이제는 여러 모니터링 툴을 이용해서 현재 애플리케이션의 상태와 정보를 알아보자.
근데 그 전에 원래 사용하던 모니터링 툴이 있는데 모니터링 툴을 교체한다고 하면 어떻게 될까?
예를 들어, 기존에 사용하던 모니터링 툴이 JMX 모니터링 툴이었다고 해보자. 그럼 이 모니터링 툴에 지표를 전달하기 위해 JMX API를 사용해서 데이터를 전달하는데 중간에 프로메테우스를 사용한다고 하면 원래라면 도구가 다르니 전달하는 방식도 다르고 그럼 API도 교체해야 할 것이다. 그럼 모니터링 툴을 바꿨을뿐인데 애플리케이션에 수정이 일어난다.
이런 불편한 상황을 해결하기 위해 나타난 라이브러리가 마이크로미터(Micrometer)이다.
마이크로미터는 모니터링 툴에 전달하는 지표를 추상화해놓은 라이브러리이다. 그러니까 이 추상화가 이렇게 중요하다.
코드에서도 인터페이스와 그 인터페이스를 구현한 구현체가 아무리 많아지고 사용하는 기술이 바뀌어도 의존하고 있는 것이 인터페이스 하나 뿐이라면 기술이 바뀌어도 클라이언트 코드에는 수정이 필요없어진다. 마찬가지로 이 마이크로미터를 사용하면 모니터링 툴이 바뀌든 두개를 사용하든 상관없이 같은 API를 사용해서 지표를 전달할 수 있다.
그럼, 모니터링 툴을 사용하기 전에 어떤 지표가 있는지 확인해보자. 이 지표도 역시 스프링 부트의 액츄에이터가 우리를 위해 만들어준다.
액츄에이터를 활성화 시키는 내용은 바로 이 전 포스팅에 있으니 참고하고 이미 활성화되어 있다고 가정하고 시작해보자.
다음 URL에 접속해보자.
`http://yourbaseURL/actuator/metrics`여기에 접속하면 스프링 부트가 우릴 위해 만들어주는 여러가지 지표가 있다.
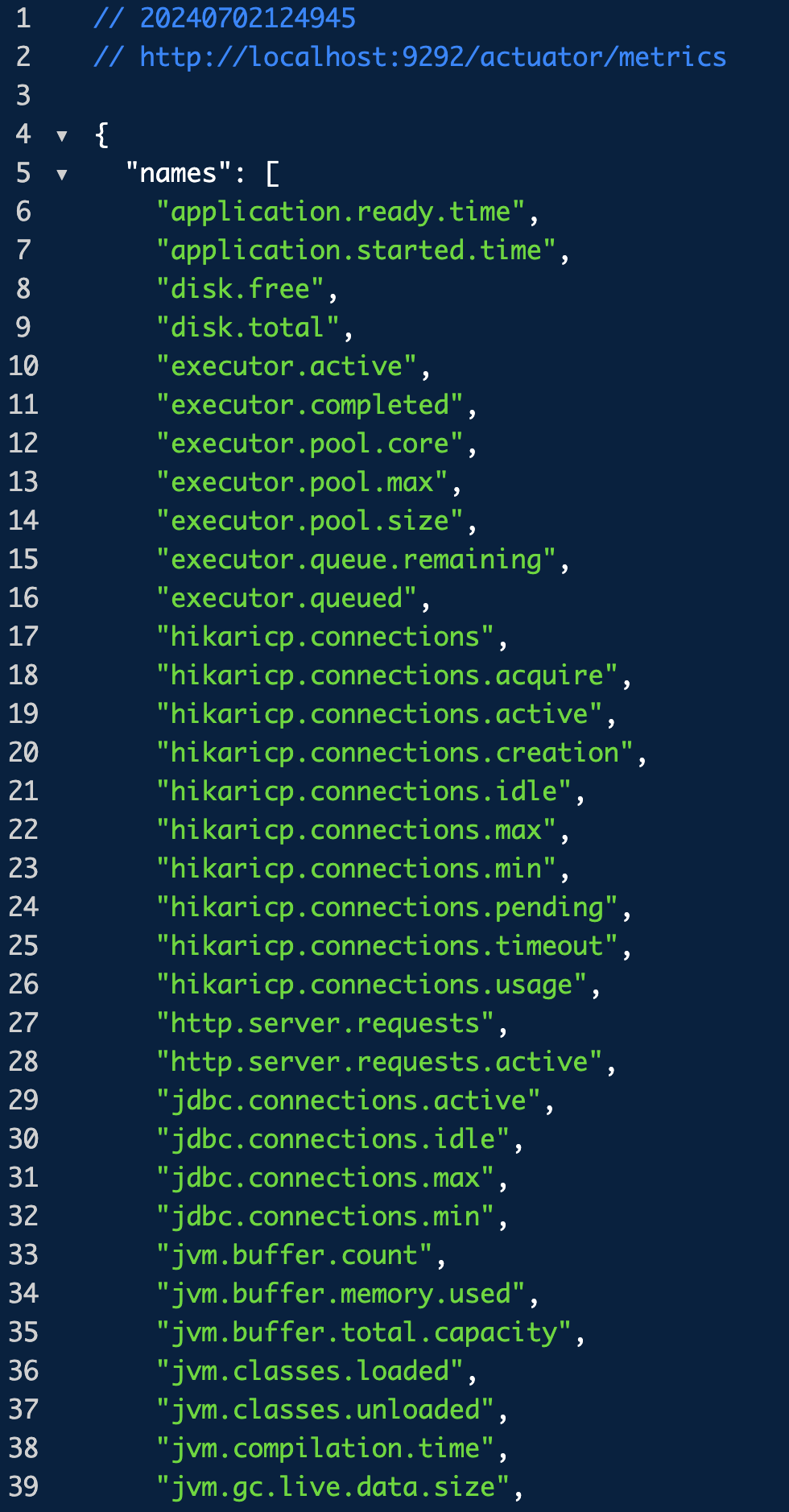
보면 disk.free, disk.total, http.server.requests 등 여러 지표들이 있다.
그럼 이 여러 지표들 중 하나를 선택해서 더 자세히 볼 수 있는데 그 방법은 위 URL에 지표까지 넣어주는 것이다.
`http://yourbaseURL/actuator/metrics/jvm.memory.used`이런 URL로 접속해보자. 이는 JVM에서 사용하고 있는 메모리 양을 보여준다.

그 중에 `tag` 속성이 있는데 이는 특정 태그를 사용해서 더 자세히 확인할 수 있는 기능이다.
예를 들면, `area`라는 태그에 값들이 `heap`, `nonheap`이 있다. 이 태그를 이용하면 heap 영역을 사용하는 JVM 메모리양을 볼 수 있게 된다. 그래서 다음 URL로 접속해보자.
http://localhost:9292/actuator/metrics/jvm.memory.used?tag=area:heap이 URL로 접속하면, `heap` 영역을 사용하고 있는 JVM 메모리양을 확인할 수 있다.
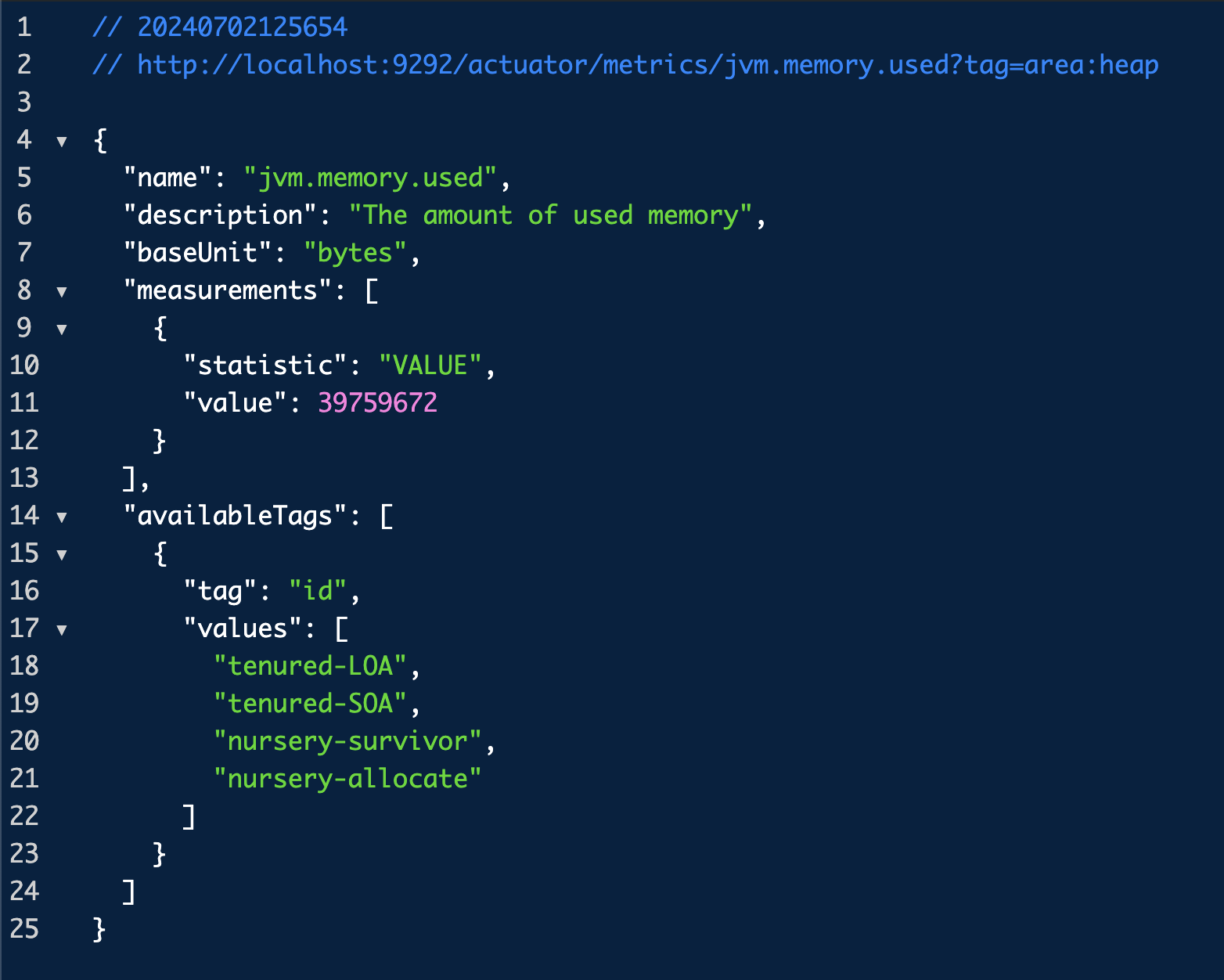
이렇게 태그를 사용해서 더 자세한 지표를 확인할 수가 있게 된다. 한가지 더 봐보자.
이번엔 다음 URL에 접속해보자.
http://localhost:9292/actuator/metrics/http.server.requests이건 이제 어떤 `path`로 요청이 들어오고 총 요청 수, 가장 오래걸린 시간 등 요청과 응답을 기록한 메트릭이다.
