모든 데이터 조회 시 중요하게 생각할 것은 요청의 수를 줄일 수 있다면 최대한 줄이는 게 좋다.
다음 그림을 보자.
이런 구조를 가지고 있는 Blog Collection이 있다고 할 때, 블로그 전체를 조회하는 무식한 경우는 당연히 없겠지만 그런 경우가 있다고 가정해보고 전체 블로그를 가져오게 될 때, 만약 해당 블로그의 유저 정보와 커멘트들도 담아와야 한다면 블로그마다 유저와 커멘트들을 조회하는 비용이 발생한다.
코드의 내용은 대략 블로그 전체를 가져온 후 각 블로그마다 블로그의 유저 아이디를 가져와서 해당 아이디를 통해 유저와 커멘트를 가져온다. 이는 모든 블로그를 가져오는 요청을 한 번, 블로그를 가져오는 요청에서 처리하는 데이터베이스 조회, 조회된 데이터의 유저 및 커멘트를 가져오기 위한 요청 한 번, 각 요청에서 처리하는 데이터베이스 조회 등 상당히 많은 비용이 발생한다.
이것을 해결할 수 있는 방법 중 하나가 MongoDB의 'populate'이다.
populate은 특정 컬렉션의 도큐멘트에서 가져올 다른 객체가 있다면 (블로그의 유저와 커멘트) 해당 객체도 같이 조회하여 조회된 데이터를 추가해주는 방법이다.
이게 나의 블로그 스키마인데 커멘트는 없다. 블로그에는 커멘트라는 데이터는 없고 커멘트에만 블로그라는 데이터를 참조한다. 그렇다면 당연히 blog 전체를 가져오는 find()에서 populate를 사용할 때 comments를 담을 수 없게 된다. 그럼 커멘트를 담고 싶을 때 방법은 두가지인데 첫번째는 스키마에 커멘트를 유저처럼 추가하거나, virtual을 사용하는 것이다. 난 후자를 선택했다.
SyntaxError: Cannot use import statement outside a module
at internalCompileFunction (node:internal/vm:73:18)
at wrapSafe (node:internal/modules/cjs/loader:1178:20)
at Module._compile (node:internal/modules/cjs/loader:1220:27)
at Module._extensions..js (node:internal/modules/cjs/loader:1310:10)
at Module.load (node:internal/modules/cjs/loader:1119:32)
at Module._load (node:internal/modules/cjs/loader:960:12)
at Function.executeUserEntryPoint [as runMain] (node:internal/modules/run_main:86:12)
at node:internal/main/run_main_module:23:47
뭔지는 당연히 몰랐기에 구글링 시도!
우선 require로 패키지를 가져오지 않고 import를 사용하니 이런 에러를 마주했는데, package.json 파일에서 "type": "module"을 추가하면 해결할 수 있다고 한다. 추가한 후 다시 실행하니 다른 에러가 발생한다.
TypeError [ERR_UNKNOWN_FILE_EXTENSION]: Unknown file extension ".ts"for /Users/cw.choiit/mongo/tutorial/src/api/client.ts
at new NodeError (node:internal/errors:405:5)
at Object.getFileProtocolModuleFormat [as file:] (node:internal/modules/esm/get_format:79:11)
at defaultGetFormat (node:internal/modules/esm/get_format:124:36)
at defaultLoad (node:internal/modules/esm/load:89:20)
at nextLoad (node:internal/modules/esm/loader:163:28)
at ESMLoader.load (node:internal/modules/esm/loader:603:26)
at ESMLoader.moduleProvider (node:internal/modules/esm/loader:457:22)
at new ModuleJob (node:internal/modules/esm/module_job:64:26)
at ESMLoader.#createModuleJob (node:internal/modules/esm/loader:480:17)
at ESMLoader.getModuleJob (node:internal/modules/esm/loader:434:34) {
code: 'ERR_UNKNOWN_FILE_EXTENSION'
}
.ts 파일을 못 읽는 것 같은데 역시 뭔지 모르니 다시 서치!
Typescript를 사용하고 있고, ts-node로 typescript 파일을 실행하기 위해서 tsconfig.json 파일을 수정해야 한다.
compilerOptions의 module을 commonjs로 target을 es2016으로 설정하고 다음과 같이 ts-node의 esm을 true로 설정한다.
하고 나서 다시 실행하니 또 다른 에러.. 에러 지옥에 갇혔지만 끝까지 가면 내가 다 이긴다.
ReferenceError: exports is not defined in ES module scope
at file:///Users/cw.choiit/mongo/tutorial/src/api/client.ts:14:23
at ModuleJob.run (node:internal/modules/esm/module_job:194:25)
이건 알 거 같다. 제일 처음 package.json 파일에서 "type": "module"을 추가했는데 저 부분을 다시 지워야 할 것 같다.
그래서 package.json 파일에서 "type": "module"을 지우고 아래와 같은 package.json 파일로 저장했다.
마침내 정상 실행이 됐다.
정리를 하자면
1. Typescript를 사용 중이라면 tsconfig.json에서 다음과 같은 설정이 필요
제목 그대로 Web Server와 WAS(Web Application Server)의 차이가 무엇인지 알아보고 공부한 내용을 작성해보고자 한다.
Web Server
웹 서버는 우선 HTTP 기반으로 동작한다. 그리고 웹 서버는 정적 리소스를 제공한다. 여기서 정적 리소스는 정적인 파일(HTML, CSS, JS, 이미지, 동영상)을 의미한다. 그리고 정적 리소스를 제공한다는 건 그 리소스들을 필요할 때 서버가 Serving을 한다고 생각하면 된다.
가장 대표적인 웹 서버로는 Apache, NGINX가 있다.
그래서 아래 그림을 보면 클라이언트가 특정 요청을 보내면 웹 서버에서는 요청에 응답하기 위해 요청에 걸맞은 정적 리소스를 제공한다.
이를 웹 서버라고 한다.
WAS(Web Application Server)
그렇다면 웹 애플리케이션 서버란 무엇인가? 이 또한 HTTP를 기반으로 동작하는데, 프로그램 코드를 실행해서 애플리케이션 로직을 수행해 준다. 즉, 동적으로 로직을 수행할 수 있단 얘기다. 예를 들면, 로그인할 때 해당 유저가 실제 DB에 있는지 확인하는 조회 과정을 정적 리소스만으로 확인하는 건 불가능한데 이를 실행할 수 있다는 얘기다.
그리고 이 WAS는 웹 서버의 기능을 포함하고 있다. 즉, 정적 리소스도 또한 Serving 해준다.
가장 대표적인 WAS로는 Tomcat, Jetty 같은 녀석들이다.
그러니까 큰 범주로 WAS는 Web Server보다 큰 영역을 가지고 있다고 보면 될 것 같다.
Difference between WAS and Web Server
위에서도 설명한 내용을 토대로 한 문장으로 요약해보면 웹 서버는 정적 리소스를 제공하는 서버이고 웹 애플리케이션 서버는 애플리케이션 로직을 동적으로도 수행이 가능한 서버라고 생각할 수 있다.
그러나, 요즘은 이 둘 간의 경계가 모호하다. 웹 서버도 프로그램을 실행하는(동적으로) 기능을 가지고 있는 경우가 있고 웹 애플리케이션 서버 역시 웹 서버의 기능을 제공하다 보니 경계가 모호해졌다. 그러나 시작점은 저런 차이가 있었다는 것이고 WAS는 애플리케이션 코드를 실행하는데 더 특화되어 있다고 볼 수 있다.
