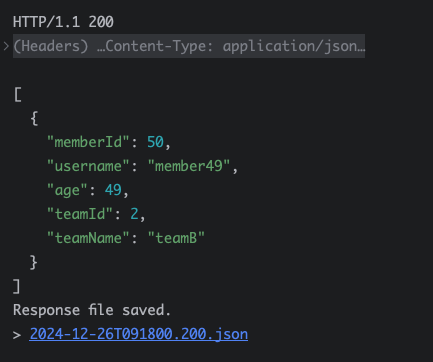
이전 포스팅에서 Querydsl 세팅하는 방법과 왜 Querydsl을 사용해야 하는지를 이야기했다. 이제 천천히 하나씩 Querydsl을 사용해보면서 이게 얼마나 막강한 녀석인지 직접 체감해보자.
우선, 엔티티를 정의해야 한다. 참고로, 나는 JPA와 Querydsl을 같이 사용한다. 그래서 JPA로 엔티티를 만들어내고 Querydsl을 곁들인다.
엔티티 정의
Member
package cwchoiit.querydsl.entity;
import jakarta.persistence.*;
import lombok.AccessLevel;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.ToString;
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@ToString(of = {"id", "username", "age"})
public class Member {
@Id
@GeneratedValue
@Column(name = "member_id")
private Long id;
private String username;
private int age;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
public Member(String username) {
this(username, 0, null);
}
public Member(String username, int age) {
this(username, age, null);
}
public Member(String username, int age, Team team) {
this.username = username;
this.age = age;
if (team != null) {
changeTeam(team);
}
}
private void changeTeam(Team team) {
this.team = team;
team.getMembers().add(this);
}
}
Team
package cwchoiit.querydsl.entity;
import jakarta.persistence.*;
import lombok.AccessLevel;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.ToString;
import java.util.ArrayList;
import java.util.List;
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@ToString
public class Team {
@Id
@GeneratedValue
@Column(name = "team_id")
private Long id;
private String name;
@OneToMany(fetch = FetchType.LAZY, mappedBy = "team")
private final List<Member> members = new ArrayList<>();
public Team(String name) {
this.name = name;
}
}
- 간단하게 Team - Member 엔티티를 만들었다.
- 당연히, 팀과 멤버는 1:N 관계이고 여기서는 다대일 양방향 연관관계로 만들었다.
Querydsl 맛보기
이제 테스트 코드로 간단한 Querydsl 코드를 작성하자.
QuerydslBasicTest
package cwchoiit.querydsl;
import com.querydsl.jpa.impl.JPAQueryFactory;
import cwchoiit.querydsl.entity.Member;
import cwchoiit.querydsl.entity.Team;
import jakarta.persistence.EntityManager;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.transaction.annotation.Transactional;
import static cwchoiit.querydsl.entity.QMember.member;
import static org.assertj.core.api.Assertions.assertThat;
@SpringBootTest
@Transactional
public class QuerydslBasicTest {
@Autowired
EntityManager em;
JPAQueryFactory queryFactory;
@BeforeEach
public void setUp() {
queryFactory = new JPAQueryFactory(em);
Team teamA = new Team("teamA");
Team teamB = new Team("teamB");
em.persist(teamA);
em.persist(teamB);
Member member1 = new Member("member1", 10, teamA);
Member member2 = new Member("member2", 20, teamA);
Member member3 = new Member("member3", 30, teamB);
Member member4 = new Member("member4", 40, teamB);
em.persist(member1);
em.persist(member2);
em.persist(member3);
em.persist(member4);
}
@Test
void querydsl() {
Member findMember = queryFactory
.select(member)
.from(member)
.where(member.username.eq("member1"))
.fetchOne();
assertThat(findMember).isNotNull();
assertThat(findMember.getUsername()).isEqualTo("member1");
assertThat(findMember.getAge()).isEqualTo(10);
}
}
- 우선, Querydsl을 사용하려면 JPAQueryFactory가 필요하다. 이 친구는 필드 레벨에 선언하는 게 가장 좋다. 어차피 멀티스레드 환경에서도 안전하게 동작하게 설계됐기 때문에 필드 레벨에 선언해도 아무런 문제도 없다.
