참고자료
스프링 핵심 원리 - 고급편 강의 | 김영한 - 인프런
김영한 | 스프링의 핵심 원리와 고급 기술들을 깊이있게 학습하고, 스프링을 자신있게 사용할 수 있습니다., 핵심 디자인 패턴, 쓰레드 로컬, 스프링 AOP스프링의 3가지 핵심 고급 개념 이해하기
www.inflearn.com
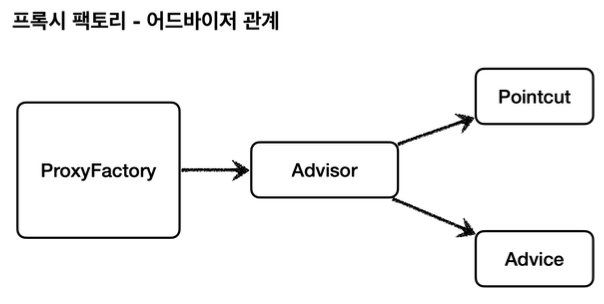
Advisor, Advice, Pointcut - 소개
- Advice: 프록시가 제공하는 추가 기능에 대한 로직을 가지고 있는 곳을 말한다. (조언)
- Pointcut: 프록시가 제공하는 추가 기능을 어디에 적용할것인가?을 가지고 있는 곳을 말한다. (어디에?)
- Advisor: Advice와 Pointcut을 한 개씩 가지고 있는 곳을 말한다. (조언자)
그리고 ProxyFactory는 Advisor가 필수이다. 근데 저번 포스팅에서는 Advisor를 안 사용했고 addAdvice()만 호출해서 Advice만 넘겼는데 이렇게 하면 기본 Advisor에 모든 곳에 적용하는 Pointcut으로 할당된다. 단순 편의 메서드인 것 뿐이다.
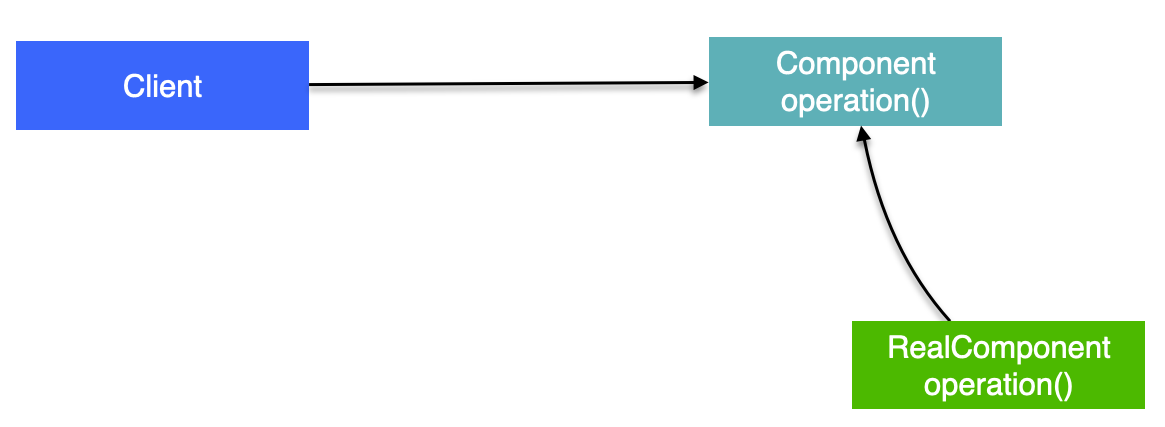
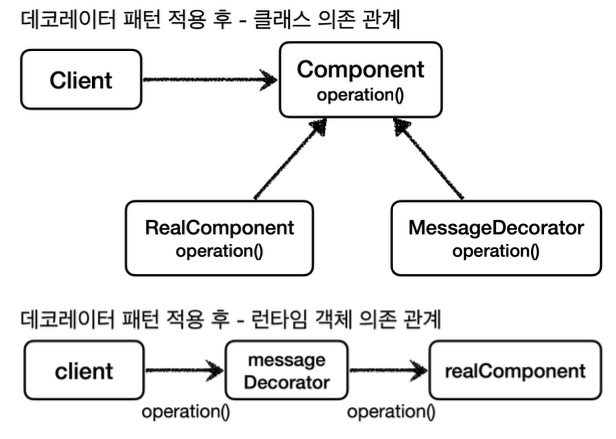
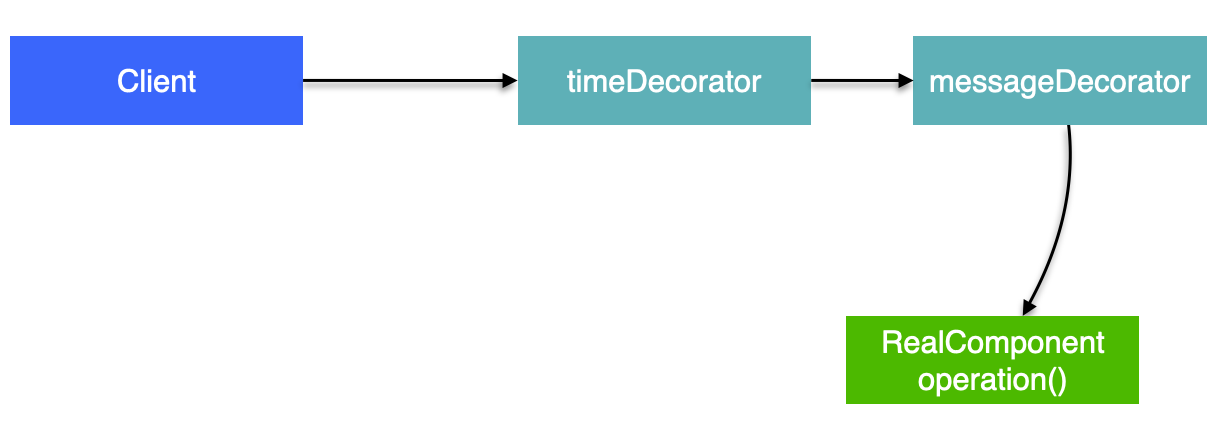
역할과 책임
이렇게 구분한 것은 역할과 책임을 명확하게 분리한 것이다.
- 포인트컷은 대상 여부를 확인하는 필터 역할만 담당한다.
- 어드바이스는 깔끔하게 부가 기능 로직만 담당한다.
- 둘을 합치면 어드바이저가 된다. 스프링의 어드바이저는 하나의 포인트컷 + 하나의 어드바이스로 구성된다.

- 위 그림은 이해를 돕기 위해 만들어진 그림이다. 실제 구현은 약간 다를 수 있지만, 흐름은 동일하다.
- 클라이언트가 프록시를 호출하면, 이 프록시는 먼저 Advice 적용 여부를 확인한다. 만약 적용되지 않았다면 부가 기능을 적용하지 않은 채로 실제 객체만 호출하고, 적용 대상이라면 부가 기능을 적용한다.
한번 Advisor, Advice, Pointcut을 적용해 보는 코드를 작성해보자.
예제 코드1 - 어드바이저
AdvisorTest
package cwchoiit.springadvanced.proxy.advisor;
import cwchoiit.springadvanced.proxy.common.advice.TimeAdvice;