웹 서버와 웹 애플리케이션 서버의 협력
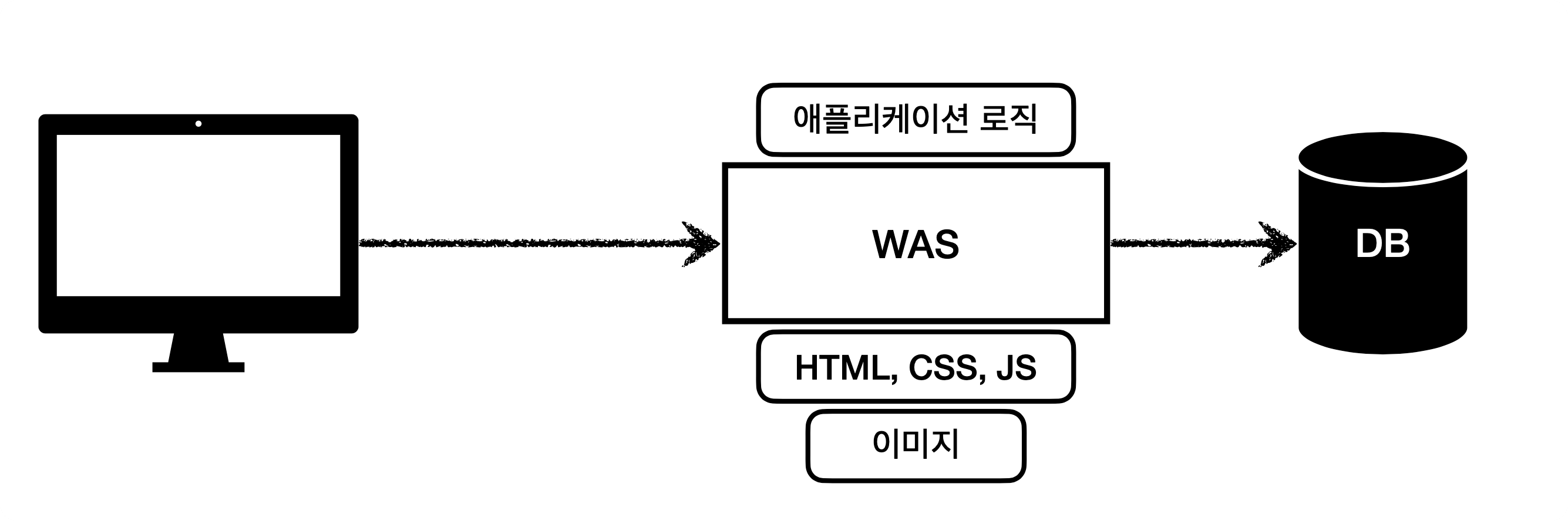
위에 작성한 내용을 토대로 한다면, WAS만으로도 서비스를 제공할 수 있을 것이다. 웹 서버 역할도 WAS는 수행할 수 있기 때문에.
그래서 WAS와 DB만 가지고도 아래 그림처럼 서비스를 제공할 수 있다.
그러나, 위 사진과 같은 시스템 구조는 WAS가 모든것을 담당하고 있기 때문에 비용이 많이 들어간다. WAS는 애플리케이션 로직을 수행하는데 특화된 녀석이고 정적 리소스를 제공할 수는 있지만 이렇게 모든 역할을 다 해버리면 부하가 있을 수 있다.
그리고 애시당초에 애플리케이션 로직과 정적 리소스는 상대적으로 비용 차이가 많이 난다. 애플리케이션 로직 수행의 비용이 훨씬 비싸다.
이 구조의 가장 큰 문제는 애플리케이션 로직을 수행하는 부분에는 아무런 문제가 없는데 정적 리소스의 문제가 생겨 애플리케이션 로직도 수행 불가능한 상태가 되는 경우이다. 그리고 그 반대로도 마찬가지.
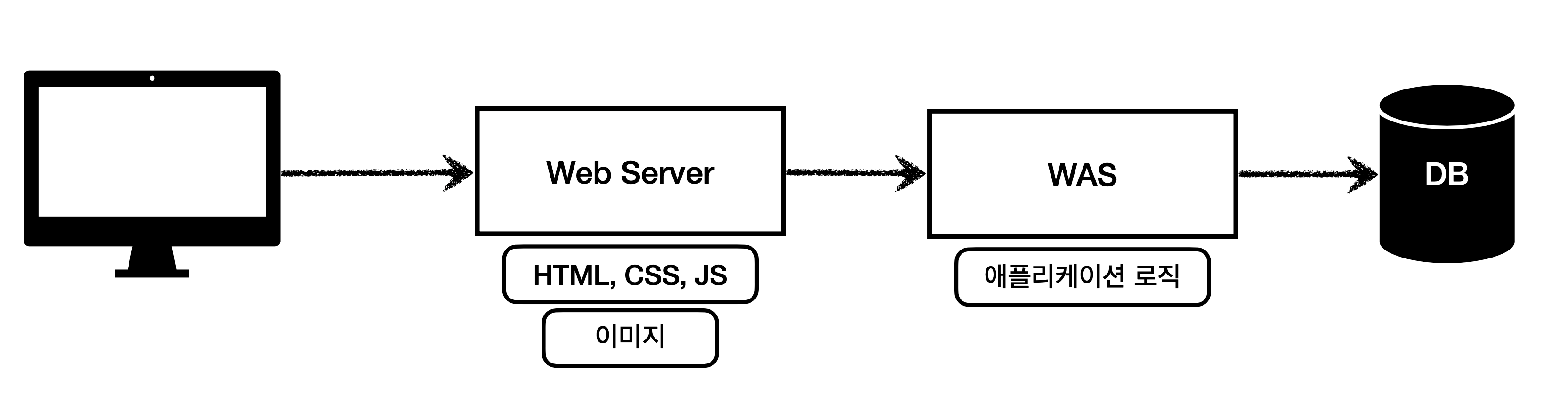
그렇기 때문에 정적 리소스는 웹 서버가 처리하게 하고 애플리케이션 로직은 웹 애플리케이션 서버가 처리하도록 역할 분담을 통해 더 좋은 구조를 구성할 수 있다. 아래 그림을 보자.
이런 구조를 가졌을 때 클라이언트가 요청을 하면 정적인 리소스만을 필요한 화면을 요청했을 때 앞단인 웹 서버만으로 처리가 가능해지고 애플리케이션 로직이나 데이터베이스 조회가 필요한 경우 웹 서버는 클라이언트 요청을 WAS에게 위임하여 처리한다. 이런 구조가 더 좋은 구조가 될 수 있다. 이렇게 효율적으로 리소스를 관리할 수 있게 된다면 여기서 파생되는 또 다른 이점이 있는데 그건 이런 경우다.
서비스의 특성에 따라 정적 리소스가 더 많이 사용된다면 정적 리소스를 담당하는 웹 서버를 늘리고 애플리케이션 리소스가 더 많이 사용된다면 애플리케이션 리소스를 담당하는 웹 애플리케이션 서버를 더 늘려 시스템의 안정도를 높일 수 있다. 다음 그림과 같은 모습이다.
마무리
간단하게 WAS와 Web Server의 차이와 협력의 가능성을 알아보았다. 이게 정답이라는 건 아니고 이러한 내용이 있을 수 있다는 점. 항상 계속 배울 게 있다는 게 좋은 일인 거 같다. 추후에 특정 서비스를 만들 때 이 점을 참고해봐야겠다.
간단히 말해 Dynamic IP Address는 동적 IP를 말하고 동적 IP는 변경 가능성이 있는 고정된 IP가 아닌 IP Address를 의미하고 Static IP Address는 정적 IP를 말하며 변하지 않는 IP Address를 말한다.
동적 IP는 내가 통신사와 계약하고 네트워크를 하나 받으면 해당 네트워크에 진입할 수 있는 공용 IP를 하나 받게 되는데 그 IP를 오랜 시간 사용하지 않게 되면 관리 기관에서 그 IP를 회수해간다. 이것이 동적 IP다. IP Address는 부족하기 때문에 안 쓰는 IP를 회수해서 새로운 IP가 필요한 호스트한테 할당해 주는 것이다. 합리적이다.
근데, 문제는 만약 내 네트워크가 서버를 기동중인 호스트가 있는 네트워크고 동적 IP라면 내 IP가 바뀔 수 있기 때문에 서버 운영에 문제가 생길 수 있다.
예를 들어, 59.29.17.178이라는 공용 IP를 가지고 있고 8088 포트로 특정 웹 서버를 운영중이라고 할 때 동적 IP의 특성으로 인해 IP가 회수되면 그 사실을 모르는 서비스 사용자들은 같은 IP로 접속했을 때 당혹스러움을 감추지 못할 것이다.