- 그리고 여기서는 각 테스트 별로 데이터가 준비될 수 있게 @BeforeEach 애노테이션으로 테스트 데이터를 만들어 낸다.
- JPAQueryFactory는 EntityManager가 필요하다. 그래서, 생성자로 전달하는 모습을 확인할 수 있다.
- 실제로 Querydsl을 사용하는 코드를 중점적으로 봐보자.
@Test
void querydsl() {
Member findMember = queryFactory
.select(member)
.from(member)
.where(member.username.eq("member1"))
.fetchOne();
assertThat(findMember).isNotNull();
assertThat(findMember.getUsername()).isEqualTo("member1");
assertThat(findMember.getAge()).isEqualTo(10);
}
- QMember를 static-import를 하면 그 클래스 안에 필드로 선언된 `member`를 위 코드처럼 간단하고 명료하게 사용할 수 있다.
- 그리고 코드를 보면, 자바 코드인데도 불구하고 SQL처럼 보여지는 이 가시성이 정말 막강한 장점이다. 동적 쿼리를 작성할때도 정말 강력한 것이 where(...)안에 필요한 조건문을 아주 간결하게 작성할 수 있다. 이후에 저 부분은 더 멋지게 변경될 것이다.
검색 조건 쿼리
아래 코드를 보자.
@Test
void search() {
/*Member findMember = queryFactory
.selectFrom(member)
.where(member.username.eq("member1").and(member.age.eq(10)))
.fetchOne();*/
Member findMember = queryFactory
.selectFrom(member)
.where(member.username.eq("member1"), member.age.eq(10))
.fetchOne();
assertThat(findMember).isNotNull();
assertThat(findMember.getUsername()).isEqualTo("member1");
}
- 주석 처리한 것과 주석 처리하지 않은 두 쿼리가 완전히 동일한 쿼리이다. and(...) 으로 메서드 체인형식으로 사용할 수도 있고, and의 경우에는 저렇게 (,)로 연결해도 동일한 결과이다.
- 참고로, and가 있으면 당연히 or도 있다.
- 그러 뭐가 더 좋냐? 뭐 사람마다 다르겠지만, 개인적으로는 (,) 방식을 더 선호한다. 근데 이건 뭐가 됐든 상관없다.
결과 조회
@Test
void resultFetch() {
List<Member> members = queryFactory.selectFrom(member).fetch();
Member findMember = queryFactory.selectFrom(member).fetchOne();
// 아래와 동일한 코드 queryFactory.selectFrom(member).limit(1).fetchOne();
Member findMemberFirst = queryFactory.selectFrom(member).fetchFirst();
}
- fetch() → 리스트 조회, 데이터 없으면 빈 리스트 반환
- fetchOne() → 단건 조회, 결과가 없으면 null, 결과가 둘 이상이면 NonUniqueResultException 발생
- fetchFirst() → limit(1).fetchOne()과 동일한 편의 메서드
정렬
/**
* 회원 정렬
* 회원 나이 내림차순
* 회원 이름 올림차순
* 단 2에서 회원 이름이 null 이면 마지막에 출력
*/
@Test
void sort() {
Member memberNull = new Member(null, 100);
Member member5 = new Member("member5", 100);
Member member6 = new Member("member6", 100);
em.persist(memberNull);
em.persist(member5);
em.persist(member6);
List<Member> members = queryFactory
.selectFrom(member)
.where(member.age.eq(100))
.orderBy(member.age.desc(), member.username.asc().nullsLast())
.fetch();
assertThat(members).isNotNull();
assertThat(members.getFirst().getUsername()).isEqualTo("member5");
assertThat(members.get(1).getUsername()).isEqualTo("member6");
assertThat(members.get(2).getUsername()).isNull();
}
- 정렬도 Querydsl을 사용하면 여려 정렬을 한번에 할 수 있으며, 해당값이 null인 경우, 마지막에 위치시킬지 맨 처음에 위치시킬지를 정할 수 있다.
- 마지막에 위치시키는 건 nullsLast(), 맨 처음에 위치시키는 건 nullsFirst()를 사용하면 된다.
- 여기서는 nullsLast()를 사용했다.