import cwchoiit.springadvanced.proxy.common.service.ServiceImpl;
import cwchoiit.springadvanced.proxy.common.service.ServiceInterface;
import org.junit.jupiter.api.Test;
import org.springframework.aop.Pointcut;
import org.springframework.aop.framework.ProxyFactory;
import org.springframework.aop.support.DefaultPointcutAdvisor;
public class AdvisorTest {
@Test
void advisorTest1() {
ServiceInterface target = new ServiceImpl();
ProxyFactory proxyFactory = new ProxyFactory(target);
DefaultPointcutAdvisor advisor = new DefaultPointcutAdvisor(Pointcut.TRUE, new TimeAdvice());
proxyFactory.addAdvisor(advisor);
ServiceInterface proxy = (ServiceInterface) proxyFactory.getProxy();
proxy.save();
proxy.find();
}
}- 이전 포스팅에서 사용했던 ServiceInterface와 TimeAdvice를 그대로 사용해보자. 그리고 이제 어드바이저를 만들어보자. 그 코드는 다음과 같다.
DefaultPointcutAdvisor advisor = new DefaultPointcutAdvisor(Pointcut.TRUE, new TimeAdvice());- Advisor 인터페이스의 가장 일반적인 구현체이다. 생성자를 통해 하나의 포인트컷과 하나의 어드바이스를 넣어주면 된다. 어드바이저는 하나의 포인트컷과 하나의 어드바이스로 구성된다.
- Pointcut.TRUE는 항상 true를 반환하는 포인트컷이다. 즉, 모든곳에 프록시의 부가 기능이 적용이 된다는 의미이다.
proxyFactory.addAdvisor(advisor);- 프록시팩토리에 적용할 어드바이저를 지정한다. 어드바이저는 내부에 포인트컷과 어드바이스를 모두 가지고 있다. 따라서 어디에 부가 기능을 적용해야 할지 어드바이저 하나로 알 수 있다. 프록시 팩토리를 사용할 때 어드바이저는 필수이다.