이를 방지하기 위해서 Static IP Address가 있는 것인데 이는 내 IP가 한번 할당한 후에 변경되지 않고 싶을 때 사용한다.
만약 내가 내 PC에 웹 서버를 하나 만들었을 때 서버에 접속하려면 내 PC의 IP와 포트번호가 필요하다.
왜냐하면 하나의 호스트에 여러 서버가 기동 되어 있을 수 있기 때문에 정확한 주소가 필요하다.
그리고 이럴 때 포트번호가 사용된다. 쉽게 설명해 보자면 IP는 아파트의 동, 포트번호는 호수라고 생각해 보면 좀 더 와닿을까?
그리고 이 포트는 일반적으로 사용되는 번호가 있는데 이를 Well known port라고 한다.
대표적인 http - 80, ssh - 22와 같은 포트 말이다.
이렇게 어떤 약속처럼 여겨진 포트를 잘 알려진 포트라고 하며 0 - 1023번까지 있다.
1024 - 65535까지의 포트는 사용자가 자유로이 설정할 수 있는 포트라고 보면 되는데 이 여유 포트를 통해 포트 포워딩을 하는 방법을 알아보고 포트 포워딩이 무엇인지도 알아보자.
Port forwarding
포트 포워딩이란 외부에서 특정 주소를 접속했을 때 주소의 IP와 포트를 입력하는데 (예를 들면 59.29.14.178:8888)이때 이 요청을 받은 공유기가 8888과 매핑된 주소와 포트를 찾아 요청을 포워딩해주는 것을 포트 포워딩이라고 한다.
공유기 얘기가 나왔으니까 아래 그림을 봐보자.
이러한 네트워크 구조를 가지고 있을 때, 192.168.0.4의 주소를 가진 호스트가 웹 서버를 기동 중이라고 가정해 보자.
그리고 그 웹 서버를 8088번 포트로 실행중일 때 외부에서 이 웹 서버에 접근하기 위해서 어떻게 해야 할까? 192.168.0.3은 사설 IP이기 때문에 외부에서 직접 접근이 불가능하므로 외부에서도 접근 가능한 공용 IP로 요청해야 한다.
그렇다고 마냥 59.29.14.178로 접근한다고 하면 원하는 결과를 얻진 못할 거다. 그 네트워크를 통해 들어와서 '어떤 호스트에 연결할 건데?'라는 질문에 대답하지 못할 테니까.
그렇기 때문에 포트포워딩이 필요하다. 즉 약속을 하는 것이다. 예를 들어 59.29.14.178:8088로 접속하면 192.168.0.4:8088로 접속할 수 있도록.
당연히 외부 포트와 내부 포트는 달라질 수 있다. 외부 포트는 59.29.14.178:8088을 의미하고 내부 포트는 192.168.0.4:8088을 의미하는데 외부 포트를 8000으로 사용해도, 8888로 사용해도 상관없다. 그 포트가 원하는 8088로 매핑만 되어 있다면.
그리고 이 포트 포워딩은 간단하게 공유기 아이피로 접속해서 설정해 줄 수 있다.
공유기 아이피를 브라우저에 쳐서 공유기에 접속하면 아래 화면처럼 포트 포워딩을 해줄 수 있다.
내부 IP 주소에는 원하는 호스트의 사설 IP를 작성하고, 외부포트와 내부포트를 설정해 주자. 외부포트는 위에서 말한 것처럼 비어있는 어떤 포트라도 상관없고 내부 포트는 원하는 웹 서버가 사용하고 있는 포트를 입력해 주면 된다.
가운데 누가 봐도 공유기처럼 생긴 그림이 공유기다. 이 공유기는 통신사와 계약을 해서 네트워크를 하나 받으면 네트워크는 전 세계 모두와 통신할 수 있는 공용 IP가 하나 생기는데 그 IP는 그림에서 59.29.14.178이다.
그렇다면 만약 인터넷을 사용할 기기가 여러 대 있다면 기기 수만큼 통신사와 계약해야 할까? 그것도 방법이 될 수 있지만 그것은 비효율적이다. 그래서 공유기를 사용한다. 공유기는 큰 범주에서 WAN, LAN 두 개로 나뉘는데 WAN은 Wide Area Network의 약자로, 전 세계 누구와도 통신이 가능한 네트워크다. LAN은 Local Area Network의 약자로, 지역적으로만 통신이 가능한 네트워크다. LAN은 무선과 유선이 동시에 존재할 수 있는데 그림과 같이 핸드폰은 선 없이 무선으로 네트워크가 연결되어 있고 이를 보통 와이파이라고 칭한다.
공유기 또한 IP가 존재한다. 공유기 IP를 그림에서는 192.168.0.1로 설정했다. 그리고 공유기의 IP를 Gateway address 또는 Router address라고 표현한다. 공유기의 IP 역시 사설 IP로 외부에서는 접근이 불가능하다.
전 세계 어디에서나 접근이 가능한 IP를 공용 IP 또는 public IP address라고 하는데 그림에서는 59.29.14.178이다.
그리고 그림에서 192.168.0.1192.168.0.2192.168.0.3192.168.0.4와 같은 IP를 사설 IP 또는 private IP address라고 한다.
저들은 저 지역, 즉 같은 공유기를 사용하고 있는 한 별다른 문제없이 서로 통신이 가능하게 된다.
private IP address는 이미 사전에 범위가 지정되어 있는데 그 범위는 다음과 같다.
10.0.0.0 - 10.255.255.255
16,777,216개
172.16.0.0 - 172.31.255.255
1,048,576개
192.168.0.0 - 192.168.255.255
65536개
위 테이블처럼 사설 IP의 주소 체계는 이미 번호가 정해져 있고 내가 누군가에게 IP가 뭐예요?라고 물어봤을 때 누군가가 192.168.0.5요!라고 하면 바로 '아 이 사람 나한테 사설 IP를 알려준 거구나?'라고 생각할 수 있다.
10. 체계는 큰 범위의 주소 체계고 순서대로 192. 체계가 작은 네트워크를 구성할 때 사용되는 주소 체계다.
공유기가 있으면 브라우저에 공유기 IP를 쳐보면 공유기에 접속할 수 있는 화면이 띄워진다.
위 화면에 접속 정보를 입력해서 접속하면 이 공유기가 할당받은 public IP를 알아낼 수 있지만 더 좋은 방법은 브라우저에"내 IP"라고 검색했을 때 나오는 IP로도 확인 가능하다. 이는 왜 가능할까? 당연히 외부에서 나와 통신할 수 있는 유일한 IP를 내가 가지고 있으면 외부에서 나에게 응답해 주는 IP 또한 그 IP일 테니까.
NAT (Network Address Translation)
이제 특정 공유기와 연결된 기기가 공유기 내에 존재하지 않는 기기 또는 서버에 접속한다고 생각해 보자. 즉, 집에서 네이버를 검색했을 때 네이버로부터 응답을 받는 과정을 살펴보는 것이다.
우선 위 그림에서 192.168.0.3이라는 주소를 가지는 호스트가 브라우저에 '네이버'를 검색했다고 가정하면 우선은 외부와 통신이 가능한 유일한 네트워크는 공유기에 WAN으로 연결된 네트워크이기 때문에 공유기를 거쳐야 한다. 공유기한테 먼저 요청이 전해지면 공유기는 여기서 첫 번째 판단을 한다. '이 주소가 내 지역(공유기에 연결된 기기들)에 있는 기기인가?' 그렇지 않기 때문에 공유기는 외부와 통신이 가능한 네트워크인 59.29.14.178을 통해 나의 요청을 보낸다. 당연히 이 과정 중에 생략된 많은 부분이 있지만 (예를 들면, 호스트가 네이버가 가진 IP를 알아내는 과정, 네이버에 요청한 기기를 공유기가 기록, 요청한 기기의 주소를 외부 IP 주소로 변경 등) 큰 그림을 볼 때 공유기가 외부와 통신이 가능한 네트워크를 통해 나의 요청을 해당 주소로 보내면 그 주소가 응답해서 다시 59.29.14.178을 통해 응답을 보내고 그 응답을 받은 공유기는 돌려주어야 할 주소 192.168.0.3을 찾아 마침내 응답을 하게 된다. 이러한 일련의 과정을 클라이언트 기반의 NAT라고 한다.