페이징
@Test
void paging1() {
List<Member> members = queryFactory
.selectFrom(member)
.orderBy(member.username.desc())
.offset(1)
.limit(2)
.fetch();
assertThat(members).isNotNull();
assertThat(members.size()).isEqualTo(2);
assertThat(members.getFirst().getUsername()).isEqualTo("member3");
assertThat(members.get(1).getUsername()).isEqualTo("member2");
}
@Test
void paging2() {
List<Member> members = queryFactory
.selectFrom(member)
.orderBy(member.username.desc())
.offset(1)
.limit(2)
.fetch();
int totalCount = queryFactory
.selectFrom(member)
.fetch()
.size();
assertThat(members).isNotNull();
assertThat(totalCount).isEqualTo(4);
assertThat(members.size()).isEqualTo(2);
assertThat(members.getFirst().getUsername()).isEqualTo("member3");
assertThat(members.get(1).getUsername()).isEqualTo("member2");
}
- 페이징은 간단하게, offset(), limit()을 사용하면 된다.
- 그리고 전체 수를 가져오는 건 별도의 쿼리로 작성해줘야 한다. 예전에는 fetchResults()라는 것을 사용해서 전체 개수를 가져올 수 있었는데 그 메서드는 Deprecated 됐고, 애시당초에 그 메서드도 내부에서 전체 카운트를 가져오는 쿼리를 또 날리는 것 밖에 안된다.
- 그래서 전체 개수를 가져오는 쿼리는 별도로 작성해서 위 paging2()처럼 가져온다. 보면 알겠지만, 전체 개수를 가져오는 쿼리는 굉장히 간단하고 실제 쿼리랑은 다르다. 지금이야 orderBy() 정도만 있고 없고의 차이지만 어떤것은 그 이상으로 전체 개수를 가져오는 쿼리가 최적화되기 때문에 이 부분은 직접 구현하도록 바뀌었다.
집합
집합 함수를 의미하고, SUM, COUNT, AVG, MAX, MIN, GROUP BY를 사용한다.
@Test
void aggregation() {
List<Tuple> results = queryFactory
.select(
member.count(),
member.age.sum(),
member.age.avg(),
member.age.min(),
member.age.max()
)
.from(member)
.fetch();
Tuple tuple = results.getFirst();
assertThat(tuple.get(member.count())).isEqualTo(4);
assertThat(tuple.get(member.age.sum())).isEqualTo(100);
assertThat(tuple.get(member.age.avg())).isEqualTo(25);
assertThat(tuple.get(member.age.min())).isEqualTo(10);
assertThat(tuple.get(member.age.max())).isEqualTo(40);
}
- COUNT, SUM, AVG, MIN, MAX도 굉장히 간단하게 그저 메서드를 호출하는 것으로 구현해낼 수 있다.
- 그리고 타입이 가지각색이거나, 어떤 값으로 딱 추출을 해내는 경우엔 객체 타입이 아니라 Tuple 이라는 타입으로 반환받게 되는데 이 Tuple을 통해 값을 가져오는 건 그냥 get(...)으로 내가 원하는 값을 뽑아오면 된다.
- 참고로, 실무에서는 Tuple 타입으로 받아오는 것보다 DTO로 변환해서 가져오는 방법이 훨씬 더 많이 사용된다. 이후에 같이 알아보자.
GROUP BY도 간단하게 사용할 수 있다. 아래 코드를 보자.
/**
* 팀의 이름과 각 팀의 평균 연령을 구해라.
*/
@Test
void group() {
List<Tuple> results = queryFactory
.select(team.name, member.age.avg())
.from(member)
.join(member.team, team)
.groupBy(team.name)
.fetch();
Tuple teamA = results.getFirst();
Tuple teamB = results.get(1);
assertThat(teamA.get(team.name)).isEqualTo("teamA");
assertThat(teamA.get(member.age.avg())).isEqualTo(15);
assertThat(teamB.get(team.name)).isEqualTo("teamB");
assertThat(teamB.get(member.age.avg())).isEqualTo(35);
}
/**
* 팀의 이름과 각 팀의 평균 연령을 구하고 팀의 이름이 teamA 인것만 가져와라.