실행 결과
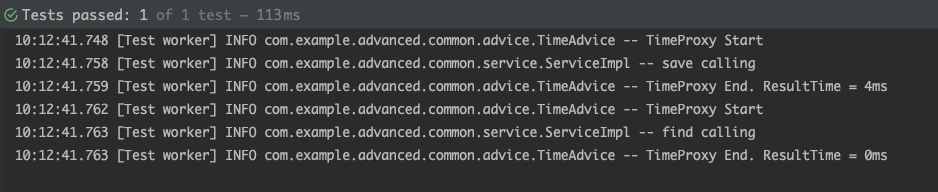
- 실행 결과를 보면, save(), find() 각각 모두 어드바이스가 적용된 것을 확인할 수 있다.
예제 코드2 - 직접 만든 포인트컷
이번에는, save() 메서드에는 어드바이스 로직을 적용하지만, find() 메서드에는 어드바이스 로직을 적용하지 않도록 해보자. 물론 과거에 했던 코드와 유사하게 어드바이스에 로직을 추가해서 메서드 이름을 보고 코드를 실행할지 말지 분기를 타도 된다. 하지만 이런 기능에 특화되어서 제공되는 것이 바로 포인트컷이다. 그리고 그렇게하면 어드바이스의 역할과 책임이 너무 많아진다(=유지보수가 안 좋아진다)
Pointcut 관련 인터페이스 - 스프링 제공
public interface Pointcut {
ClassFilter getClassFilter();
MethodMatcher getMethodMatcher();
}
public interface ClassFilter {
boolean matches(Class<?> clazz);
}
public interface MethodMatcher {
boolean matches(Method method, Class<?> targetClass);
//..
}- 포인트컷은 크게 ClassFilter, MethodMatcher 둘로 이루어진다. 이름 그대로 하나는 클래스가 맞는지, 하나는 메서드가 맞는지 확인할 때 사용한다. 둘 다 true로 반환해야 어드바이스를 적용할 수 있다.
- 일반적으로 스프링이 이미 만들어둔 구현체를 사용하지만, 학습 차원에서 한번 간단히 직접 구현해보자.
@Test
@DisplayName("직접 만든 포인트컷")
void advisorTest2() {
ServiceInterface target = new ServiceImpl();
ProxyFactory proxyFactory = new ProxyFactory(target);
DefaultPointcutAdvisor advisor = new DefaultPointcutAdvisor(new MyPointcut(), new TimeAdvice());
proxyFactory.addAdvisor(advisor);
ServiceInterface proxy = (ServiceInterface) proxyFactory.getProxy();
proxy.save();
proxy.find();
}
/**
* 직접 만들일은 없음, 스프링이 만들어주는 Pointcut을 사용하면 되지만 한번 만들어보자.
* 클래스와 메서드 둘 다 'true' 를 리턴해야만 Pointcut에 적합한 요청이라고 판단하여 Advice를 적용한다.
* */
static class MyPointcut implements Pointcut {
/**
* 클래스를 기준으로 필터링
* ClassFilter.TRUE 를 반환하면 모든 클래스에 대해 Advice 적용을 허용
* */
@Override
public ClassFilter getClassFilter() {
return ClassFilter.TRUE;
}
/**
* 메서드를 기준으로 필터링
* MethodMatcher를 구현해야 한다.
* */
@Override
public MethodMatcher getMethodMatcher() {
return new MyMethodMatcher();
}
}
static class MyMethodMatcher implements MethodMatcher {
private String matchName = "save";
@Override
public boolean matches(Method method, Class<?> targetClass) {
boolean result = method.getName().equals(matchName);
log.info("포인트컷 호출 method = {} targetClass= {}", method.getName(), targetClass);
log.info("포인트컷 결과 result = {}", result);
return result;
}
@Override
public boolean isRuntime() {
return false;
}
@Override
public boolean matches(Method method, Class<?> targetClass, Object... args) {
return false;
}
}
MyPointcut
- 직접 구현한 포인트컷이다. Pointcut 인터페이스를 구현한다.
- 현재 메서드 기준으로 로직을 적용하면 된다. 클래스 필터는 항상 true를 반환하도록 했고, 메서드 비교 기능은 MyMethodMatcher를 사용한다.
MyMethodMatcher
- 직접 구현한 MethodMatcher이다. MethodMatcher 인터페이스를 구현한다.
- matches() → 이 메서드에 method, targetClass 정보가 넘어온다. 이 정보로 어드바이스를 적용할지 적용하지 않을지 판단할 수 있다. 여기서는 메서드 이름이 'save'인 경우에 true를 반환하도록 판단 로직을 적용한다.