이러한 과정을 통해 우리는 요청에 대한 응답을 받고 외부 호스트와 통신을 할 수 있게 된다.
DNS Server를 통해 특정 주소의 IP Address를 알아낸다고 했는데, 그럼 DNS Server는 어떻게 IP Address를 저장하고 관리할까?
우선, 임의의 서버 호스트가 본인의 IP Address를 www.example.com이라는 주소로 등록하고 싶다고 요청을 한다. 이 요청과 등록의 과정은 아래에서 더 자세히 살펴보자.
그럼 DNS Server랑은 어떻게 통신할까?
당연히 DNS Server도 Server이기 때문에 호스트이고 호스트와 통신을 하려면 주소가 필요하다. 이 DNS Server의 주소는 컴퓨터에 네트워크를 연결하는 순간 해당 컴퓨터에 DNS Server IP가 바로 할당된다. 그래서 모든 컴퓨터의 운영체제는 인터넷이 연결된 순간 DNS Server와 통신이 가능하게 된다.
이건 통신사가 제공하는 DNS Server와 연결되는 것인데 내가 원하는 DNS Server로 바꿀 수도 있다. 이는 Public DNS Server를 이용하면 된다.
그럼 이제 인터넷이 연결된 호스트는 Part 2에서 언급했던 hosts 파일과 연결된 DNS Server를 통해 특정 주소에 대한 IP를 얻어내고 해당 주소를 가지는 호스트와 통신을 하게 된다. 이것이 동작원리이다.
DNS Internal
본 페이지의 개요에서 DNS Server라는 특정 서버와 임의의 호스트가 연결되는 원리를 알아보았는데, 그럼 과연 DNS Server는 단 한대만 존재할까? 아니다. DNS Server는 수십만 대가 있고, 각 서버마다 역할 또한 다르다.
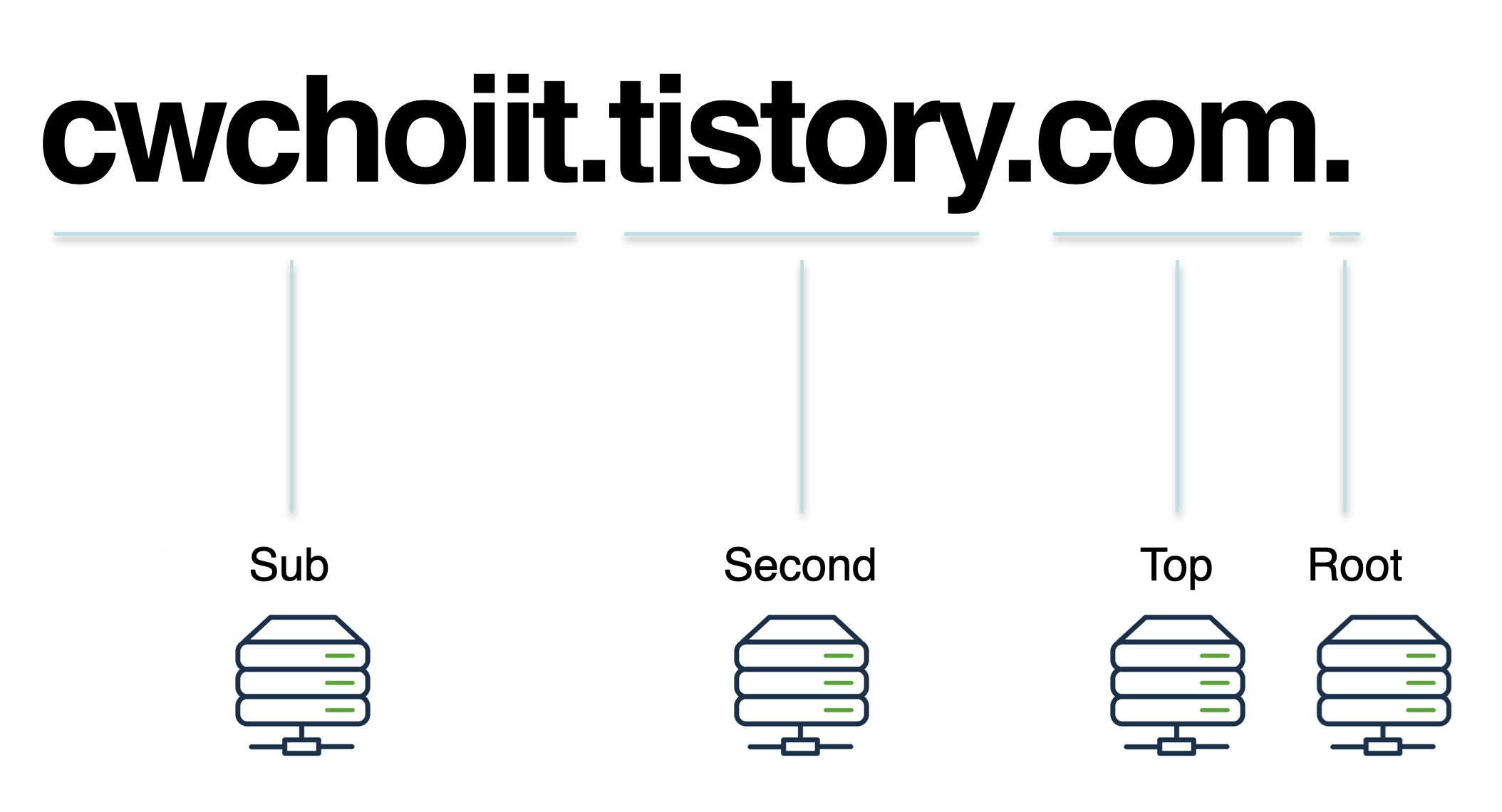
도메인 구조가 생각보다 여러 파트로 나뉜다.
cwchoiit.tistory.com.이라는 주소가 있으면 이 주소가 네 파트로 나뉜다.
위 그림에서 각 영역별로 담당하는 DNS Server가 다 다르다.
그러나 명확한 한 가지는 있다. Root DNS Server는 Top level DNS Server의 리스트를 가지고 있고 Top level DNS Server는 Second DNS Server의 리스트를 가지고 있고 Second level DNS Server는 Sub DNS Server 리스트를 가지고 있고 모든 호스트의 연결된 DNS Server는 최소한 Root DNS Server의 주소는 반드시 알고 있다.
이러한 구조를 알고 있는 상태에서 만약 내가 cwchoiit.tistory.com. 에 접속하고자 한다면 과정은 아래와 같다.
1. 내 컴퓨터(호스트)는 Root DNS Server에게 해당 주소를 물어본다.
2. Root DNS Server는 호스트에게 ". com"이라는 Top level을 관리하는 Top level DNS Server의 IP를 준다.
3. 호스트는 Top level DNS Server에게 해당 주소를 물어본다.
4. Top level DNS Server는 "tistory"라는 Second level을 관리하는 Second level DNS Server의 IP를 준다.
5. 호스트는 Second level DNS Server에게 해당 주소를 물어본다.
6. Second level DNS Server는 "cwchoiit"라는 Sub level을 관리하는 Sub level DNS Server의 IP를 준다.
7. 호스트는 Sub level DNS Server에게 해당 주소를 물어본다.
8. Sub level DNS Server가 cwchoiit.tistory.com. 의 실제 IP 주소를 알려준다.
이러한 세부적인 과정을 거쳐 최종적으로 원하는 IP를 돌려받고 해당 호스트와 통신하게 된다.
도메인 이름 등록 과정과 원리
위 그림을 통해 간단하게 도메인 등록 과정과 원리를 살펴보자. 사실 크게 중요한가 싶긴 하다만(?) 알고 나니 좀 더 기분이 좋아지긴 했다.