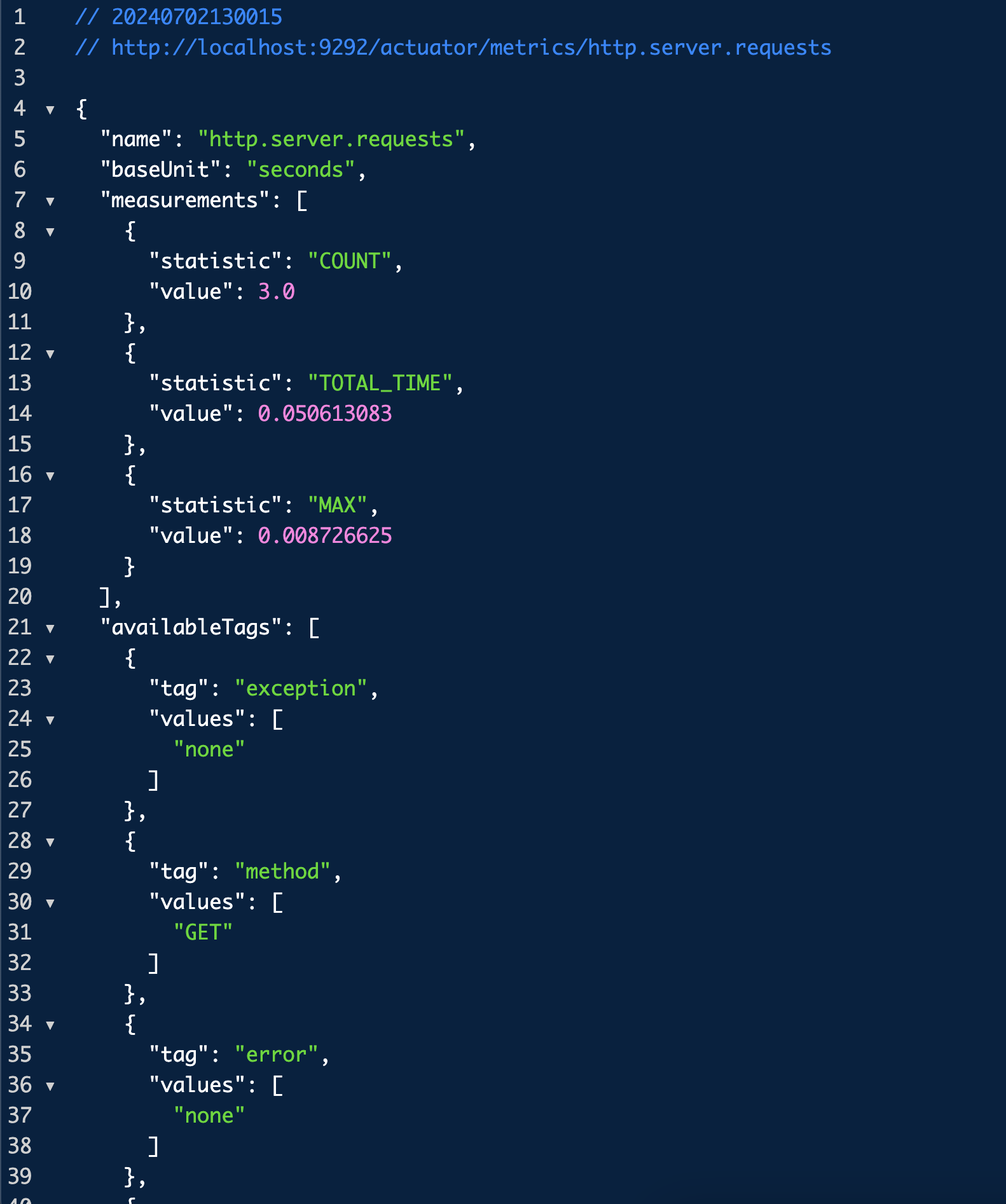
총 요청은 3번, 총 소요시간은 0.05초, 가장 오래 걸린 응답은 0.008초 이런 데이터가 보여진다. 그리고 또한 여기에도 여러 태그가 있는데 한번 태그를 이용해 다음 URL에 접속해보자.
http://localhost:9292/actuator/metrics/http.server.requests?tag=uri:/log&tag=status:200
이건 URI가 `/log`이고 응답 코드가 200인 요청에 대해서만 필터링한 메트릭을 보여주는 URL이다.
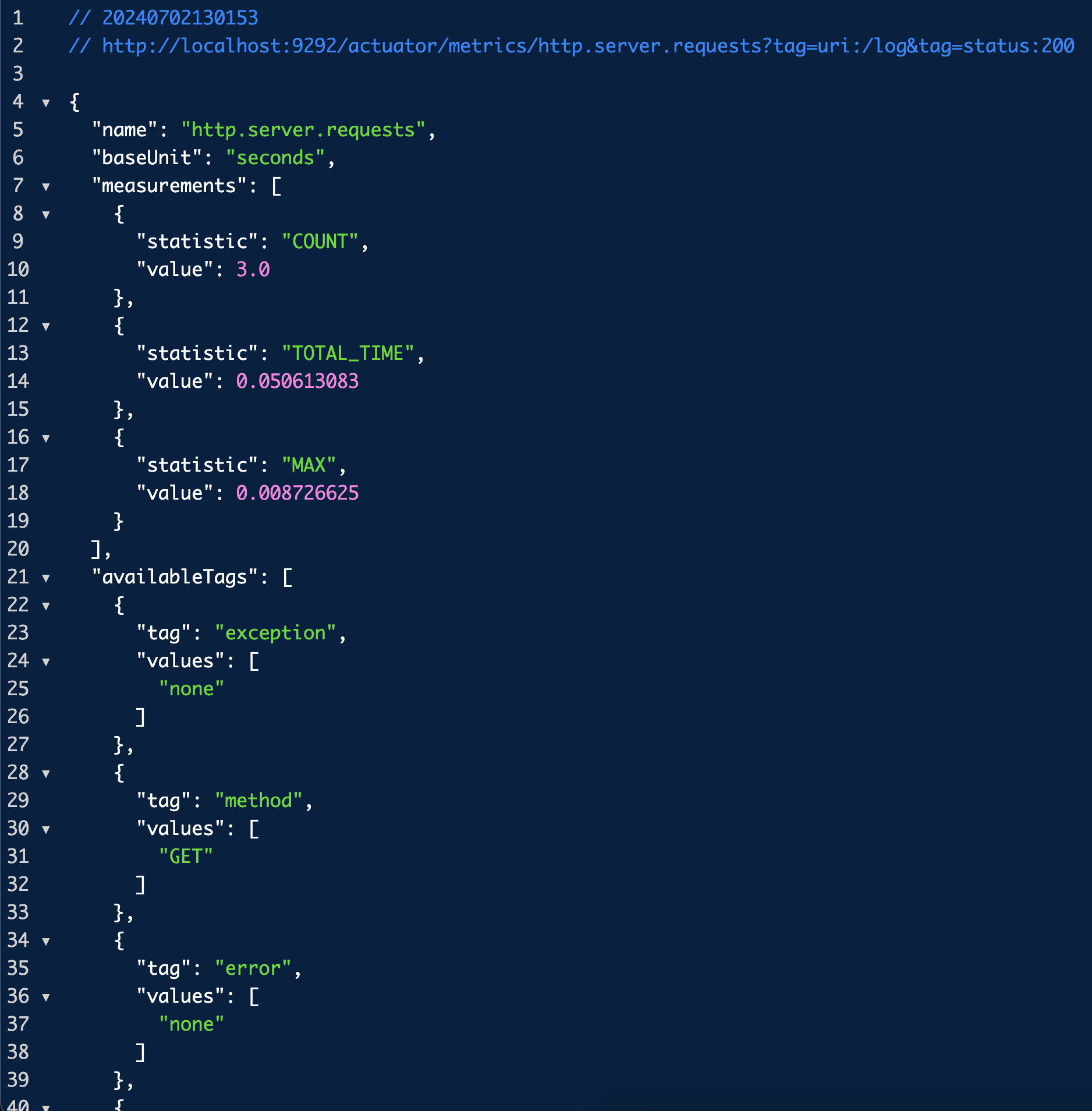
이렇게 액츄에이터는 여러 모니터링을 위한 지표들을 제공한다. 이 지표들을 이제 모니터링 툴과 연동해서 사용할 수 있어보인다.
그럼 어떤 지표들이 있는지 조금 더 자세하게 알아보자.
마이크로미터와 액츄에이터가 기본으로 제공하는 다양한 메트릭을 확인해보자.
- JVM 메트릭
- 시스템 메트릭
- 애플리케이션 시작 메트릭
- 스프링 MVC 메트릭
- 톰캣 메트릭
- 데이터 소스 메트릭
- 로그 메트릭
- 기타 수 많은 메트릭과 사용자가 직접 정의하는 메트릭
JVM 메트릭
JVM 관련 메트릭을 제공한다. `jvm.`으로 시작한다.

- 메모리 및 버퍼 풀 세부 정보
- 가비지 수집 관련 통계
- 스레드 활용
- 로드 및 언로드된 클래스 수
- JVM 버전 정보
- JIT 컴파일 시간
시스템 메트릭
시스템 메트릭을 제공한다. `system.`, `process.`, `disk.`으로 시작한다.
- CPU 지표
- 파일 디스크립터 메트릭
- 가동 시간 메트릭
- 사용 가능한 디스크 공간
애플리케이션 시작 메트릭
애플리케이션 시작 시간 메트릭을 제공한다.
- application.started.time: 애플리케이션을 시작하는데 걸리는 시간
- application.ready.time: 애플리케이션이 요청을 처리할 준비가 되는데 걸리는 시간
스프링은 내부에 여러 초기화 단계가 있고 각 단계별로 내부에서 애플리케이션 이벤트를 발행한다.
- ApplicationStartedEvent: 스프링 컨테이너가 완전히 실행된 상태이다. 이후에 커맨드 라인 러너가 호출된다.
- ApplicationReadyEvent: 커맨드 라인 러너가 실행된 이후에 호출된다.
스프링 MVC 메트릭
스프링 MVC 컨트롤러가 처리하는 모든 요청을 다룬다. `http.server.requests`
`tag`를 이용해서 다음 정보를 분류해서 확인할 수 있다.
- uri: 요청 URI
- method: GET, POST와 같은 HTTP 메서드
- status: 200, 400, 500 같은 HTTP Status 코드
- exception: 예외
- outcome: 상태 코드를 그룹으로 모아서 확인 (1xx: INFORMATIONAL, 2xx: SUCCESS, 3xx: REDIRECTION, 4xx: CLIENT_ERROR, 5xx: SERVER_ERROR)
데이터소스 메트릭
DataSource, 커넥션 풀에 관한 메트릭을 확인할 수 있다. `jdbc.connections.`로 시작한다.
최대 커넥션, 최소 커넥션, 활성 커넥션, 대기 커넥션 수 등을 확인할 수 있다.
히카리 커넥션 풀을 사용하면 `hikaricp.`를 통해 히카리 커넥션 풀의 자세한 메트릭을 확인할 수 있다.
로그 메트릭
logback.events: logback 로그에 대한 메트릭을 확인할 수 있다.
trace, debug, info, warn, error 각각의 로그 레벨에 따른 로그 수를 확인할 수 있다.
예를 들어서 `error` 로그 수가 급격히 높아진다면 위험한 신호로 받아들일 수 있다.
톰캣 메트릭
톰캣 메트릭은 `tomcat.`으로 시작한다. 톰캣 메트릭을 모두 사용하려면 다음 옵션을 켜야한다. (옵션을 켜지 않으면 `tomcat.session.`관련 정보만 노출된다.
application.yml
server:
tomcat:
mbeanregistry:
enabled: true이 옵션을 키면 다음과 같이 `tomcat.session.`외에도 `tomcat.xxx.` 메트릭도 제공이 된다.