- isRuntime(), matches(..., args) → isRuntime() 이 값이 true이면 matches(..., args) 메서드가 matches() 대신 호출된다. 동적으로 넘어오는 매개변수를 판단 로직으로 사용할 수 있다. isRuntime()이 false인 경우, 클래스의 정적 정보만 사용하기 때문에 스프링이 내부에서 캐싱을 통해 성능 향상이 가능하지만, isRuntime()이 true인 경우 매개변수가 동적으로 변경된다고 가정하기 때문에 캐싱을 하지 않는다. 크게 중요한 부분은 아니니 참고만 하자. 어차피 포인트컷을 직접 만들일은 없다.
위에서 모든 대상에 대해 Advice를 적용했던 예시 코드에 비교해서 바뀌는 부분은 딱 Pointcut이 달라지는것 말고 없다. 우리가 만든 MyPointcut을 전달한다. 대신 실행 결과가 달라질 것이다. 'save()'가 아닌 'find()'에는 Advice는 적용되지 않는다.
실행 결과

위 실행 결과의 흐름을 그림으로 비교해보자.
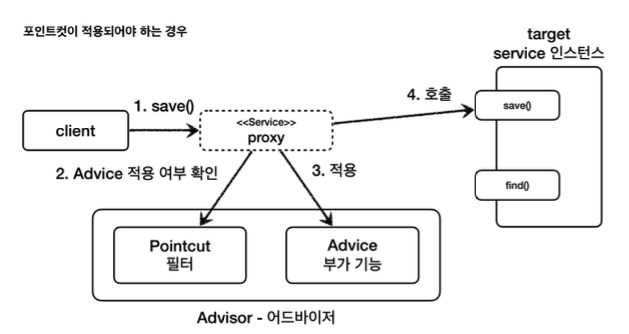
- 클라이언트가 프록시의 save()를 호출한다.
- 포인트컷에게 Service 클래스의 save() 메서드에 어드바이스를 적용해도 될지 물어본다.
- 포인트컷이 true를 반환한다. 따라서 어드바이스를 호출해서 부가 기능을 적용한다.
- 이후 실제 인스턴스의 save()를 호출한다.
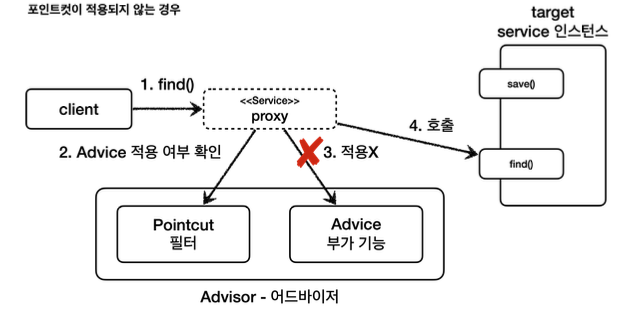
- 클라이언트가 프록시의 find()를 호출한다.
- 포인트컷에게 Service 클래스의 find() 메서드에 어드바이스를 적용해도 될지 물어본다.
- 포인트컷이 false를 반환한다. 따라서 어드바이스를 호출하지 않고, 부가 기능도 적용되지 않는다.
- 실제 인스턴스를 호출한다.
예제 코드3 - 스프링이 제공하는 포인트컷
사실, 포인트컷을 저렇게 직접 구현해서 사용할 일은 앞으로 없다. 이미 스프링은 여러 포인트컷을 제공하고 있고 그 중 하나를 골라 사용하거나 결국엔 끝판왕인 AspectJExpressionPointcut을 사용하게 될 것이다. 한번 스프링이 제공하는 여러 포인트컷 중 하나를 골라서 사용해보자.
@Test
@DisplayName("스프링이 제공하는 포인트컷")
void advisorTest3() {
// 실제 객체 서비스
ServiceInterface target = new ServiceImpl();
// ProxyFactory 객체 생성 후 실제 객체를 전달
ProxyFactory proxyFactory = new ProxyFactory(target);
// 스프링이 제공하는 포인트 컷 중 하나인 NameMatchMethodPointcut
NameMatchMethodPointcut pointcut = new NameMatchMethodPointcut();
// Method 명이 save인 애들에게 Advice를 적용해주는 Pointcut을 만든다.
pointcut.setMappedName("save");
DefaultPointcutAdvisor advisor = new DefaultPointcutAdvisor(pointcut, new TimeAdvice());
// ProxyFactory에 advisor 추가
proxyFactory.addAdvisor(advisor);
// ProxyFactory 로부터 proxy 를 꺼내온다.