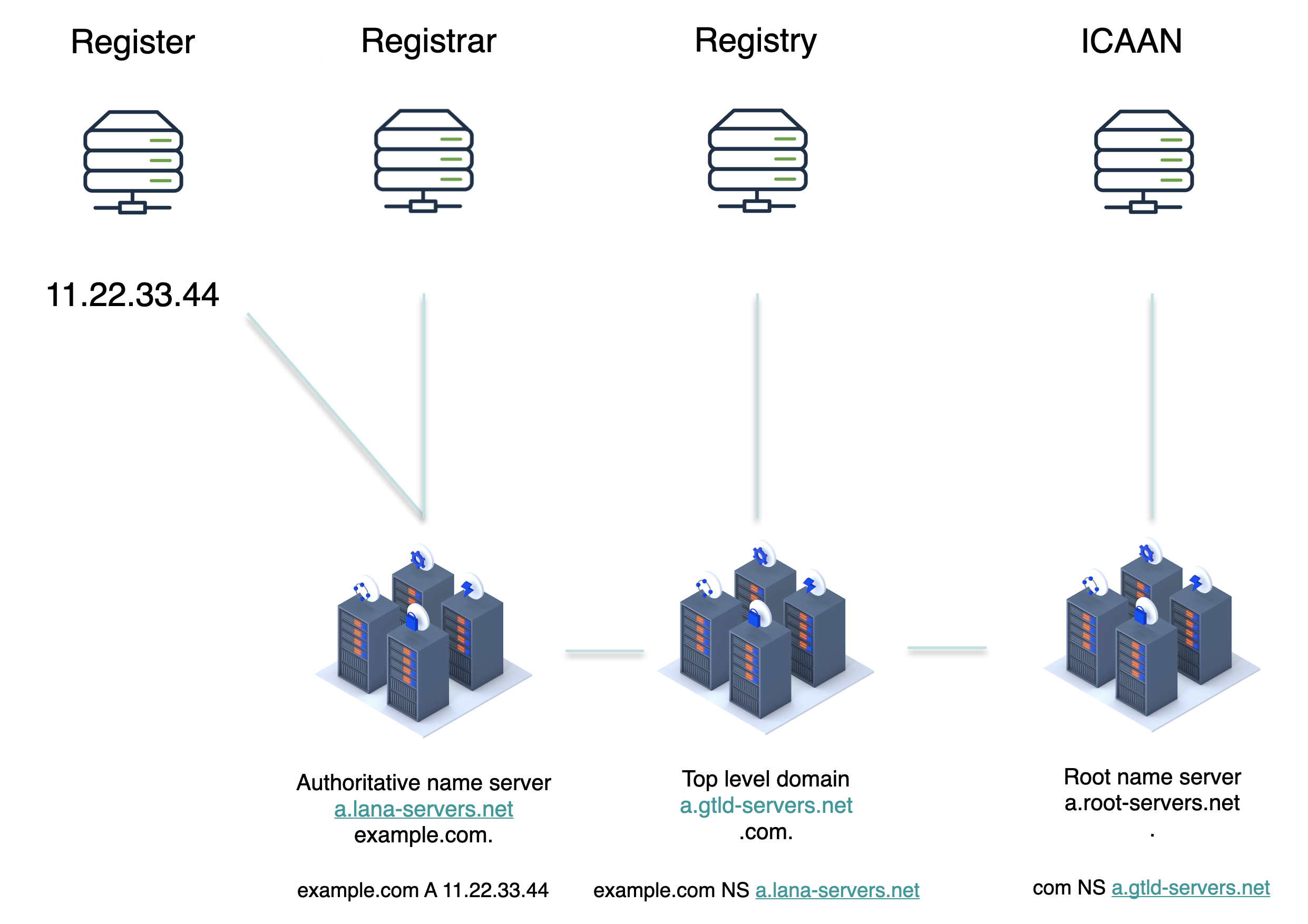
일단 최초에 등록자(Register)가 11.22.33.44라는 IP Address를 example.com이라는 주소로 등록하고 싶다고 가정해 보자.
그럼 등록 대행자(Registrar)에게 (gabia.com 같은) 해당 IP를 알려주어야 한다. 등록 대행자는 자신들이 가지고 있는 DNS Server에 해당 IP를 example.com으로 등록하고 그 정보를 ICANN이라는 기관에 알려준다. 이 기관은 Root DNS Server의 모든 리스트를 가지고 있고 Root DNS Server에게 이렇게 말한다.
"이 example.com이라는 주소를 등록할 건데 너는 Root니까. com을 관리하는 Top level DNS Server에게도 이 사실을 알려줘!"
그럼 ICANN의 Root DNS Server들 중 하나가 Top level DNS Server의 주소를 알려주고 그 Top level DNS Server가 example이라는 Second level domain을 가지는 DNS Server의 주소를 가지게 된다. 그 DNS Server는 바로 등록대행자가 가지고 있는 DNS Server가 된다.
1. 그러니까 Root DNS Server는. com을 관리하는 Top level DNS Server의 주소를 가지게 되고2. .com을 관리하는 Top level DNS Server는 example을 관리하는 Second level DNS Server의 주소를 가지게 되고3. Second level DNS Server는 곧 등록대행자가 가지고 있는 DNS Server인데 이 서버가 example.com의 실제 IP 주소를 가지고 있게 되는 구조다.
이런 식으로 등록을 완료하게 되면 이제 특정 호스트에서 example.com에 접속하기 위해 해당 호스트의 운영체제가 가지고 있는 DNS Server에게 물어본다. 그렇게 물어보면 위 1 - 8까지의 과정을 거쳐 해당 사이트에 접속하게 된다.
A / NS / CNAME Record
위 그림에서 보면 A, NS라는 키워드가 사용되었는데 그 부분을 알아보자.
우선 위 그림에서 example.com A 11.22.33.44example.com NS a.lana-servers.net 이런 한 줄 한 줄이 눈에 보일 것이다.
이런 한 줄을 "레코드"라고 한다.
A는 IP Address를 의미하고 NS는 Name Server를 의미하는데 레코드 타입이 NS인 경우 해당 주소를 저장한 Name Server가 무엇인지 알려주는 레코드가 되는 것이다.
쉽게 말해
example.com A 11.22.33.44라는A 레코드는 example.com의 IP가 11.22.33.44라는 것을 의미한다.
example.com NS a.lana-servers.net이라는NS 레코드는 example.com이라는 주소를 저장한 네임서버가 a.lana-servers.net이라는 것을 의미한다.
Part 1에서 호스트와 호스트가 통신을 하기 위해서는 IP Address를 알아야 한다고 했고, IP Address 알기 위해 도움을 주는 것이 DNS, DNS Server라고 했다. 근데 DNS Server가 아니어도 알아내는 방법이 있다. hosts 파일을 이용하는 것.
반응형
SMALL
hosts file
모든 운영체제에서 기본으로 가지고 있는 파일인 hosts 파일은 특정 IP Address와 특정 도메인 주소를 연결하여 매핑해놓은 파일이다.
예를 들어, 121.138.177.1이라는 IP Address를 www.example.com 으로 매핑했다면 그리고 그 매핑한 파일을 가지고 있는 호스트는 브라우저에 www.example.com을 입력했을 때, DNS Server를 거치지 않고 121.138.177.1이라는 주소로 연결하게 된다.
이게 hosts file의 역할이다. 내 PC에서는 hosts 파일 경로는 다음과 같다. /private/etc/hosts
그리고 이 파일을 실제로 열어보면 다음과 같이 생겼다.
그리고 이 파일의 우선순위가 DNS Server보다 높다. 그렇기에 유저가 브라우저를 통해 어떤 주소를 입력하고 응답받기까지의 과정은 다음과 같다.