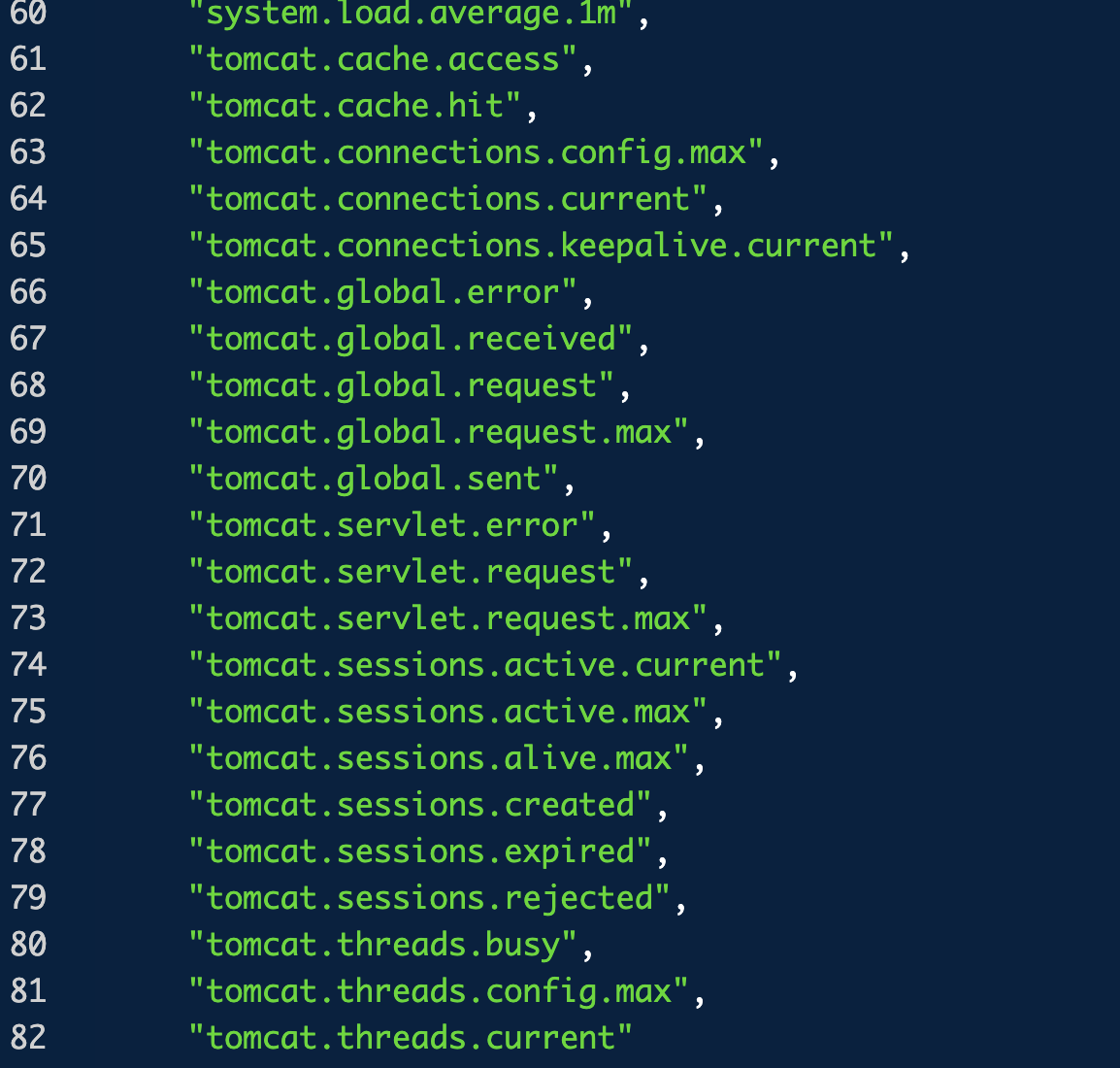
예를 들어, `tomcat.threads.config.max` 메트릭은 톰캣이 제공하는 쓰레드의 최대 개수를 보여준다. 그리고 현재 사용중인 쓰레드 수는 `tomcat.threads.current`로 확인할 수 있다.
기타 메트릭
- HTTP 클라이언트 메트릭(RestTemplate, WebClient)
- 캐시 메트릭
- 작업 실행과 스케쥴 메트릭
- 스프링 데이터 레포지토리 메트릭
- 몽고DB 메트릭
- 레디스 메트릭
사용자 정의 메트릭
사용자가 직접 메트릭을 정의할 수도 있다. 예를 들어서 주문수, 취소수를 메트릭으로 만들 수 있다.
사용자 정의 메트릭을 만들기 위해서는 마이크로미터의 사용법을 먼저 이해해야 한다. 이 부분은 뒤에서 다룬다.
중간 정리
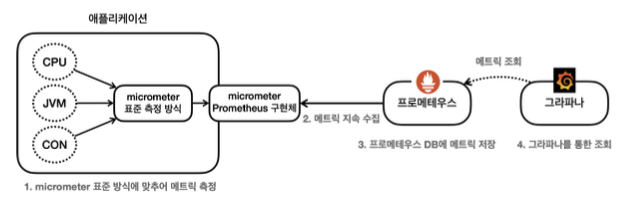
액츄에이터를 통해서 수많은 메트릭이 자동으로 만들어지는 것을 확인했다. 그런데 이러한 메트릭들을 어딘가에 지속해서 보관해야 과거의 데이터들도 확인할 수 있을것이다. 따라서 메트릭을 지속적으로 수집하고 보관할 데이터베이스가 필요하다. 그리고 이러한 메트릭들을 그래프를 통해서 한눈에 쉽게 확인할 수 있는 대시보드도 필요하다.
메트릭의 데이터베이스: 프로메테우스
애플리케이션에서 발생한 메트릭을 그 순간만 확인하는 것이 아니라 과거 이력까지 함께 확인하려면 메트릭을 보관하는 DB가 필요하다.
이렇게 하려면 어디선가 메트릭을 지속해서 수집하고 DB에 저장해야 한다. 프로메테우스가 바로 이런 역할을 담당한다.
그럼 그라파나는?
프로메테우스가 DB라고 하면, 이 DB에 있는 데이터를 불러서 사용자가 보기 편하게 보여주는 대시보드가 필요한데 그라파나는 매우 유연하게 데이터를 그래프로 보여주는 툴이다. 수 많은 그래프를 제공하고 프로메테우스를 포함한 다양한 데이터소스를 지원한다.
어떤 흐름으로 데이터를 보관하고 대시보드에 보여주는지는 다음과 같다.
- 스프링 부트 액츄에이터와 마이크로미터를 사용하면 수 많은 메트릭을 자동으로 생성한다.
- 마이크로미터 프로메테우스 구현체는 프로메테우스가 읽을 수 있는 포맷으로 메트릭을 생성한다.
- 프로메테우스는 이렇게 만들어진 메트릭을 지속해서 수집한다.
- 프로메테우스는 수집한 메트릭을 내부 DB에 저장한다.
- 사용자는 그라파나 대시보드 툴을 통해 그래프로 편리하게 메트릭을 조회한다. 이때 필요한 데이터는 프로메테우스를 통해서 조회한다.
그럼 이제 프로메테우스를 설치해야 한다. 아래 링크에서 설치하자.
Download | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
설치하면 실행해보면 되는데 MacOS 유저 기준으로 설명한다. 실행을 최초에 하면 이러한 화면이 보인다.

그래서 System Settings > Privacy & Security > Open Anyway 버튼을 클릭해주자.
실행이 잘 된다면 다음과 같은 화면이 보여야한다.
프로메테우스는 기본 포트가 9090이다. 그래서 localhost:9090으로 가보면 이런 화면이 뜨면 된다.
그럼 설치는 정상적으로 완료!
프로메테우스 - 애플리케이션 설정
프로메테우스는 메트릭을 수집하고 보관하는 DB이다. 프로메테우스가 우리 애플리케이션의 메트릭을 수집하도록 연동해보자.
여기에는 2가지 작업이 필요하다.
- 애플리케이션 설정: 프로메테우스가 애플리케이션의 메트릭을 가져갈 수 있도록 애플리케이션에서 프로메테우스 포맷에 맞추어 메트릭 만들기
- 프로메테우스 설정: 프로메테우스가 우리 애플리케이션의 메트릭을 주기적으로 수집하도록 설정
애플리케이션 설정
프로메테우스가 애플리케이션의 메트릭을 가져가려면 프로메테우스가 사용하는 포맷에 맞추어 메트릭을 만들어야 한다.
참고로 프로메테우스는 `/actuator/metrics` 에서 보았던 JSON 포맷은 이해하지 못한다.
어? 그럼 어떻게 하죠?!
걱정할 필요 없다. 마이크로미터가 이런 부분을 모두 해결해준다.
각각의 메트릭들은 내부에서 마이크로미터 표준 방식으로 측정되고 있다. 따라서 어떤 구현체를 사용할지 지정만 해주면 된다.
build.gradle
implementation 'io.micrometer:micrometer-registry-prometheus'- 마이크로미터 프로메테우스 구현 라이브러리를 추가한다.
- 이렇게 하면 스프링 부트와 액츄에이터가 자동으로 마이크로미터 프로메테우스 구현체를 등록해서 동작하도록 설정해준다.
- 액츄에이터에 프로메테우스 메트릭 수집 엔드포인트가 자동으로 추가된다.
- `/actuator/prometheus`
들어가보면 다음과 같은 화면이 보일것이다.
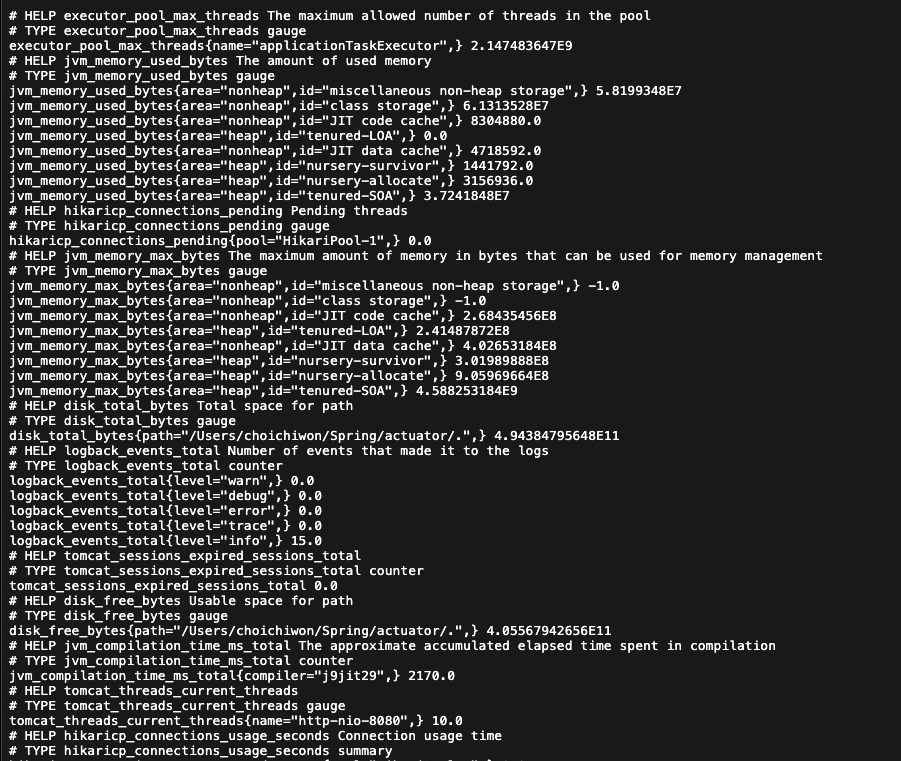
프로메테우스 전용 포맷이라고 보면 된다. 보면 알겠지만 액츄에이터가 제공하는 어떤 메트릭들이 보인다. 그 데이터들을 프로메테우스가 이해할 수 있는 데이터로 변환해준 거라고 보면 된다. 조금 더 자세히 포맷의 차이를 이해해보자면,
- jvm.info -> jvm_info: 프로메테우스는 `.` 대신 `_` 포맷을 사용한다.
- logback.events -> logback_events_total: 로그 수 처럼 지속해서 숫자가 증가하는 메트릭을 카운터라고 하는데 프로메테우스는 카운터 메트릭의 마지막에는 관례상 _total을 붙인다.
- http.server.requests: 이 메트릭은 내부에 요청수, 시간 합, 최대 시간 정보를 가지고 있었다. 프로메테우스에서는 다음 3가지로 분리가 된다.
- http_server_requests_seconds_count: 요청 수
- http_server_requests_seconds_sum: 시간 합 (요청수의 시간을 합함)
- http_server_requests_seconds_max: 최대 시간 (가장 오래걸린 요청 수)
참고로, 이 http.server.requests의 MAX값은 과거 모두 통틀어서의 시간이 아니라, 최근 한 2-3분 정도 중에 가장 오래걸린 요청 수를 기록한다. 이건 스프링 부트 액츄에이터가 그렇게 정해놓은 것이다.
프로메테우스 - 수집 설정
위에서 애플리케이션 설정과 프로메테우스 설정 두 가지가 필요하다고 했다. 이제 프로메테우스 설정을 해보자.
프로메테우스가 액츄에이터의 `/actuator/prometheus`를 호출해서 메트릭을 주기적으로 수집하도록 설정해보자.