ServiceInterface proxy = (ServiceInterface) proxyFactory.getProxy();
// Pointcut에 의하여 Advice 적용된다.
proxy.save();
// Pointcut에 의하여 Advice 적용되지 않는다.
proxy.find();
}- 스프링이 제공하는 NameMatchMethodPointcut을 사용해보자.
NameMatchMethodPointcut pointcut = new NameMatchMethodPointcut();
pointcut.setMappedName("save");
- 말 그대로 메서드의 이름으로 Pointcut을 설정하는 Pointcut이다. 위 코드처럼 'save'라는 값을 setMappedName()에 넘겨주면 이 Pointcut은 'save'라는 메서드명을 가진 요청에 한하여 Advice를 적용한다. 나머지는 동일하다.
실행 결과

- save()가 호출됐을 땐 TimeProxy가 동작하고 그렇지 않은 find()가 호출됐을 땐 Advice가 적용되지 않았다. 이렇게 스프링이 제공해주는 Pointcut으로 편리하게 Pointcut을 만들 수 있다.
예제 코드4 - 여러 어드바이저 함께 적용
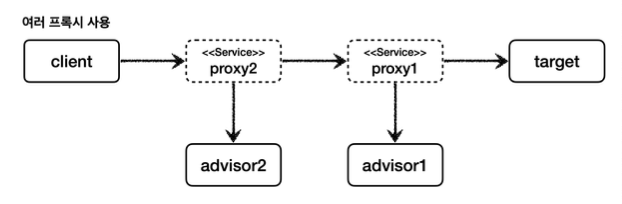
어드바이저는 하나의 포인트컷과 하나의 어드바이스를 가지고 있다. 만약, 여러 어드바이저를 하나의 target에 적용하려면 어떻게 해야할까? 쉽게 이야기해서 하나의 target에 여러 어드바이스를 적용하려면 어떻게 해야할까? 지금 떠오르는 방법은 프록시를 여러개 만들면 될 것 같다.
프록시 여러개로 구현
package cwchoiit.springadvanced.proxy.advisor;
import cwchoiit.springadvanced.proxy.common.advice.TimeAdvice;
import cwchoiit.springadvanced.proxy.common.service.ServiceImpl;
import cwchoiit.springadvanced.proxy.common.service.ServiceInterface;
import lombok.extern.slf4j.Slf4j;
import org.aopalliance.intercept.MethodInterceptor;
import org.aopalliance.intercept.MethodInvocation;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import org.springframework.aop.Pointcut;
import org.springframework.aop.framework.ProxyFactory;
import org.springframework.aop.support.DefaultPointcutAdvisor;
@Slf4j
public class MultiAdvisorTest {
@Test
@DisplayName("여러 프록시")
void multiAdvisorTest1() {
ServiceInterface target = new ServiceImpl();
ProxyFactory proxyFactory1 = new ProxyFactory(target);
DefaultPointcutAdvisor advisor1 = new DefaultPointcutAdvisor(Pointcut.TRUE, new Advice1());
proxyFactory1.addAdvisor(advisor1);
ServiceInterface proxy1 = (ServiceInterface) proxyFactory1.getProxy();
ProxyFactory proxyFactory2 = new ProxyFactory(proxy1);
DefaultPointcutAdvisor advisor2 = new DefaultPointcutAdvisor(Pointcut.TRUE, new Advice2());
proxyFactory2.addAdvisor(advisor2);
ServiceInterface proxy2 = (ServiceInterface) proxyFactory2.getProxy();
proxy2.find();
}
static class Advice1 implements MethodInterceptor {
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
log.info("Advice1 invoked");
return invocation.proceed();
}
}
static class Advice2 implements MethodInterceptor {
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
log.info("Advice2 invoked");
return invocation.proceed();
}
}
}- 코드상에 새로운 개념은 없다. 프록시를 여러개 입혔다.
실행 결과
11:35:11.287 [Test worker] INFO cwchoiit.springadvanced.proxy.advisor.MultiAdvisorTest -- Advice2 invoked
11:35:11.289 [Test worker] INFO cwchoiit.springadvanced.proxy.advisor.MultiAdvisorTest -- Advice1 invoked
11:35:11.289 [Test worker] INFO cwchoiit.springadvanced.proxy.common.service.ServiceImpl -- find 호출- 차례대로 Advice2, Advice1이 실행된다. 그리고 실제 객체인 target의 로직까지 실행됐다.
- 그러나, 이 방법이 잘못된 것은 아니지만 프록시를 2번 생성해야 한다는 문제가 있다. 만약 적용해야 하는 어드바이저가 10개라면 10개의 프록시를 생성해야 한다.