1. 유저가 특정 주소를 입력
2. 운영체제는 hosts 파일을 확인
3-1. hosts 파일에 해당 주소와 매핑된 IP Address가 있다면 그 IP Address로 접근
3-2. hosts 파일에 해당 주소와 매핑된 IP Address가 없으면 DNS Server에게 해당 주소의 정보를 요청
그래서 결론은 만약 특정 호스트에서 특정 주소를 입력했을 때, 그 주소 정보가 hosts 파일에 있다면 hosts 파일의 정보를 기반으로 접근하고 그렇지 않으면 DNS Server를 통해 주소를 접근한다.
그러나 이 파일의 한계는 뚜렷하다. 첫 번째 한계는 hosts 파일은 가장 먼저 그 정보를 저장한 호스트에만 적용되는 내용이다. 내가 가진 PC(A)와 다른 누군가가 가진 PC(B)의 hosts 파일 내용은 상이하다. 즉, A와 B가 가리키는 hosts 파일에 적힌 동일한 주소마저도 다른 IP Address를 가질 수 있다.
두 번째 한계는 보안상 매우 취약하다. 만약 내가 hosts 파일에 금융 관련 주소를 입력해서 사용하고 있는데 누군가 그것을 알아내서 hosts 파일을 자기들이 복제해 만든 피싱 사이트로 변경한다고 해도 감쪽같이 속을 수 있다.
그리고 이 호스트와 호스트가 통신하기 위해서는 서로간의 주소가 필요한데 이 주소를 IP Address라고 한다.
이렇게 처음에 IP Address가 세상에 나왔을 때 사람들은 IP Address를 통해 호스트(서버)끼리 통신이 가능해졌기 때문에 만족했지만 얼마 지나지 않아 불만이 생기기 시작했는데 그 불만은 IP Address를 외우기 너무 어렵다는 것이다.
이 불만(문제)를 해결하기 위해 탄생한 것이 DNS(Domain Name System)이다. DNS는 쉽게 IP Address를 사람들이 기억하기 쉽게 이름을 부여한 시스템을 말한다. 예를 들면 www.naver.com 이 주소가 DNS이다.
DNS 얘기를 할 때 빠질 수 없는 것이 DNS Server인데 DNS Server가 하는 역할은 특정 호스트에서 특정 주소(예: www.naver.com)를 입력하면 호스트의 운영체제는 DNS Server에게 해당 주소와 매핑된 IP Address가 무엇인지 물어본다. DNS Server는 해당 주소와 매핑된 IP Address를 돌려주면 그 주소를 통해 호스트와 해당 주소를 가지는 호스트가 통신을 할 수 있게 된다. 이렇듯 중간에서 특정 주소의 IP Address를 저장하고 그 내용을 호스트에게 알려주는 역할을 하는 것이 DNS Server이다.
그리고 이렇게 IP Address와 특정 주소(예: www.naver.com)을 엮은 하나하나를 DNS Record라고 한다.
RDBS를 사용해 개발하던 중에 칼럼 형식으로부터의 자유로움의 필요성을 느끼고 MongoDB를 공부하기 시작했다.
MongoDB와 잘 맞는 Javascript를 사용해 간단한 Blog Service를 구축해 보면서 MongoDB와 친해져 보자.
Getting Started
npm init -y
package.json 파일을 우선 만들고, dependencies를 추가하자.
npm i typescript --save-dev
npm i express --save
이후에 typescript 설정 파일을 생성하기 위해 아래 커맨드를 실행하자.
npx tsc --init
이 커맨드는 tsconfig.json 파일을 작업하고자 하는 프로젝트 경로의 루트에 생성해 주는데, 어떤 식으로 typescript 코드를 javascript 코드로 컴파일할지에 대한 여러 옵션을 지정하고 있다. 언제든지 수정이 가능하지만 기본 옵션으로 우선 진행하자.
Setup Express server
이제 차근차근 하나씩 Express 서버를 구축해 보자. 우선 나는 Typescript를 사용할 거니까, express의 type definition file을 내려받자.
npm i @types/express --save-dev
프로젝트 루트 경로에 src폴더를 만들고 index.ts파일을 하나 생성하자.
src/index.ts
import express from'express';
const app = express();
app.listen(3000, function () {
console.log('server listening on port 3000');
});