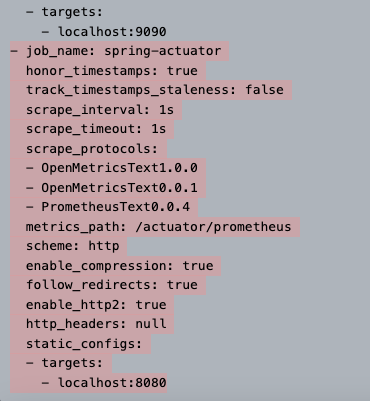
프로메테우스를 설치했으면 그 폴더에 있는 prometheus.yml 파일을 수정해야 한다.
prometheus.yml

위 사진처럼 빨간 네모 박스를 추가해주면 된다. 참고로, 만약 `/acutator`의 포트를 변경했다면 그 포트로 - targets을 설정해야 한다.
job_name은 원하는 이름을 넣어주면 되고, metric_path는 스프링 부트의 액츄에이터가 제공해주는 프로메테우스 URL, scrape_interval은 1초로 설정했다.
주의! 이 1초라는 시간은 너무 짧을수도 있다. 보통 운영에서는 10s ~ 1m 내외로 설정하고 기본값은 1m이다.
그리고 한 가지가 기본으로 있었는데 그건 프로메테우스가 본인이 본인의 데이터를 스크랩하고 있는것이다. 그래서 신경 안써도 된다.
그리고, 이 .yml 파일이 2칸 띄어쓰기가 중요한데, 이 간격이 안 맞으면 프로메테우스가 실행이 안될수도 있다. 그래서 이 부분을 주의하자.
이렇게 설정을 마치고 다시 실행해줘야 한다. 다시 실행한 후 `localhost:9090`으로 들어가보자.

Status > Configuration 으로 들어가보자. 들어가보면, 우리가 설정한 job이 있어야 한다.
그리고 Status > Targets 으로 들어가도 우리의 Target이 있어야 한다.
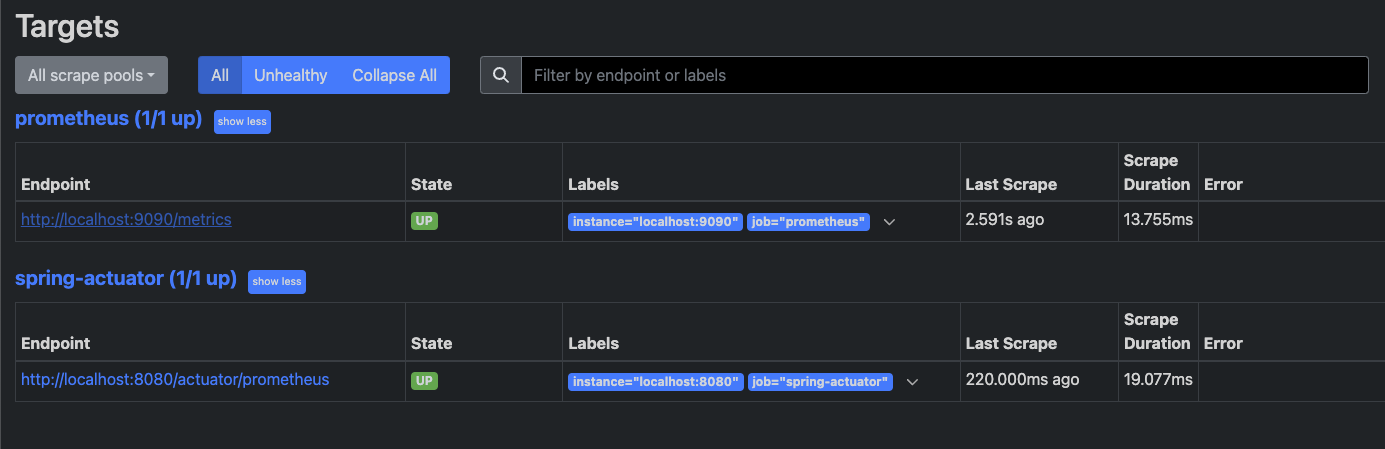
Targets 패널에 우리의 Job이 UP 상태라면 정상적으로 연동되어 데이터를 수집중에 있다는 의미가 된다.
그럼 연동이 끝났으니 실제로 데이터를 수집하고 있는지 확인해보자.
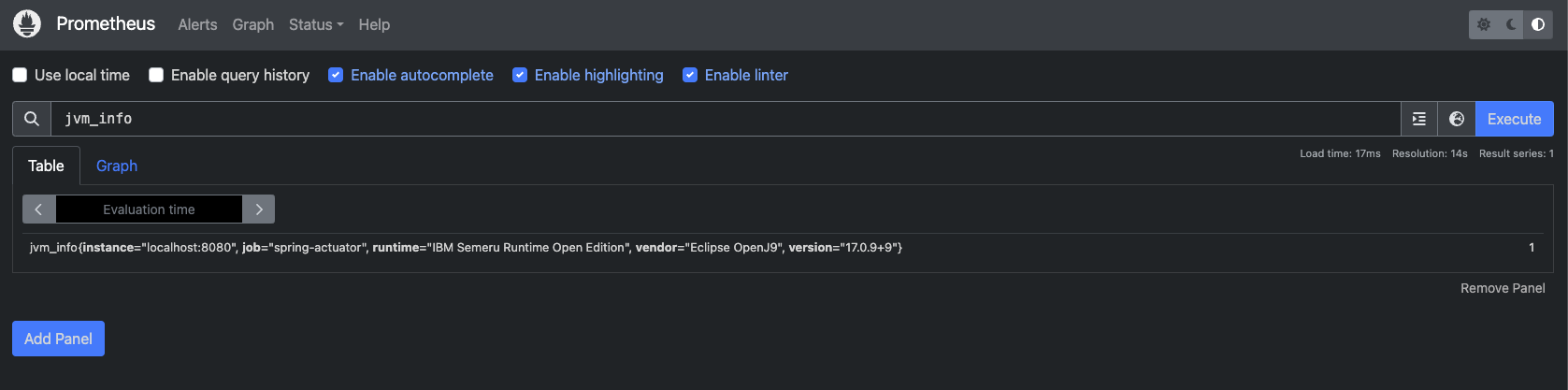
메인 화면에서 `jvm_info`를 검색해보면 위 사진과 같이 수집된 데이터가 보여지면 된다.
프로메테우스 - 기본 기능
이제 설정이 다 끝났으니 기본으로 많이 사용되는 기능에 대해 알아보자.
검색창에 `http_server_requests_seconds_count`를 입력하고 실행해보자.
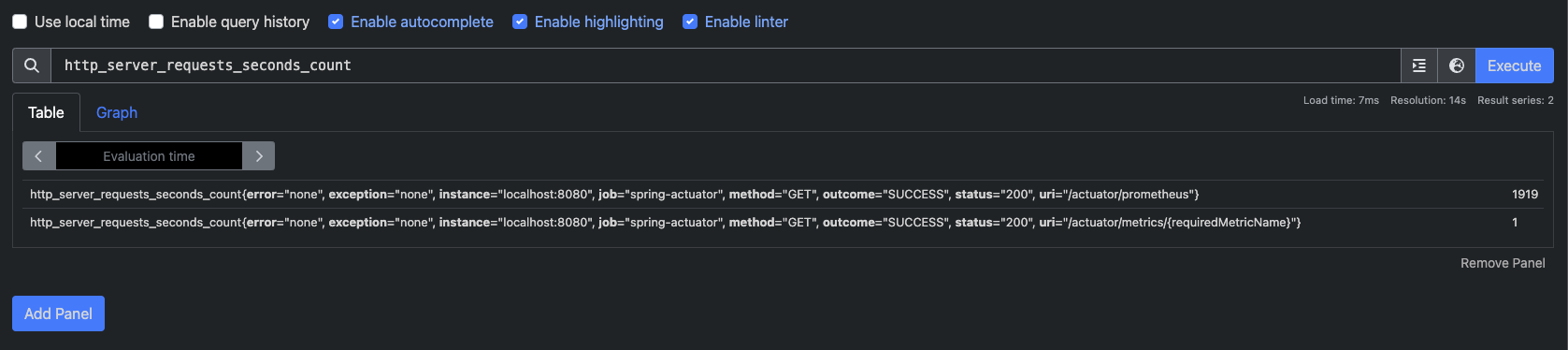
- 태그, 레이블: 위 결과에서 `error`, `exception`, `instance`, `job`, `method`, `outcome`, `status`, `uri`는 각각의 메트릭 정보를 구분해서 사용하기 위한 태그이다. 마이크로미터는 이를 태그라고 하고 프로메테우스는 레이블이라고 한다.
- 숫자: 끝에 마지막에 보면 1919, 1 이런 값이 보인다. 이게 바로 해당 메트릭의 값이다.
기본 기능
- Table: Evaluation time을 수정해서 과거 시간 조회 가능
- Graph: 메트릭을 그래프로 조회 가능
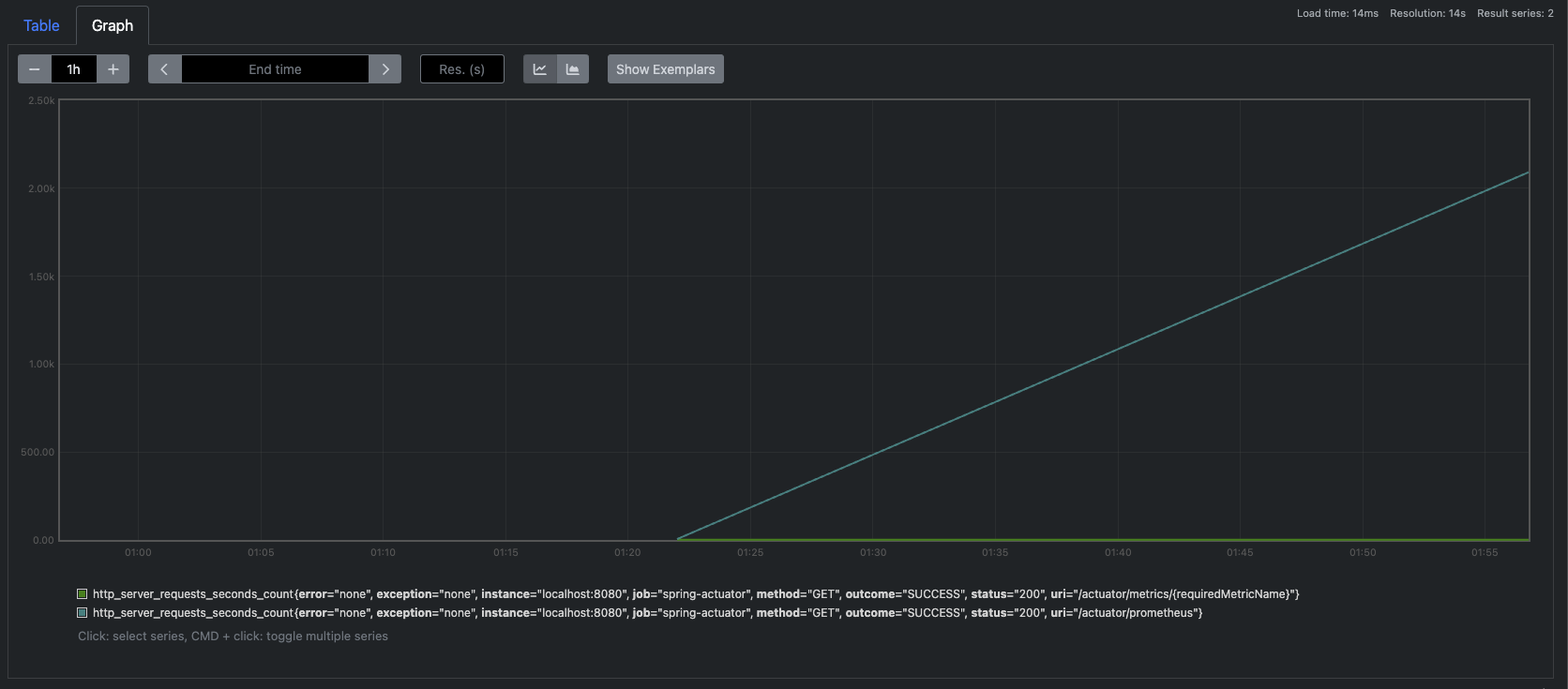
필터
레이블을 기준으로 필터를 사용할 수 있다. 필터는 중괄호 `{}`를 사용한다.