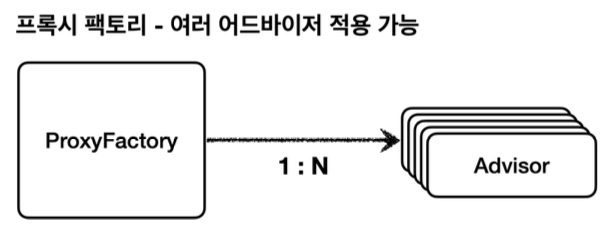
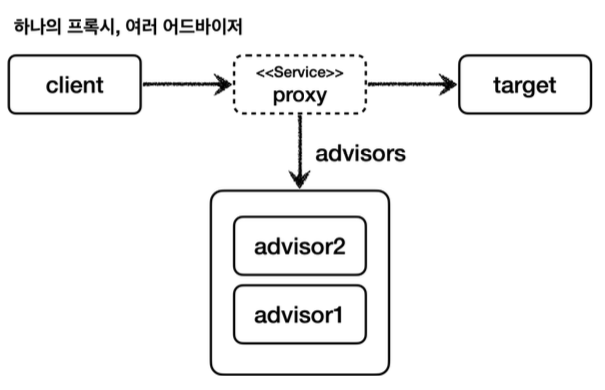
하나의 프록시, 여러 어드바이저로 구현
스프링은 이 문제를 해결하기 위해 하나의 프록시에 여러 어드바이저를 적용할 수 있게 만들어 두었다.
@Test
@DisplayName("하나의 프록시, 여러 어드바이저")
void multiAdvisorTest2() {
DefaultPointcutAdvisor advisor1 = new DefaultPointcutAdvisor(Pointcut.TRUE, new Advice1());
DefaultPointcutAdvisor advisor2 = new DefaultPointcutAdvisor(Pointcut.TRUE, new Advice2());
ServiceInterface target = new ServiceImpl();
ProxyFactory proxyFactory = new ProxyFactory(target);
proxyFactory.addAdvisors(advisor2, advisor1);
ServiceInterface proxy = (ServiceInterface) proxyFactory.getProxy();
proxy.find();
}- 프록시 팩토리에 원하는 어드바이저를 addAdvisors(...)로 등록하면 끝이다. 먼저 넣은 어드바이저가 먼저 실행된다.

정리
결과적으로, 여러 프록시를 사용할 때와 비교해서 결과는 같으나 성능은 더 좋다. 스프링 AOP도 이와 같다. AOP 적용 수만큼 프록시가 생성되는 것이 아니다! 스프링은 AOP를 적용할 때, 최적화를 진행해서 지금처럼 프록시는 하나만 만들고, 하나의 프록시에 여러 어드바이저를 적용한다. 정리하면 하나의 target에 여러 AOP가 적용되어도, 스프링의 AOP는 target마다 하나의 프록시만 생성한다. 꼭 기억하자!
프록시팩토리 - 적용1
지금까지 학습한 프록시 팩토리를 사용해서 애플리케이션에 프록시를 만들어보자. 먼저 인터페이스가 있는 V1 애플리케이션에 LogTrace 기능을 프록시 팩토리를 통해서 프록시를 만들어 적용해보자.
LogTraceAdvice
package cwchoiit.springadvanced.proxy.config.v3_proxyfactory.advice;
import cwchoiit.springadvanced.trace.TraceStatus;
import cwchoiit.springadvanced.trace.logtrace.LogTrace;
import lombok.RequiredArgsConstructor;
import org.aopalliance.intercept.MethodInterceptor;
import org.aopalliance.intercept.MethodInvocation;
import java.lang.reflect.Method;
@RequiredArgsConstructor
public class LogTraceAdvice implements MethodInterceptor {
private final LogTrace trace;
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
TraceStatus status = null;
Method method = invocation.getMethod();
try {
String message = method.getDeclaringClass().getSimpleName() + "." + method.getName() + "()";
status = trace.begin(message);
Object result = invocation.proceed();
trace.end(status);
return result;
} catch (Exception e) {
trace.exception(status, e);
throw e;
}
}
}
- Advice를 만들기 위해 MethodInterceptor를 구현하는 LogTraceAdvice 클래스를 만들었다. MethodInterceptor가 구현해야 하는 invoke()를 기존에 계속 사용했던 LogTrace 기능으로 채워넣었다. Advice는 실제 객체를 주입받지 않아도 되기 때문에 편리함을 준다.
- 이제 Advice를 만들었으니까 ProxyFactory를 통해서 프록시를 만들고 스프링 빈으로 등록해보자.