Express server는 3000번 포트로 기동 하게끔 설정했고, 실행 후 callback 함수로 간단한 log를 찍어주었다.
일단 서버가 실행이 정상적으로 되는지 확인해 보자.
Node가 typescript 코드를 다이렉트로 실행하지 못하기 때문에 javascript로 컴파일해주어야 한다는 것을 다시 한번 인지하고 이를 도와주는 ts-node라는 패키지를 내려받자. ts-node는 Node로 Typescript를 다이렉트로 실행하게 도와주는 패키지인데 나는 어떤 코드의 변경사항이 생길 때 서버를 재기동하게끔 ts-node-dev를 내려받을 거다. ts-node-dev는 그냥 nodemon과 같은 녀석이라고 생각하면 된다.
npm i ts-node-dev --save-dev
이제 package.json 파일에서 script 부분을 수정하자.
ts-node-dev로 src/index.ts 파일을 실행하게끔 "dev"라는 커맨드를 추가했고, 이제 서버를 실행해 보자.
실행하면 정상적으로 아래 같은 로그가 출력되는 걸 확인할 수 있다.
server listening on port 3000
Connect to MongoDB
이제, MongoDB를 연동해 보자. MongoDB를 연동하기 위해 mongoose라는 패키지를 내려받자.
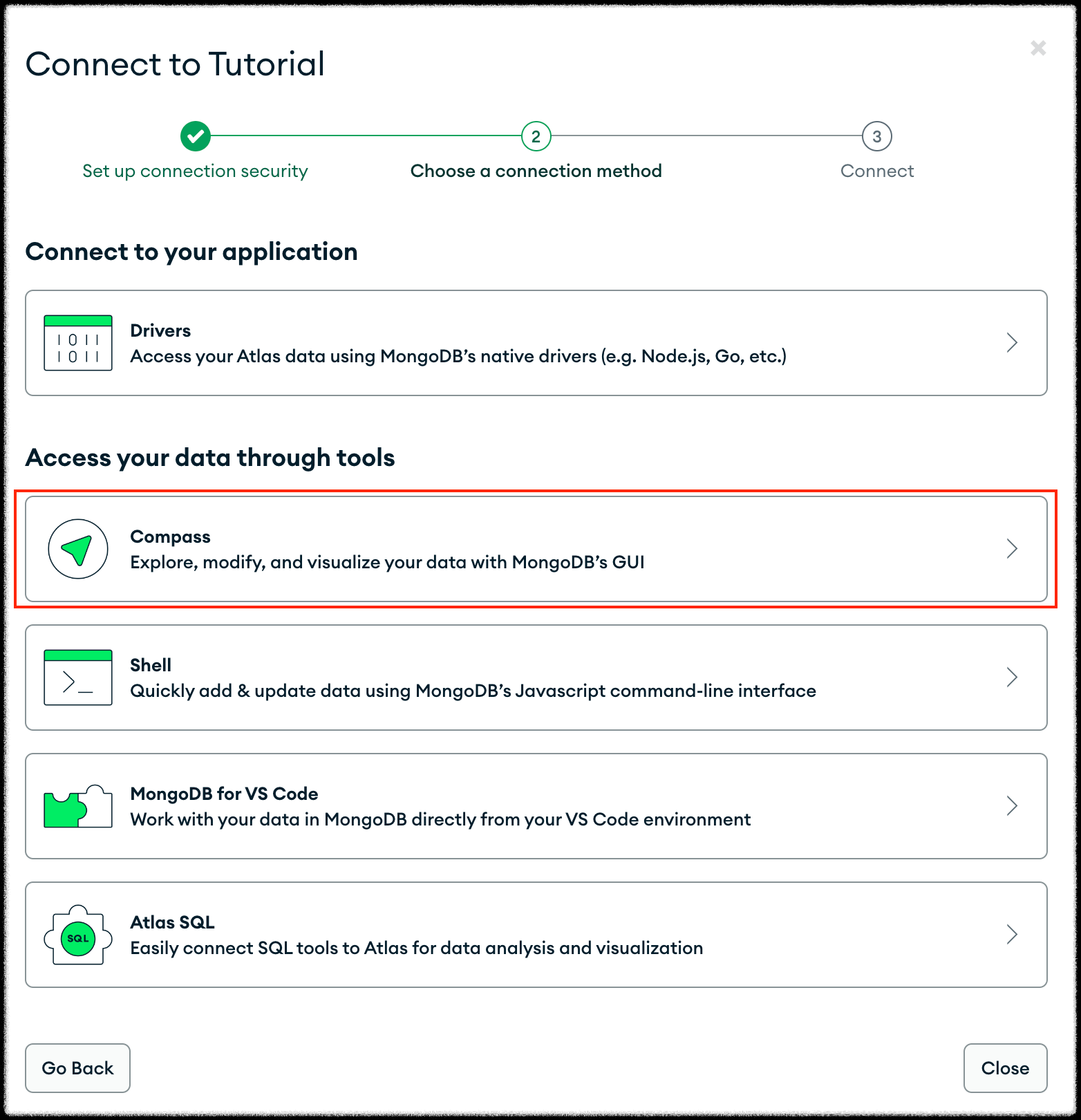
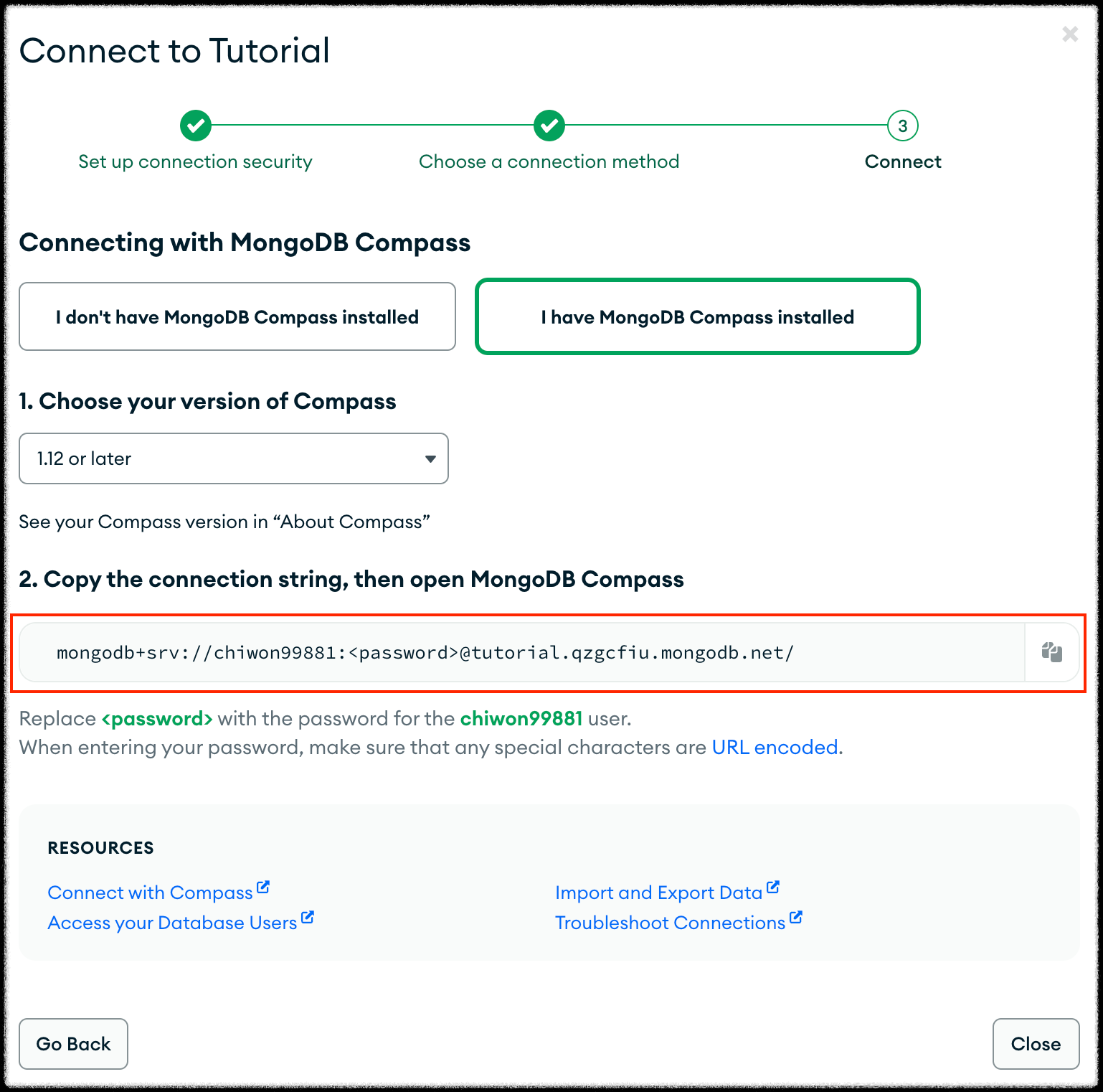
Mongo Atlas에서 데이터베이스 만들고, Connect > Compass를 누르면 나한테 연결할 URI를 알려준다.
이렇게 연결을 하고 나서, 다시 재실행을 해보면 아래와 같은 로그가 찍히는 걸 확인할 수 있다.
MongoDB connected !
server listening on port 3000
그럼 성공적으로 연결은 다 끝난 상태이다. 이제 라우팅 및 API를 작업해 보자.
Setup routes
라우트를 작업하기 앞서, 우선 한 가지 미들웨어를 설정해줘야 하는데 express의 json이라는 녀석이다. 이 녀석은 쉽게 말해 외부의 요청이 들어올 때 전달되는 payload의 데이터가 Json 형식의 데이터가 들어오면 그것을 파싱 해주는 미들웨어라고 생각하면 된다. 즉, Json 데이터를 받아줄 수 있는 미들웨어.
이제 MongoDB에게 알려줄 User Schema를 만든다. 이 유저 스키마 정보는 곧 나의 데이터베이스의 Collection으로 만들어지게 된다.
username에서는 unique: true라는 옵션을 넣어주어서 같은 username을 가지는 유저를 방지하게 하고, timestamp: true라는 옵션을 넣어서 새로운 user document가 생성될 때마다 createdAt 데이터가 자동으로 추가되고 변경 시 updatedAt 정보를 갱신하게끔 만들어 주었다.
이제 mongoose패키지에서 model이라는 모듈을 import 하여 User모델을 mongoDB에게 알려준다. collection이름을 user라고 명시하였는데 이렇게 하면 실제로는 데이터베이스에 users라는 복수명으로 표시되어 만들어진다.
생성한 User model을 export default로 내보내자.
이렇게 만든다고 바로 MongoDB Compass에 collection이 보이지는 않는다. collection에 데이터가 실제로 추가가 되면 그때 비로소 collection이 나타나게 된다. 이를 확인하기 위해 router도 만들고 실제로 API를 구현해서 데이터를 생성해 보자.
router를 만들기 앞서, /src/model/index.ts파일을 만들고 model의 패키지의 모든 모델들을 한 번에 export 하게끔 해보자.
다른 파일에서 model의 특정 파일을 명시하지 않으면 기본적으로 model패키지의 index파일을 찾게 된다. 이를 이용해서 편리하게 export 해보자.
/src/model/index.ts
import User from'./user/user';
export { User };
이제 모델 패키지에 새로운 모델들이 만들어질 때마다 항상 이 파일에서 export 해주면 다른 파일에서 원하는 모델을 불러오고 싶을 때 index.ts파일을 통해 불러올 수 있다. 이는 이후에 새로운 모델이 생성된 후에 더 자세히 알아보자.
이러한 쓰임새는 바로 다음 /src/index.ts 파일에 사용되는 routes 패키지를 import 하는 부분에서 확인할 수 있다.