예)
- uri=/log, method=GET 조건으로 필터
- http_server_requests_seconds_count{uri="/log", method="GET"}
- `/actuator/prometheus`는 제외한 조건으로 필터
- http_server_requests_seconds_count{uri!="/actuator/prometheus"}
- method가 GET, POST인 경우를 포함해서 필터
- http_server_requests_seconds_count{method=~"GET|POST"}
- `/actuator`로 시작하는 uri는 제외한 조건으로 필터
- http_server_requests_seconds_count{uri!~"/actuator.*"}
sum
값의 합계를 구한다.
예) sum(http_server_requests_seconds_count)
sum by
SQL의 group by 기능과 유사하다.
예) sum by(method, status)(http_server_requests_seconds_count)
count
메트릭 자체의 수 카운트
예) count(http_server_requests_seconds_count)
topk
상위 3개 메트릭 조회
예) topk(3, http_server_requests_seconds_count)
오프셋 수정자
현재를 기준으로 특정 과거 시점의 데이터를 반환한다.
예) http_server_requests_seconds_count offset 10m
범위 벡터 선택기
마지막에 [1m], [60s] 와 같이 표현한다. 지난 1분간의 모든 기록값을 선택한다.
예) http_server_requests_seconds_count[1m]
참고로 범위 벡터 선택기는 차트에 바로 표현할 수 없다. 데이터로는 확인할 수 있다. 범위 벡터 선택의 결과를 차트에 표현하기 위해서는 약간의 가공이 필요한데, 조금 뒤에 설명하는 상대적인 증가 확인 방법을 참고하자.
프로메테우스 - 게이지와 카운터
메트릭은 크게 보면 게이지와 카운터라는 2가지로 분류할 수 있다.
게이지(Gauge)
- 임의로 오르내릴 수 있는 값
- 예) CPU 사용량, 메모리 사용량, 사용중인 커넥션
카운터(Counter)
- 단순하게 증가하는 단일 누적 값
- 예) HTTP 요청 수, 로그 발생 수
쉽게 이야기해서 게이지는 오르락 내리락 하는 값이고, 카운터는 특정 이벤트가 발생할 때 마다 그 수를 계속 누적하는 값이다.
게이지 그래프의 예시를 보자.
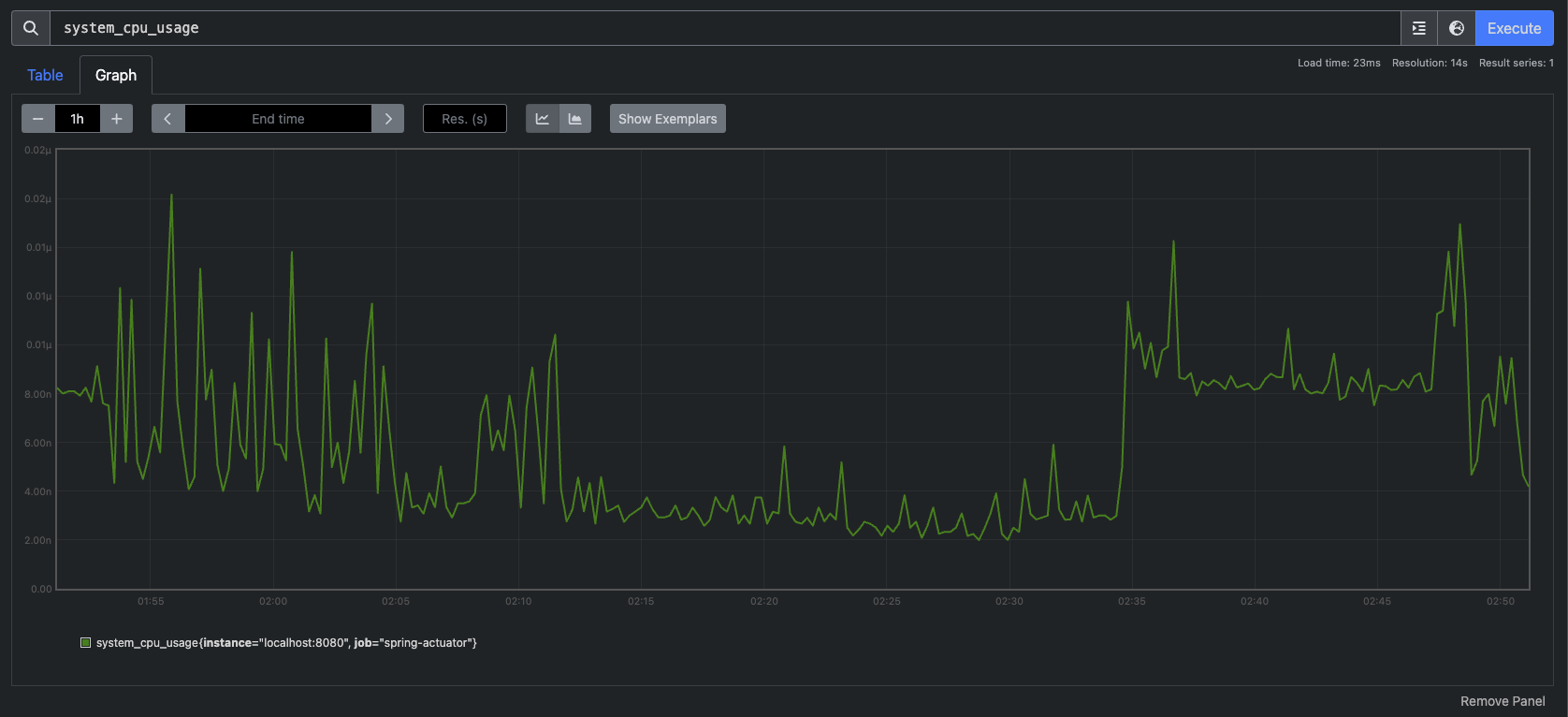
보이는것처럼 CPU 사용량은 오르기도 하고 내리기도 하는 그래프를 보여준다.
근데, 카운터는 어떤 모습일까? 이 카운터는 단순하게 증가하는 단일 누적 값이다. 예를 들어 고객의 HTTP 요청수를 떠올려 보면 된다. 요청수는 정체되거나 오르기만 한다. 그 모습을 그래프로 봐보자.
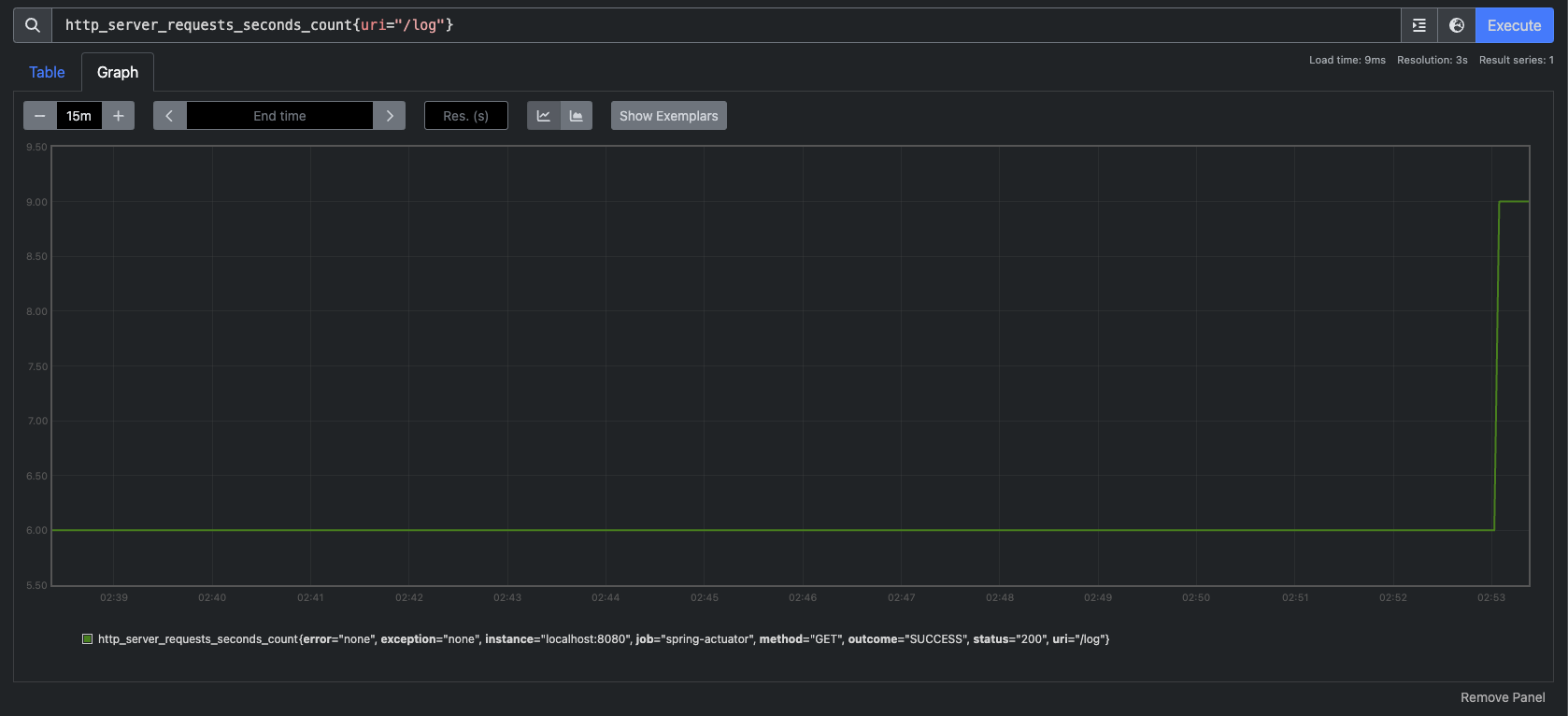
증가하지 않거나, 오르기만 한다. 근데 이런 경우 특정 시간에 얼마나 고객의 요청이 들어왔는지 한눈에 확인하기 매우 어렵다. 이런 문제를 해결하기 위해 increase(), rate()와 같은 함수를 지원한다.
시간 단위 요청 그래프
분당, 또는 시간당 얼마나 고객의 요청이 어느정도 증가했는지 한눈에 파악하기 쉽게 increase() 함수를 사용해보자.
지정한 시간 단위별로 증가를 확인할 수 있다. 마지막에 [시간]을 사용해서 범위 벡터를 선택해야 한다.
예) increase(http_server_requests_seconds_count{uri="/log"}[1m])
increase() 그래프
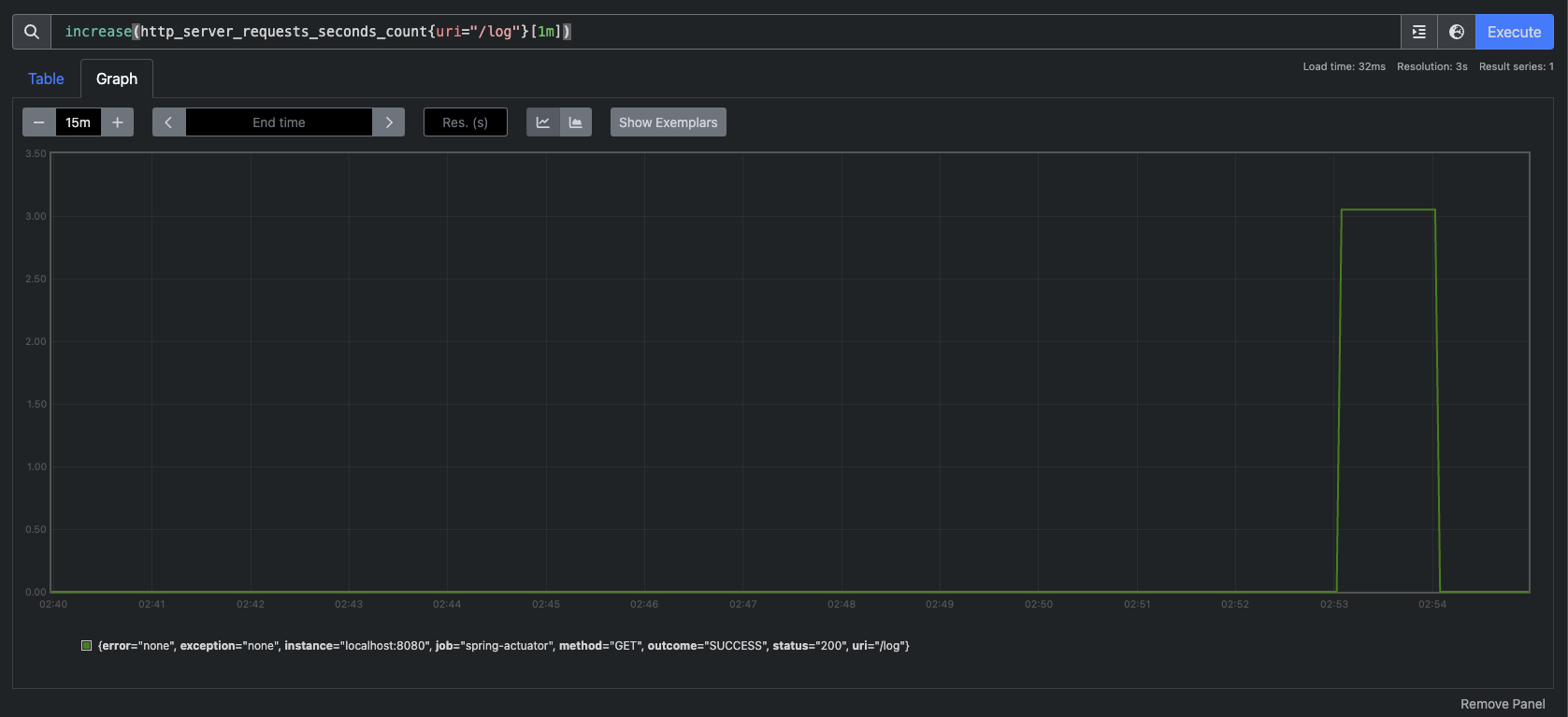
보이는것처럼 특정 시간에 사용자 요청이 급격하게 올라가고 특정 시간에 급격하게 내려가는 것을 확인할 수 있다.