ProxyFactoryConfigV1
package cwchoiit.springadvanced.proxy.config.v3_proxyfactory;
import cwchoiit.springadvanced.proxy.app.v1.*;
import cwchoiit.springadvanced.proxy.config.v3_proxyfactory.advice.LogTraceAdvice;
import cwchoiit.springadvanced.trace.logtrace.LogTrace;
import lombok.extern.slf4j.Slf4j;
import org.springframework.aop.Advisor;
import org.springframework.aop.framework.ProxyFactory;
import org.springframework.aop.support.DefaultPointcutAdvisor;
import org.springframework.aop.support.NameMatchMethodPointcut;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Slf4j
@Configuration
public class ProxyFactoryConfigV1 {
@Bean
public OrderRepositoryV1 orderRepositoryV1(LogTrace trace) {
OrderRepositoryV1 target = new OrderRepositoryV1Impl();
ProxyFactory proxyFactory = new ProxyFactory(target);
proxyFactory.addAdvisor(getAdvisor(trace));
OrderRepositoryV1 proxy = (OrderRepositoryV1) proxyFactory.getProxy();
log.info("OrderRepositoryV1 proxy: {}, targetClass: {}", proxy.getClass(), target.getClass());
return proxy;
}
@Bean
public OrderServiceV1 orderServiceV1(LogTrace trace) {
OrderServiceV1 target = new OrderServiceV1Impl(orderRepositoryV1(trace));
ProxyFactory proxyFactory = new ProxyFactory(target);
proxyFactory.addAdvisor(getAdvisor(trace));
OrderServiceV1 proxy = (OrderServiceV1) proxyFactory.getProxy();
log.info("OrderServiceV1 proxy: {}, targetClass: {}", proxy.getClass(), target.getClass());
return proxy;
}
@Bean
public OrderControllerV1 orderControllerV1(LogTrace trace) {
OrderControllerV1 target = new OrderControllerV1Impl(orderServiceV1(trace));
ProxyFactory proxyFactory = new ProxyFactory(target);
proxyFactory.addAdvisor(getAdvisor(trace));
OrderControllerV1 proxy = (OrderControllerV1) proxyFactory.getProxy();
log.info("OrderControllerV1 proxy: {}, targetClass: {}", proxy.getClass(), target.getClass());
return proxy;
}
private Advisor getAdvisor(LogTrace trace) {
NameMatchMethodPointcut pointcut = new NameMatchMethodPointcut();
pointcut.setMappedNames("request*", "order*", "save*");
LogTraceAdvice logTraceAdvice = new LogTraceAdvice(trace);
return new DefaultPointcutAdvisor(pointcut, logTraceAdvice);
}
}- 포인트컷은 NameMatchMethodPointcut을 사용한다. 여기에는 심플 매칭 기능이 있어서 *을 매칭할 수 있다.
- request*, order*, save* → request, order, save로 시작하는 메서드에 포인트컷은 true를 반환한다.
- 이렇게 설정한 이유는 noLog() 메서드에는 어드바이스를 적용하지 않기 위해서다.
- 어드바이저는 포인트컷(NameMatchMethodPointcut), 어드바이스(LogTraceAdvice)를 가지고 있다.
- 프록시 팩토리에 각각의 target과 advisor를 등록해서 프록시를 생성한다. 그리고 생성된 프록시를 스프링 빈으로 등록한다.
테스트 해보자. '/v1/request'로 요청하면 LogTrace 정보가 남아야한다. '/v1/no-log'로 요청하면 LogTrace 정보가 남지 않아야 한다.

프록시팩토리 - 적용2
구체 클래스로 프록시를 만든다고 달라지는 건 없다. 반환 타입만 달라질 뿐이다. 왜냐하면 ProxyFactory를 사용하기 때문이다. ProxyFactory는 알아서 구체 클래스면 CGLIB로 프록시를, 인터페이스면 JDK 동적 프록시를 사용해서 프록시를 만들어 준다.