/src/routes/user/userRoute.ts 파일을 생성하자.
import { Router } from'express';
import mongoose from'mongoose';
import { User } from'../../models';
exportconst userRouter = Router();
// Create user
userRouter.post('/', asyncfunction (req, res) {
try {
const { username, name } = req.body;
if (!username)
return res.status(400).send({ error: 'username is required' });
if (!name || !name.first || !name.last)
return res
.status(400)
.send({ err: 'Both first and last name are required' });
const user = new User(req.body);
await user.save();
return res.send({ success: true, user });
} catch (e: any) {
console.log(e);
return res.status(500).send({ error: e.message });
}
});
위 코드는 새로운 유저를 생성하는 API를 구현한 코드이다. 내가 구현할 유저 관련 API는 생성, 읽기, 수정, 삭제이다.
우선 POST 메서드로 REST API를 구현하고 Path는/users이다.
request의 body를 통해 username, name을 받는다. 이 코드에서는 email, age는 따로 검증하지 않았다.
username이 없으면응답 코드를 400,에러 메시지를 "username is required"로 반환하기로 했고 name이 없거나 name의 first, last값이 없으면 역시응답 코드를 400,에러 메시지를 "Both first and last name are required"로 반환하기로 한다.
위 검증을 모두 통과하면 유저를 생성하고 저장한다.user.save()를 실행하면 MongoDB에 해당 데이터가 저장이 된다.
모든 과정을 마치면, res.send()에 생성된 유저 정보를 넣어 반환한다.
위 코드에서는 "/" 이렇게만 설정되어 있지만 Express app을 실행하는 부분에서 (src/index.ts) users라는 context를 설정해 줄 것이다. 아래 코드를 확인해 보자.
이제 생성 관련 API를 만들었으니 테스트해보자. 테스트를 해보기 위해 Postman을 사용해 보자.
Method는 POST, URL은 http://localhost:3000/users로 설정한 후 아래와 같이 body payload를 설정한 후 Request 해보자.
응답의 결과로 아래와 같은 화면을 돌려받을 수 있다.
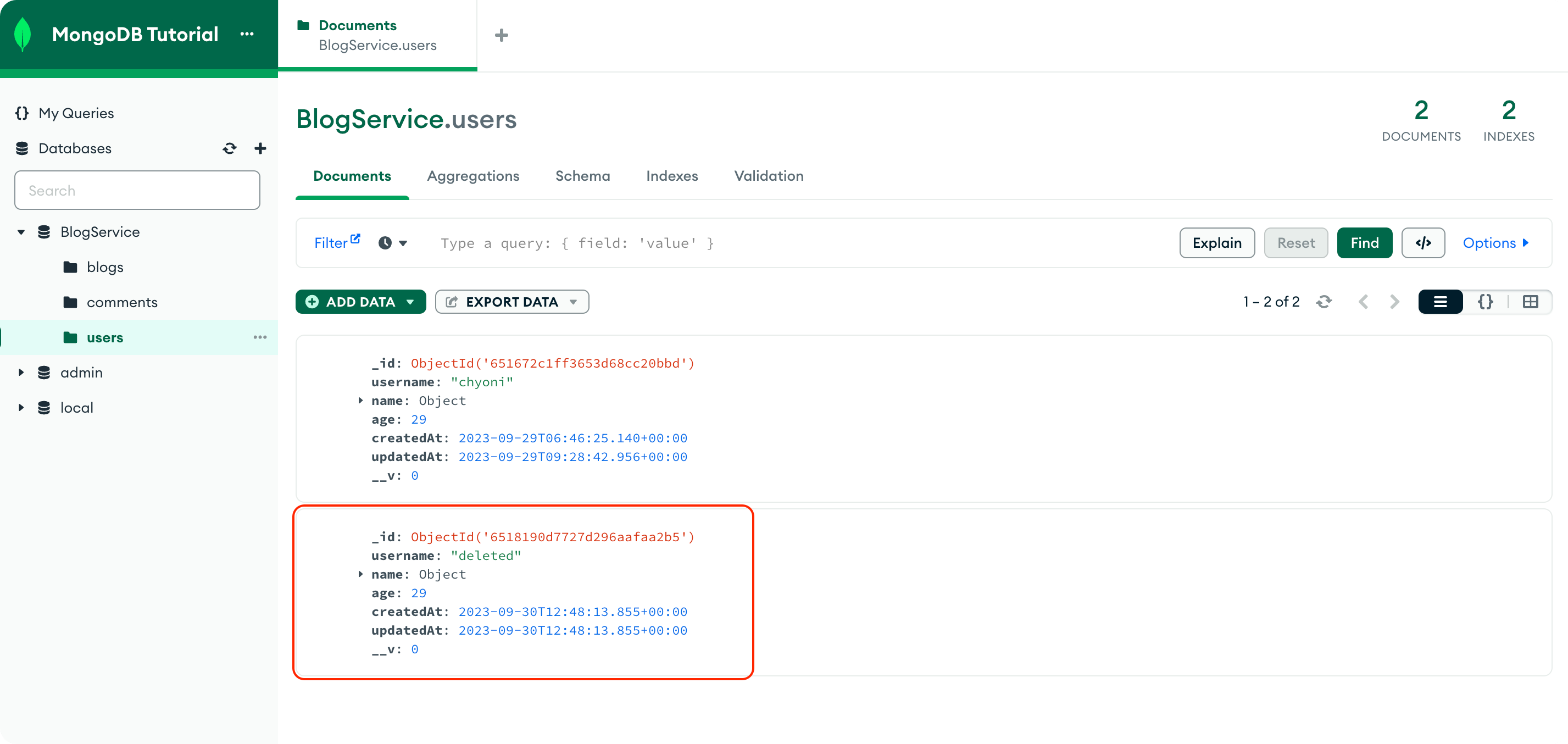
정상적으로 데이터를 만든 API를 통해 주고받았고 데이터베이스에도 해당 데이터가 저장되었는지 확인하기 위해 MongoDB Compass를 실행해서 확인해 보자.
데이터베이스에도 정상적으로 데이터가 저장된 것을 확인할 수 있다. 저 데이터 형식에서 _id는 MongoDB에서 생성해 주는 고유값이다. 해당 id가 곧 RDBS에서 primary key라고 생각할 수 있는데, 우리는 저 key를 통해 각 유저를 조회하는 API도 만들 것이다.
한 가지 더 해보고 넘어갈 것은 또 다른 collection을 만들고 collection 사이의 관계를 맺어보는 것이다.
Blog collection
이제 새로운 collection하나를 더 만들어보자. 이 blog collection은 데이터로 유저 정보도 가지게 된다. 어떤 유저가 이 블로그의 주인인지를 알기 위해.
위 코드에서 확인할 것은 Blog라는 Schema의 데이터 중 user이다. 이렇게 collection끼리 관계를 갖게 할 수 있는데 그러기 위해선 ref라는 옵션을 사용해서 어떤 collection을 가리키는지 알려주어야 한다. User model을 저장할 때 model이름으로 'user'로 저장한 것과 똑같은 값인 'user'를 ref의 value로 설정해 주면 된다. 그리고 또 한 가지 유저의 type으로 mongoose.Types.ObjectId를 받는다. 이 ObjectId는 아까 MongoDB Compass에서 봤던 것처럼 고유값인 _id를 가리킨다.
이제 Blog collection을 생성했으니 연관된 API도 하나만 만들어보자.
/src/routes/blog/blogRoutes.ts
import { Router } from'express';
import { Blog, User } from'../../models';
import mongoose from'mongoose';
exportconst blogRouter = Router();
// Create blog
blogRouter.post('/', async (req, res) => {
try {
const { title, content, isLive, userId } = req.body;
if (!title) return res.status(400).send({ error: 'title is required' });
if (!content) return res.status(400).send({ error: 'content is required' });
if (isLive && typeof isLive !== 'boolean')
return res.status(400).send({ error: 'isLive must be a boolean value' });
if (!mongoose.isValidObjectId(userId))
return res.status(400).send({ error: 'Invalid user id' });
const user = await User.findOne({ _id: userId });
if (!user) return res.status(400).send({ error: 'User does not exist' });
const blog = new Blog({ ...req.body, user });
await blog.save();
return res.status(201).send({ blog });
} catch (e: any) {
console.log(e);
res.status(500).send({ error: e.message });
}
});