*/
@Test
void groupByHaving() {
List<Tuple> results = queryFactory
.select(team.name, member.age.avg())
.from(member)
.join(member.team, team)
.groupBy(team.name)
.having(team.name.eq("teamA"))
.fetch();
Tuple teamA = results.getFirst();
assertThat(results.size()).isEqualTo(1);
assertThat(teamA.get(team.name)).isEqualTo("teamA");
assertThat(teamA.get(member.age.avg())).isEqualTo(15);
}
- GROUP BY, HAVING을 사용한 코드이다. 참고로 HAVING은 GROUP BY로 그룹화 된 결과를 제한하는 것이다.
조인
INNER
@Test
void join() {
List<Member> members = queryFactory
.selectFrom(member)
.join(member.team, team)
.where(team.name.eq("teamA"))
.fetch();
assertThat(members).isNotNull();
assertThat(members.size()).isEqualTo(2);
assertThat(members)
.extracting(Member::getUsername)
.containsExactly("member1", "member2");
}
- 가장 기본이 되는 조인인 INNER 조인하는 방법이다. ON절은 어디있나요?에 대한 대답은 기본으로 ON절을 넣어준다. 이 테스트 코드를 실행했을 때 나가는 쿼리를 보면 바로 이해가 될 것이다.
- 아 그리고 innerJoin() 메서드도 있는데 이게 join()과 동일하다.
2024-12-22T13:19:06.677+09:00 DEBUG 58042 --- [ Test worker] org.hibernate.SQL :
select
m1_0.member_id,
m1_0.age,
m1_0.team_id,
m1_0.username
from
member m1_0
join
team t1_0
on t1_0.team_id=m1_0.team_id
where
t1_0.name=?
[LEFT|RIGHT] OUTER
@Test
void join() {
List<Member> members = queryFactory
.selectFrom(member)
.leftJoin(member.team, team)
.where(team.name.eq("teamA"))
.fetch();
/*List<Member> members = queryFactory
.selectFrom(member)
.rightJoin(member.team, team)
.where(team.name.eq("teamA"))
.fetch();*/
assertThat(members).isNotNull();
assertThat(members.size()).isEqualTo(2);
assertThat(members)
.extracting(Member::getUsername)
.containsExactly("member1", "member2");
}
- 외부 조인 역시 가능하다. leftJoin(), rightJoin()이 있다.
THETA
"막 조인"이라고 하는 세타 조인도 역시 가능하다.
/**
* 회원이 이름이 팀 이름과 같은 회원 조회
*/
@Test
void thetaJoin() {
em.persist(new Member("teamA"));
em.persist(new Member("teamB"));
em.persist(new Member("teamC"));
List<Member> members = queryFactory
.select(member)
.from(member, team)
.where(member.username.eq(team.name))
.fetch();
assertThat(members).isNotNull();
assertThat(members.size()).isEqualTo(2);
assertThat(members).extracting(Member::getUsername).containsExactly("teamA", "teamB");
}
- 억지스러운 예제이긴 하지만, 회원의 이름이 "teamA", "teamB", "teamC"라고 만들고 이 회원 이름과 팀 이름이 같은 회원들을 한번 조회해보고 싶은것이다. 원래 세타 조인이 이렇게 막 조인이다.
- 세타 조인을 할땐 FROM절에 원하는 �엔티티를 여러개 넣으면 된다.
ON절
ON절을 활용한 조인은 다음 두가지 케이스에서 사용된다.
- 조인 대상 필터링
- 연관관계 없는 엔티티의 외부 조인
조인 대상 필터링
지금까지 join()을 사용하면서 on()을 사용하지 않으면 그냥 기본으로 조인 대상의 ID가 같은 것들을 넣어주곤 했다.
이 경우에 더해서, 조인 대상을 필터링하고 싶을 때 추가적으로 ON절을 사용할 수가 있다.