이와 비슷하게 rate()라는 것도 있는데, 이건 비율로 보여주는 거고 increase()는 정적인 숫자로 결과를 보여주는 것이라고 보면 된다.
irate()도 있는데 irate()는 rate()와 유사한데 범위 벡터에서 초당 순간 증가율을 계산한다. 급격하게 증가한 내용을 확인하기 좋다.
irate() 그래프
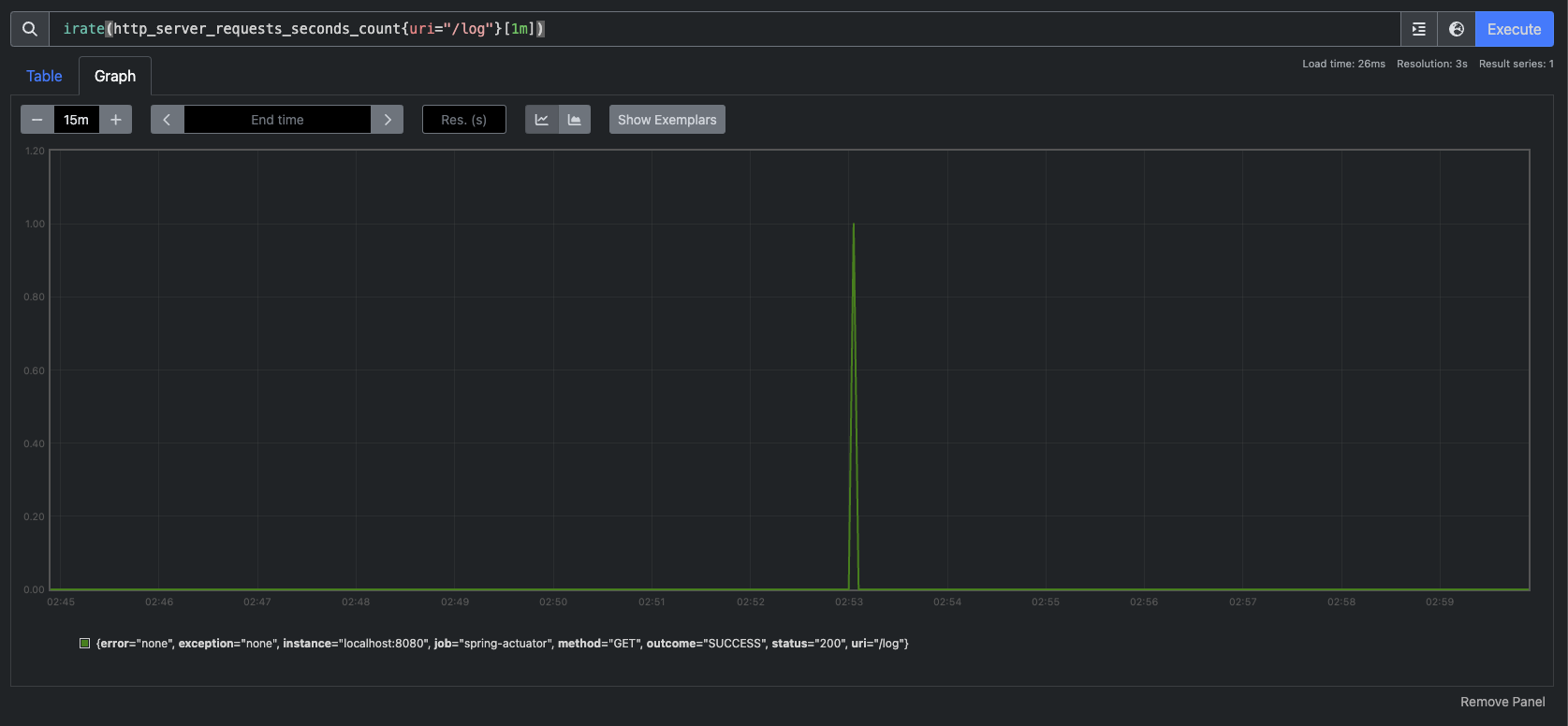
정리
게이지는 값이 계속 변하는, 오르락 내리락하는 값을 그래프로 표현한다. 카운터는 값이 단조롭게 증가하는 카운터는 increase(), rate()등을 사용해서 표현하면 된다. 이렇게 하면 카운터에서 특정 시간에 얼마나 고객의 요청이 들어왔는지 확인할 수 있다. 그러나, 프로메테우스의 단점은 한눈에 들어오는 대시보드를 만들어보기 어렵다는 점이다. 위에서도 뭔가 보기 위해 계속 지표를 변경하고, 시간을 바꾸고 등등의 수작업이 들어가는데 이런 부분을 그라파나로 해결할 수 있다.
그라파나
이제 그라파나를 사용해서 대시보드를 이쁘게 꾸며보자. 그러기 위해 우선 다운받아야 한다.
MacOS는 간단하게 명령어로 다운받을 수 있다.
curl -O https://dl.grafana.com/enterprise/release/grafana-enterprise-11.1.0.darwin-amd64.tar.gz
우선 위 명령어로 설치 파일을 내려 받자. 그 다음 그 파일을 풀면 된다.
tar -zxvf grafana-enterprise-11.1.0.darwin-amd64.tar.gz
참고로 이 설치는 다음 링크에서 자세히 확인해볼 수 있다.
Download Grafana | Grafana Labs
Overview of how to download and install different versions of Grafana on different operating systems.
grafana.com
설치를 다 마치면 `/bin` 폴더에 들어가야 한다. 들어가면 `grafana-server` 라는 실행 파일이 있다. 실행하자.
실행하면 쭉 로그가 찍히는데 대략 이렇게 생겼다.
잘 실행됐는지 확인하려면 `localhost:3000` 으로 들어가보자. 그라파나는 기본 포트가 3000이다.
최초 접속 정보는 `admin/admin` 이다. 추후에 변경할 수 있다.
로그인에 성공하면 다음과 같은 화면이 보일것이다.
그라파나 - 프로메테우스 연동
이제 프로메테우스로부터 데이터를 받아 그라파나에 데이터를 대시보드로 이쁘게 보여주자.
그러려면 우선 다음이 실행중이어야 한다.
- 애플리케이션 서버
- 프로메테우스 서버
- 그라파나 서버
그리고 연동하기 위해 좌측 사이드바에 Connections > Data sources를 클릭한다.
그럼 다음과 같은 화면이 나온다. Add data source 클릭

그럼 바로 앞에 프로메테우스가 보여진다. 클릭.
커넥션 주소를 넣어줘야 한다. 프로메테우스는 9090으로 띄워져 있다.
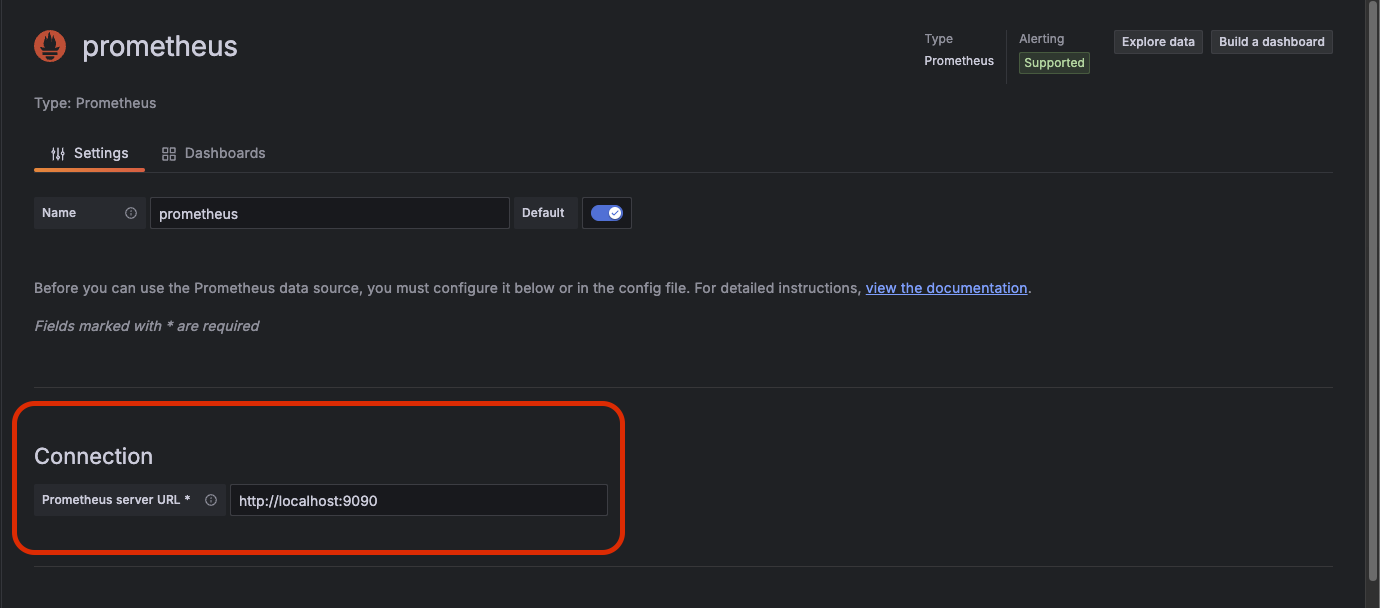
나머지는 필요없다. 최하단에 Save & test 버튼 클릭
잘 연동되면 다음과 같은 화면이 보인다.

그라파나 대시보드 만들기
이제 연동도 했으니 대시보드를 만들어보자. 좌측 사이드바에 Dashboards 클릭
그럼 이러한 화면이 보여진다. New > New dashboards 버튼 클릭
클릭하면 화면이 하나 보일텐데 우선 Save 버튼을 눌러서 대시보드를 저장하자.
그 다음 다시 처음 화면으로 돌아가서 + Add visualization 버튼 클릭
그럼 아래와 같은 화면이 보여진다. 여기서 가장 먼저 확인할 건 Datasource가 프로메테우스로 잘 되어 있는지 확인하자.