ProxyFactoryConfigV2
package cwchoiit.springadvanced.proxy.config.v3_proxyfactory;
import cwchoiit.springadvanced.proxy.app.v1.*;
import cwchoiit.springadvanced.proxy.app.v2.OrderControllerV2;
import cwchoiit.springadvanced.proxy.app.v2.OrderRepositoryV2;
import cwchoiit.springadvanced.proxy.app.v2.OrderServiceV2;
import cwchoiit.springadvanced.proxy.config.v3_proxyfactory.advice.LogTraceAdvice;
import cwchoiit.springadvanced.trace.logtrace.LogTrace;
import lombok.extern.slf4j.Slf4j;
import org.springframework.aop.Advisor;
import org.springframework.aop.framework.ProxyFactory;
import org.springframework.aop.support.DefaultPointcutAdvisor;
import org.springframework.aop.support.NameMatchMethodPointcut;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Slf4j
@Configuration
public class ProxyFactoryConfigV2 {
@Bean
public OrderRepositoryV2 orderRepositoryV2(LogTrace trace) {
OrderRepositoryV2 target = new OrderRepositoryV2();
ProxyFactory proxyFactory = new ProxyFactory(target);
proxyFactory.addAdvisor(getAdvisor(trace));
OrderRepositoryV2 proxy = (OrderRepositoryV2) proxyFactory.getProxy();
log.info("OrderRepositoryV2 proxy: {}, targetClass: {}", proxy.getClass(), target.getClass());
return proxy;
}
@Bean
public OrderServiceV2 orderServiceV2(LogTrace trace) {
OrderServiceV2 target = new OrderServiceV2(orderRepositoryV2(trace));
ProxyFactory proxyFactory = new ProxyFactory(target);
proxyFactory.addAdvisor(getAdvisor(trace));
OrderServiceV2 proxy = (OrderServiceV2) proxyFactory.getProxy();
log.info("OrderServiceV2 proxy: {}, targetClass: {}", proxy.getClass(), target.getClass());
return proxy;
}
@Bean
public OrderControllerV2 orderControllerV2(LogTrace trace) {
OrderControllerV2 target = new OrderControllerV2(orderServiceV2(trace));
ProxyFactory proxyFactory = new ProxyFactory(target);
proxyFactory.addAdvisor(getAdvisor(trace));
OrderControllerV2 proxy = (OrderControllerV2) proxyFactory.getProxy();
log.info("OrderControllerV2 proxy: {}, targetClass: {}", proxy.getClass(), target.getClass());
return proxy;
}
private Advisor getAdvisor(LogTrace trace) {
NameMatchMethodPointcut pointcut = new NameMatchMethodPointcut();
pointcut.setMappedNames("request*", "order*", "save*");
LogTraceAdvice logTraceAdvice = new LogTraceAdvice(trace);
return new DefaultPointcutAdvisor(pointcut, logTraceAdvice);
}
}
- 끝이다. Advice도 Pointcut도 이미 만들어 놓은거니까 가져다가 사용만 하면 된다.
- '/v2/request' 로 요청하면 마찬가지로 LogTrace의 정보를 출력한다.


정리
확실히 프록시로 사용될 코드도 Advice 하나만 만들면 되고, 동적 프록시를 만들기 때문에 프록시를 일일이 만들어 줄 필요도 없으며 구체클래스냐 인터페이스냐에 따라 나뉘어지는 동적 프록시 생성 방법을 스프링의 도움을 받아 프록시 팩토리를 사용하므로써 고민하지 않게됐다.
훨씬 개선되었지만 여전히 불편함은 남아있다.
- 너무 많은 설정 - ProxyFactoryConfigV1, ProxyFactoryConfigV2와 같이 설정 파일이 지나치게 많다. 예를 들어, 애플리케이션에 스프링 빈이 100개가 있다면 여기에 프록시를 통해 부가 기능을 적용하려면 100개의 동적 프록시 생성 코드를 만들어야 한다. 무수히 많은 설정 파일 때문에 설정 지옥을 경험하게 될 것이다. 최근에는 스프링 빈을 수동으로 등록하는 케이스보다 컴포넌트 스캔을 사용하는게 일반적인데 이렇게 직접 등록하는 것도 모자라서 프록시를 적용하는 코드까지 빈 생성 코드에 넣어야 한다.
- 컴포넌트 스캔 - 애플리케이션 V3처럼 컴포넌트 스캔을 사용하는 경우, 지금까지 학습한 방법으로는 프록시 적용이 불가능하다. 왜냐하면 실제 객체를 컴포넌트 스캔으로 스프링 컨테이너에 스프링 빈으로 등록을 다 해버린 상태이기 때문이다. 지금까지 학습한 방법으로 프록시를 적용하려면, 실제 객체를 스프링 컨테이너에 빈으로 등록하는 것이 아니라, ProxyFactoryConfigV2에서 한 것처럼, 부가 기능이 있는 프록시를 실제 객체 대신 스프링 컨테이너에 빈으로 등록해야 한다.
이 두 가지 문제를 모두 해결하는 방법이 빈 후처리기이다.
'Spring Advanced' 카테고리의 다른 글
| AOP와 @Aspect (0) | 2023.12.29 |
|---|---|
| 빈 후처리기(BeanPostProcessor) (2) | 2023.12.27 |
| CGLIB,스프링이 지원하는 ProxyFactory (0) | 2023.12.14 |
| Proxy/Decorator Pattern 2 (JDK 동적 프록시) (0) | 2023.12.14 |
| Proxy/Decorator Pattern (0) | 2023.12.13 |