/**
* 회원과 팀을 조인하면서, 팀 이름이 teamA인 팀만 조인, 회원은 모두 조회
*/
@Test
void on_filtering() {
List<Tuple> results = queryFactory
.select(member, team)
.from(member)
.leftJoin(member.team, team)
.on(team.name.eq("teamA"))
.fetch();
for (Tuple result : results) {
System.out.println("result = " + result);
}
}
- 위 코드처럼 LEFT JOIN을 한다고 가정해보자. LEFT JOIN은 왼쪽 엔티티를 기준으로 오른쪽에 조인 대상이 없어도 결과로 출력이 된다. 그런데 그 조인 대상을 필터링을 하고 싶은 것이다. MEMBER.TEAM.ID = TEAM.ID 뿐 아니라, TEAM의 이름이 "teamA"인 애들만 조인하고 싶은 것이다.
- 이렇게 되면 결과는 어떻게 될까? TEAM의 이름이 "teamA"인 녀석들은 조인 결과에서 팀까지 같이 출력이 되고, "teamA"가 아닌 녀석들은 조인 결과에서 팀은 빠지고 멤버만 남을 것이다. LEFT JOIN이니까.
실행 결과
result = [Member(id=1, username=member1, age=10), Team(id=1, name=teamA, members=[Member(id=1, username=member1, age=10), Member(id=2, username=member2, age=20)])]
result = [Member(id=2, username=member2, age=20), Team(id=1, name=teamA, members=[Member(id=1, username=member1, age=10), Member(id=2, username=member2, age=20)])]
result = [Member(id=3, username=member3, age=30), null]
result = [Member(id=4, username=member4, age=40), null]
나가는 쿼리
2024-12-22T13:36:36.154+09:00 DEBUG 58927 --- [ Test worker] org.hibernate.SQL :
select
m1_0.member_id,
m1_0.age,
m1_0.team_id,
m1_0.username,
t1_0.team_id,
t1_0.name
from
member m1_0
left join
team t1_0
on t1_0.team_id=m1_0.team_id
and t1_0.name=?
그런데 만약, 외부 조인이 아니라 내부 조인을 사용하면 ON절을 사용하는 것 말고 WHERE를 사용해도 완전히 동일한 결과를 얻을 것이다. 왜냐하면, 내부 조인은 애시당초에 조인 결과에서 대상이 없는 녀석들은 제외시키기 때문에 조인 대상이 있는 녀석들만 결과로 출력될 것이고 거기서 팀 이름이 "teamA"인 녀석들만 간추리려면 그냥 WHERE절 사용하면 된다. 그러니까, 내부 조인인데 굳이 ON절로 안 익숙한 것을 사용하지 말고 내부조인인 경우에는 WHERE가 더 익숙하니 이걸 사용하면 좋다는 말이다.
연관관계 없는 엔티티 외부 조인
/**
* 연관 관계가 없는 엔티티 외부 조인
* 회원의 이름이 팀 이름과 같은 대상 외부 조인
*/
@Test
void thetaJoin_on() {
em.persist(new Member("teamA"));
em.persist(new Member("teamB"));
em.persist(new Member("teamC"));
List<Tuple> results = queryFactory
.select(member, team)
.from(member)
.leftJoin(team)
.on(member.username.eq(team.name))
.fetch();
for (Tuple result : results) {
System.out.println("result = " + result);
}
}
- 세타 조인은 아닌데, 외부 조인을 하고 싶은데 외부 조인을 할 때 연관관계가 없는 엔티티와 외부 조인을 하려고 할 때 이 ON을 사용할수가 있다.
- 위 코드를 보면, 지금 leftJoin()을 사용하는데 매우 주의 깊게 봐야한다! 원래는 leftJoin(member.team, team)이렇게 사용하곤 했는데 여기서는 leftJoin(team)을 사용한다. 즉, FROM절의 member와 아무런 연관이 없는 그냥 팀을 다 가져오는데 조인 조건으로 ON을 사용해서 회원이 이름이 팀의 이름과 동일한 조건을 부여했다.
- 세타 조인을 할 땐 FROM절에 세타 조인하고 싶은 엔티티들을 여러개 넣었는데 이건 그게 아니다. 즉, 외부 조인인데 연관관계가 없는 녀석들과 외부 조인을 하려고 하는 것이다.