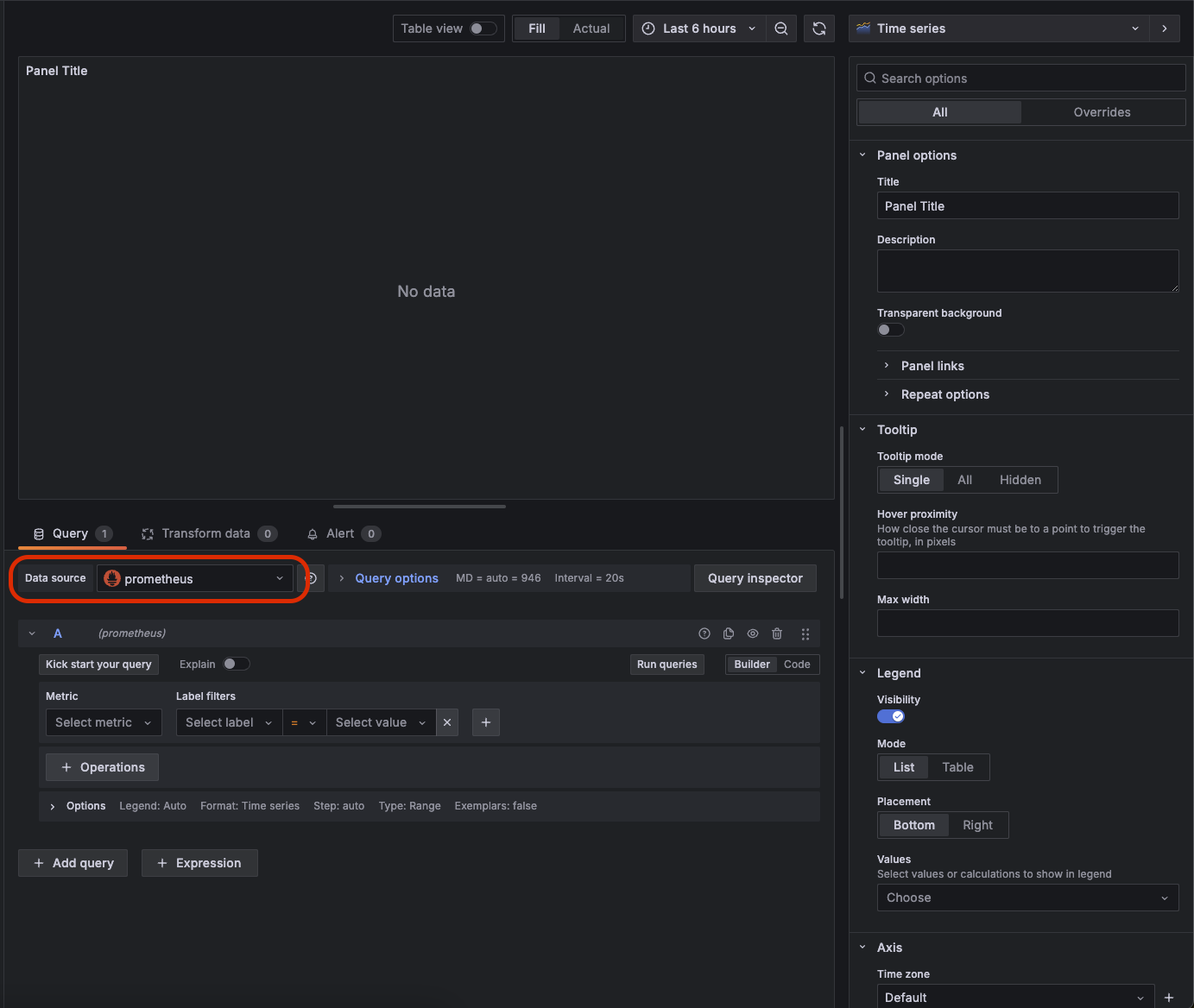
그 다음 그 하단에 쿼리를 날려서 데이터를 프로메테우스로부터 가져온다. 그러기 위해 우선 Builder 대신 Code를 선택하자.
가장 간단한 CPU 사용량을 확인해보자. 하단 사진처럼 `system_cpu_usage`을 입력하고 Run queries 버튼 클릭
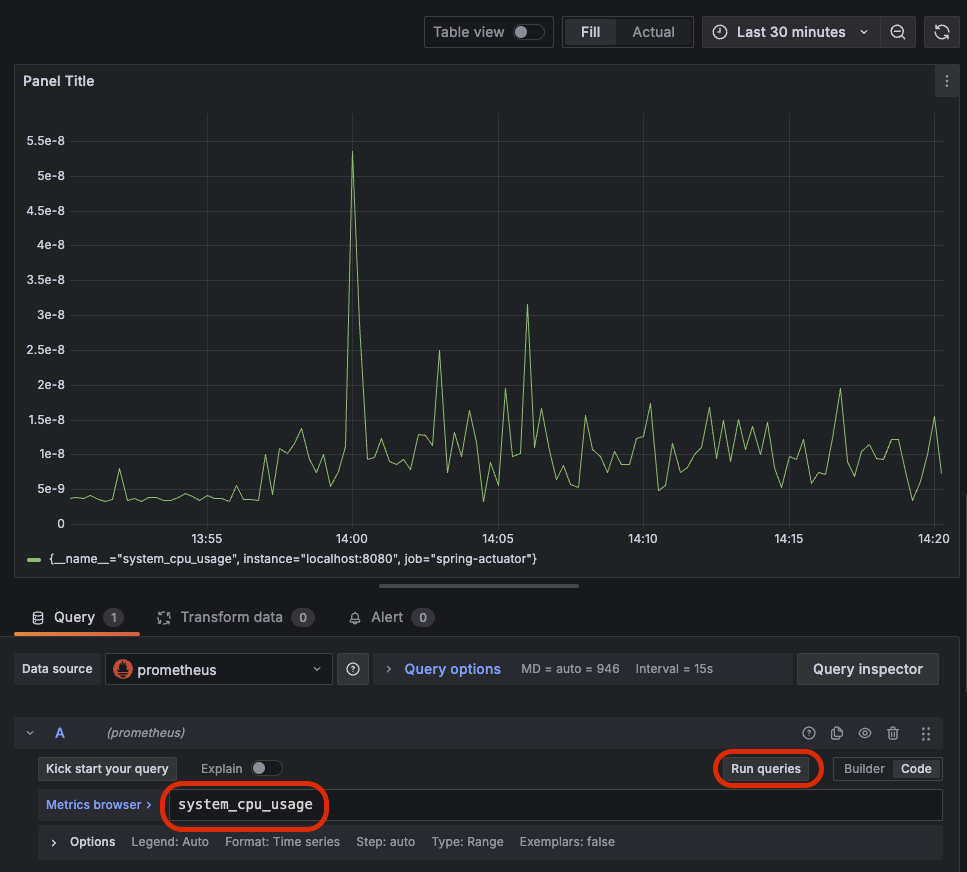
그럼 위처럼 데이터를 가져와서 차트로 보여준다. 여기에 한 가지 지표를 더 추가하자.
하단에 + Add query 버튼 클릭
`process_cpu_usage`를 입력하고 Run queries 버튼을 클릭하면 두 지표가 동시에 보여진다.

그럼 보자. 두 지표가 동시에 이쁘게 잘 나온다. 상대적으로 System CPU는 거의 잡아먹지 않고 Process CPU가 좀 더 많이 사용중인걸 한 눈에 볼 수 있다. 근데 보여지는 이름이 맘에 들지 않는다. 그래서 이름을 좀 더 간결하게 바꿔주자. 아래 사진처럼 특정 지표에 하단 Options 버튼을 클릭하면 Legend라는 단어가 보인다. 이걸 범례라고도 하는데 이 값을 Custom으로 변경해주자.
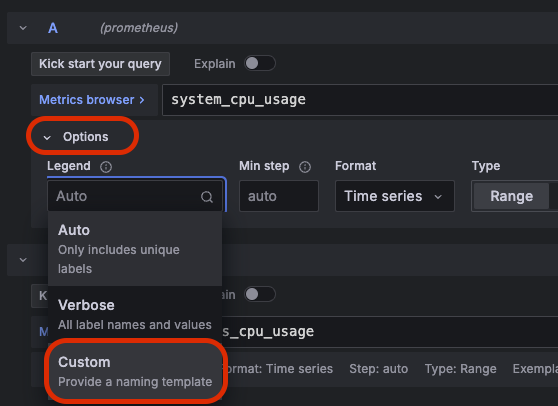
그런 다음 값을 "System cpu"로 입력해주면 다음과 같이 화면에 보이는 값이 변경된다.
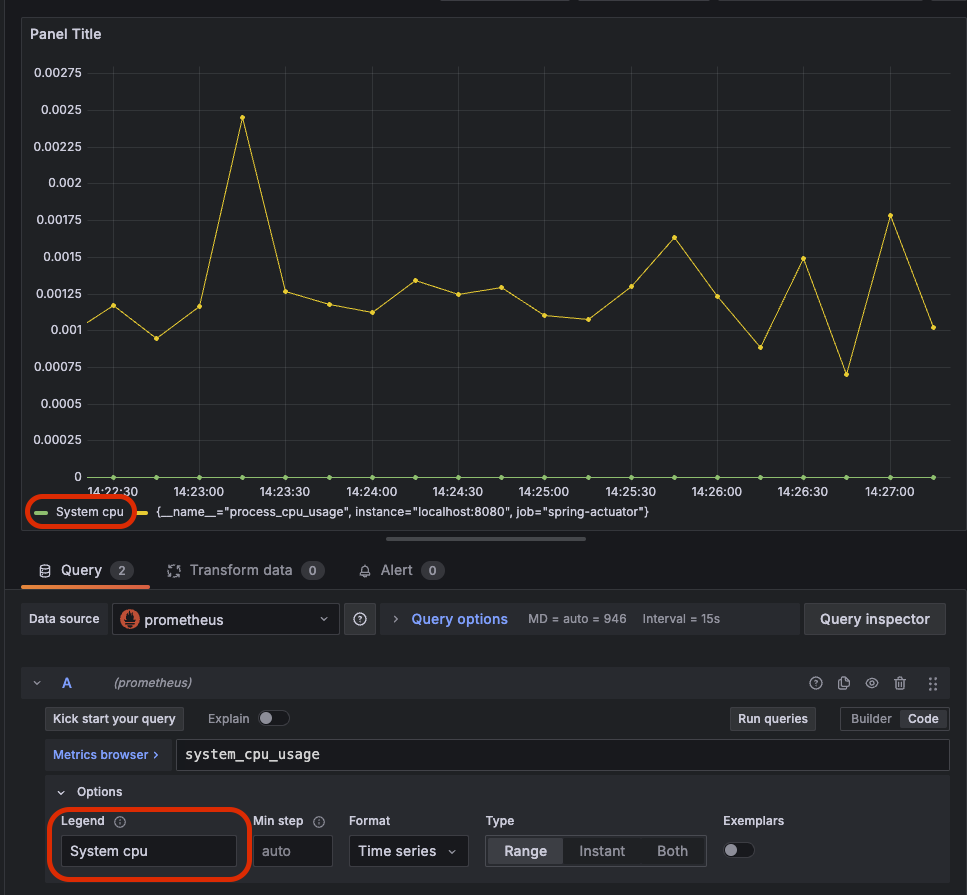
마찬가지로 Process cpu도 적용해주자. 그런 다음 이 패널의 제목을 다음과 같이 변경해주자.
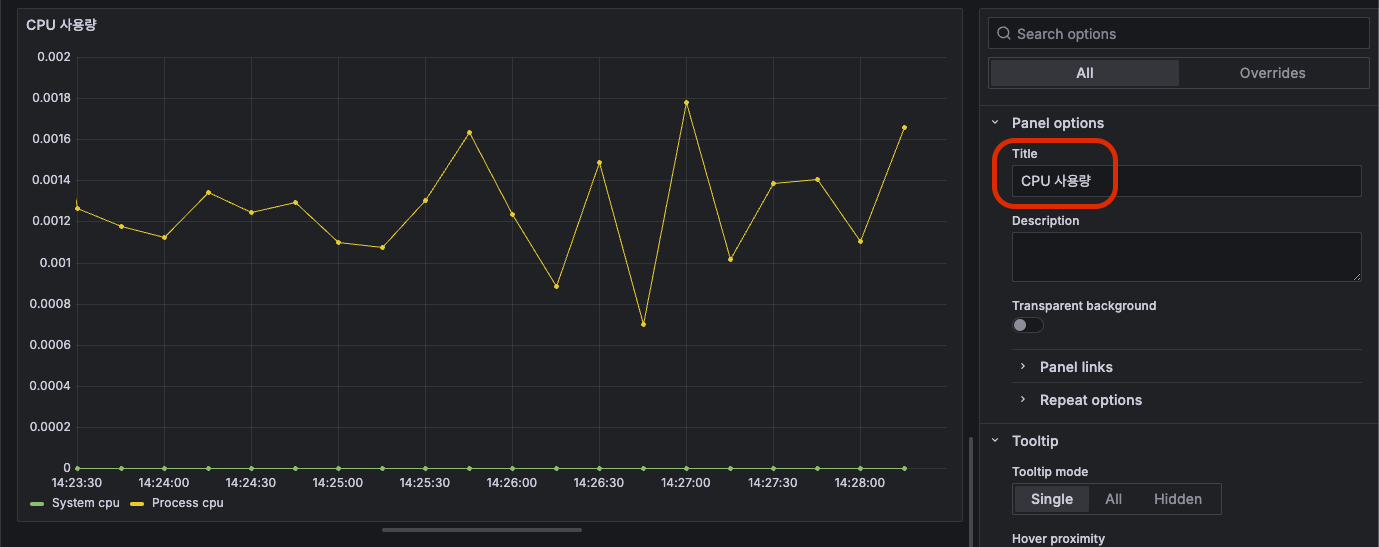
다 했으면 우측 상단에 Apply 버튼 클릭. 그럼 이렇게 보여진다.