실행 결과
result = [Member(id=1, username=member1, age=10), null]
result = [Member(id=2, username=member2, age=20), null]
result = [Member(id=3, username=member3, age=30), null]
result = [Member(id=4, username=member4, age=40), null]
result = [Member(id=5, username=teamA, age=0), Team(id=1, name=teamA, members=[Member(id=1, username=member1, age=10), Member(id=2, username=member2, age=20)])]
result = [Member(id=6, username=teamB, age=0), Team(id=2, name=teamB, members=[Member(id=3, username=member3, age=30), Member(id=4, username=member4, age=40)])]
result = [Member(id=7, username=teamC, age=0), null]
- 외부 조인이니까 조인 대상이 없어도 결과로 출력된다. 단지, 조인 대상이 없는 것들은 null로 표시될 뿐.
나가는 쿼리
2024-12-22T13:58:35.827+09:00 DEBUG 60017 --- [ Test worker] org.hibernate.SQL :
select
m1_0.member_id,
m1_0.age,
m1_0.team_id,
m1_0.username,
t1_0.team_id,
t1_0.name
from
member m1_0
left join
team t1_0
on m1_0.username=t1_0.name
- ON절에 외래키와 PK가 같은 것들을 고려하지 않고 있다. 외부 조인인데 연관관계가 없음을 의미한다.
- 세타 조인은 FROM절에 여러개가 들어가는 것이다.
- 물론 외부 조인 말고 내부 조인도 가능하다. 근데 내부조인은 조인 대상이 없으면 결과로 나오지 않기 때문에 그냥 세타 조인을 사용하고 WHERE로 필터링한 결과랑 동일하니까 그 방법을 사용하면 된다.
페치 조인
페치 조인은 SQL에서 제공하는 기능이 아니고, SQL 조인을 활용하고 연관된 엔티티를 SQL 한번에 조회하는 기능이다. JPA에서 제공하는 기능으로써 주로 성능 최적화에 사용하는 방법이다.
@Test
void fetchJoin() {
Member findMember = queryFactory
.selectFrom(member)
.join(member.team, team)
.fetchJoin()
.where(member.username.eq("member1"))
.fetchOne();
assertThat(findMember).isNotNull();
assertThat(findMember.getUsername()).isEqualTo("member1");
assertThat(findMember.getTeam().getName()).isEqualTo("teamA");
}
- Querydsl을 사용해서 페치 조인을 하는 방법은 너무나 간단하다. join() 이후에 fetchJoin()만 붙여주면 끝난다.
- leftJoin()이든 뭐든 상관없다.
서브 쿼리
당연하게도 서브 쿼리 역시 지원한다. 하나씩 천천히 보자. QueryDsl을 사용할때 서브 쿼리를 사용하려면 com.querydsl.jpa.JPAExpressions를 사용해야 한다.
/**
* SubQuery - 나이가 가장 많은 회원 조회 (EQ)
*/
@Test
void subQuery() {
QMember memberSub = new QMember("memberSub");
List<Member> members = queryFactory
.selectFrom(member)
.where(member.age.eq(
JPAExpressions
.select(memberSub.age.max())
.from(memberSub)
))
.fetch();
assertThat(members).extracting(Member::getAge).containsExactly(40);
}
- WHERE절에 서브쿼리를 사용한 모습이다. 쿼리 자체는 뭐 별게 없는데 이렇게 사용하면 된다는 것을 보여주기 위해 작성했다.
- 당연하지만, 서브 쿼리에서 엔티티에 대한 Alias는 다른 녀석을 사용해야 한다. SQL과 똑같이 생각하면 된다. 그래서 이 경우에는 Q타입 객체를 새로 생성해야만 한다.
- 참고로, 저 JPAExpressions도 static-import를 하면 좀 더 깔끔하다. 아래와 같이 말이다.
/**
* SubQuery - 나이가 동일한 회원 (EQ)
*/
@Test
void subQuery() {
QMember memberSub = new QMember("memberSub");
List<Member> members = queryFactory
.selectFrom(member)
.where(member.age.eq(
select(memberSub.age.max())
.from(memberSub)
))
.fetch();
assertThat(members).extracting(Member::getAge).containsExactly(40);
}
EQ말고, GOE, IN과 SELECT절에서도 사용하는 예제들도 있다.
/**
* SubQuery - 나이가 평균 이상인 회원 (GOE)
*/
@Test
void suqQuery2() {
QMember memberSub = new QMember("memberSub");
List<Member> members = queryFactory
.selectFrom(member)
.where(member.age.goe(
select(memberSub.age.avg())
.from(memberSub)
))
.fetch();
assertThat(members).extracting(Member::getAge).containsExactly(30, 40);
}
/**
* SubQuery - IN절 사용
*/
@Test
void subQuery3() {
QMember memberSub = new QMember("memberSub");
List<Member> members = queryFactory
.selectFrom(member)
.where(member.age.in(
select(memberSub.age)
.from(memberSub)
.where(memberSub.age.gt(10))
))
.fetch();
assertThat(members).extracting(Member::getAge).containsExactly(20, 30, 40);
}
/**
* SubQuery - SELECT절
*/
@Test
void subQuery4() {
QMember memberSub = new QMember("memberSub");
List<Tuple> results = queryFactory
.select(
member.username,
select(memberSub.age.avg())
.from(memberSub))
.from(member)
.fetch();
for (Tuple result : results) {
System.out.println("result = " + result);
}
}
FROM절에서 서브쿼리는 불가능하다. 이유는 JPQL이 FROM절의 서브쿼리를 지원하지 않기 때문. 그리고 사실 FROM 절의 서브쿼리를 꼭 사용해야 할 필요가 없다. 거의 대부분은 JOIN으로 해결이 가능하다. 물론 모든게 다 가능하지는 않다. 그러나 간과하면 안될 것이 있다. 이게 데이터베이스에서 데이터를 가져오는 건 정말 데이터를 가져오는 것이지 데이터를 정제하고 분리하는 건 데이터베이스 레벨에서만 해야하는 게 아니다. 애플리케이션 레벨에서 충분히 가능하다. 만약 애플리케이션 레벨에서 죽어도 하기 싫다면 그냥 네이티브쿼리를 날리면 된다.
Case 문
@Test
void basicCase() {
List<String> results = queryFactory
.select(member.age
.when(10).then("열살")
.when(20).then("스무살")
.otherwise("기타")
)
.from(member)
.fetch();
for (String result : results) {
System.out.println("result = " + result);
}
}
@Test
void complexCase() {
List<String> results = queryFactory
.select(new CaseBuilder()
.when(member.age.between(0, 20)).then("0-20살")
.when(member.age.between(21, 30)).then("21-30살")
.otherwise("기타")
)
.from(member)
.fetch();
for (String result : results) {
System.out.println("result = " + result);
}
}
- 아주 단순한 경우에는 그냥 바로 when().then()을 사용하면 된다. 그러나 조금 더 복잡한 경우에는 CaseBuilder()를 사용할 수도 있다.
나는 개인적으로 Case문을 좋아하지 않는다. 가끔 효율적일 때가 있겠지만, 100% 데이터를 퍼올려서 애플리케이션 레벨에서 이 과정을 대체할 수 있기 때문이다. 데이터베이스에서 굳이 이 계산을 할 필요가 없다고 생각한다.
상수, 문자 더하기
이 경우는 꽤나 자주 사용된다.
@Test
void constant() {
List<Tuple> results = queryFactory
.select(member.username, Expressions.constant("A"))
.from(member)
.fetch();
for (Tuple result : results) {
System.out.println("result = " + result);
}
}
@Test
void concat() {
// {username}_{age}
List<String> results = queryFactory
.select(member.username.concat("_").concat(member.age.stringValue()))
.from(member)
.where(member.username.eq("member1"))
.fetch();
for (String result : results) {
System.out.println("result = " + result);
}
}
- 상수가 필요하면, Expressions.constant("xxx") 이와 같이 사용하면 된다.
- 그러면, SELECT절에 동일한 상수를 넣어서 다음과 같이 결과가 출력된다.
result = [member1, A]
result = [member2, A]
result = [member3, A]
result = [member4, A]
- 이제 문자를 더하는 경우도 있는데, 같은 문자면 상관이 없는데 만약 문자와 숫자라면 자바는 타입에 매우 민감한 언어이기 때문에 단순히 더하는걸로 안되고 위 코드처럼 stringValue()로 형변환을 해줘야 한다.
result = member1_10