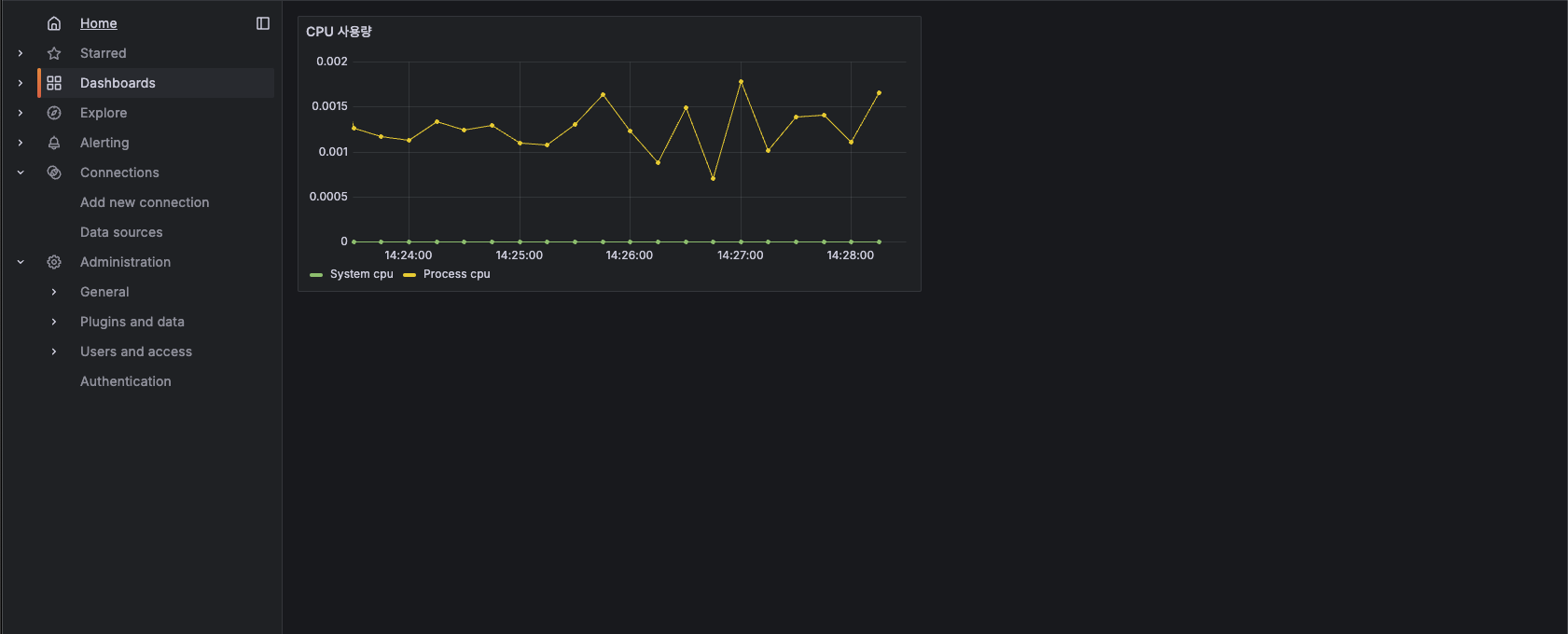
대시보드 만드는 거 어렵지 않다. 깔끔하게 잘 만들었다! 하나 더 만들어보자.
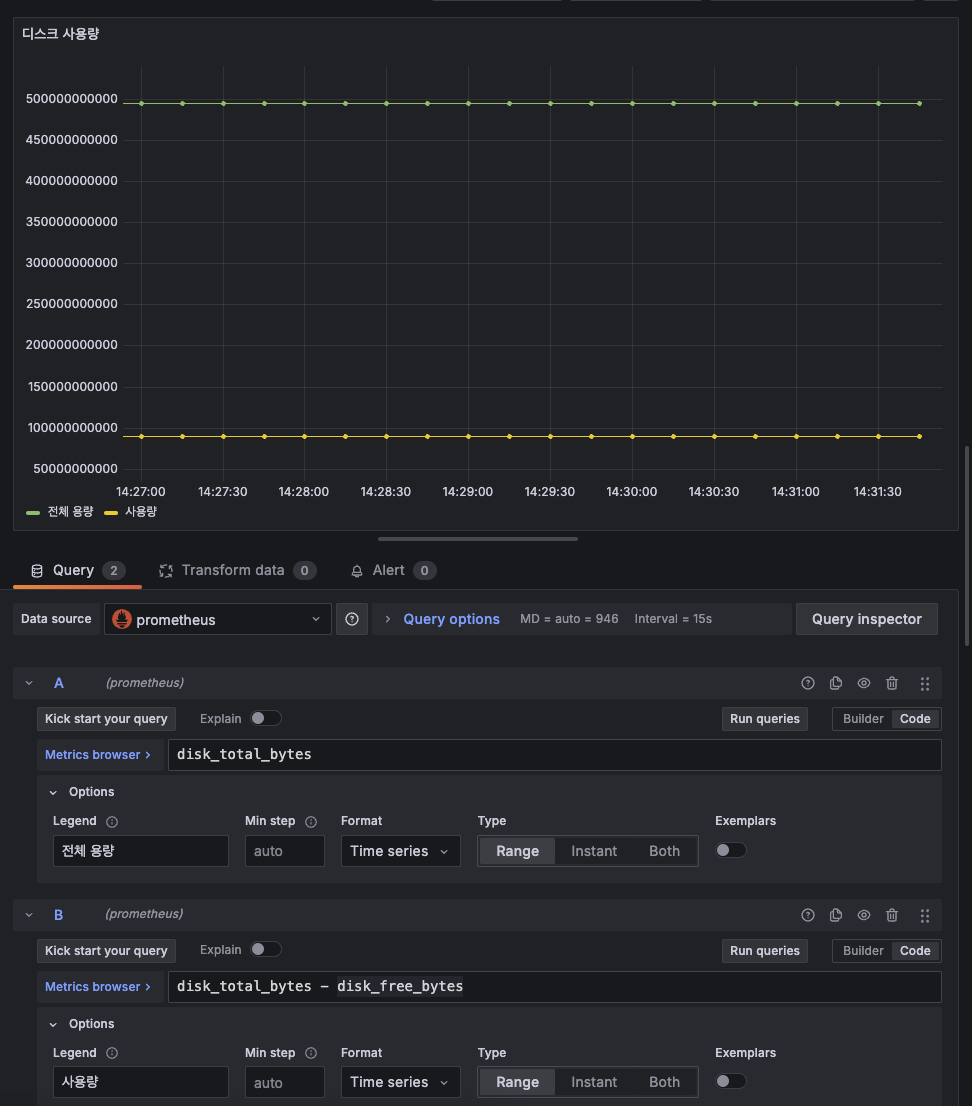
이번엔 디스크 사용량을 추가해보자. 이젠 여기까지 직접 할 수 있다.
두 개의 쿼리가 있는데, 하나는 전체 용량이고 하나는 전체 용량에서 여유 용량을 뺀 즉, 사용량이다.
이런식으로 연산도 가능하다.
근데, 다 좋은데 좌측에 값이 바이트 값으로 나와있어서 보기가 어렵다. 사람이 보기 편하게 바꾸고 싶은데 이럴땐 우측에 보면
Standard options > Unit 이것을 수정해주면 된다. Data > bytes(SI)로 수정해보자.
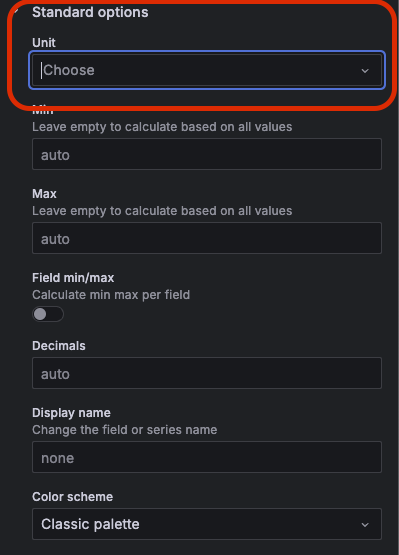
그럼 아래와 같이 깔끔하게 보여진다.

그리고 또 저장하자. 그럼 이렇게 잘 보여진다.
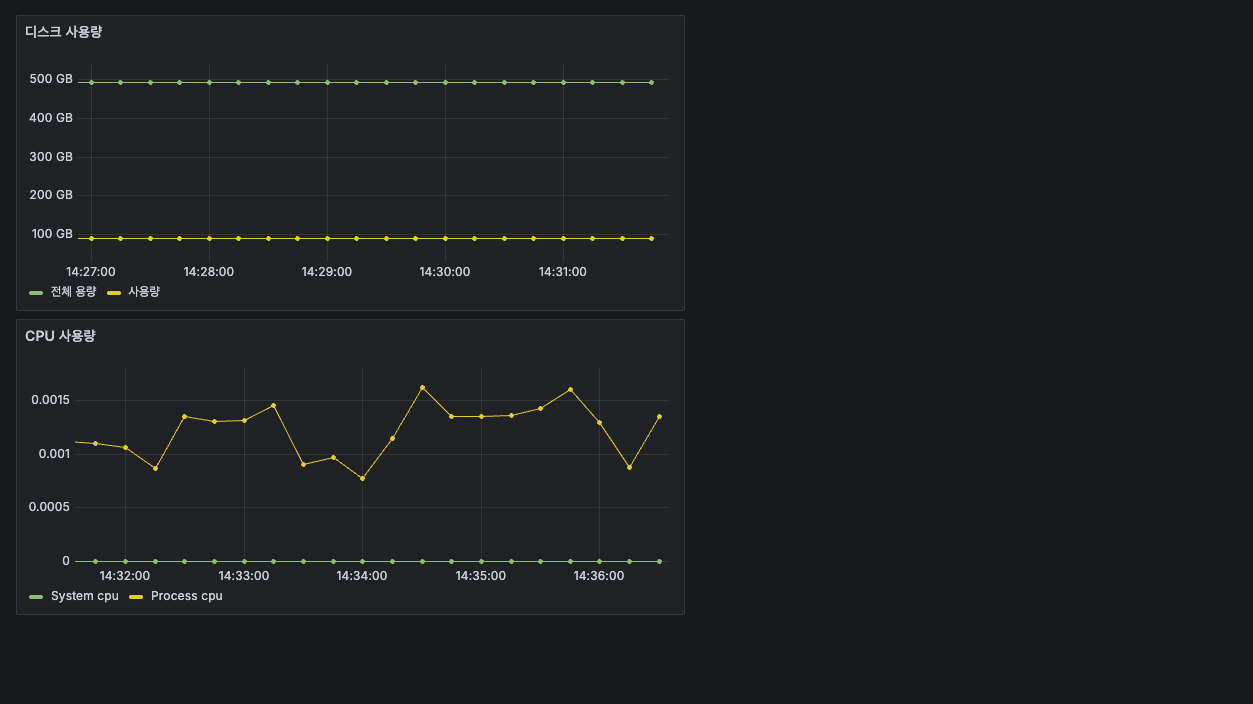
드래그로 이쁘게 한 줄로 만들어보자.
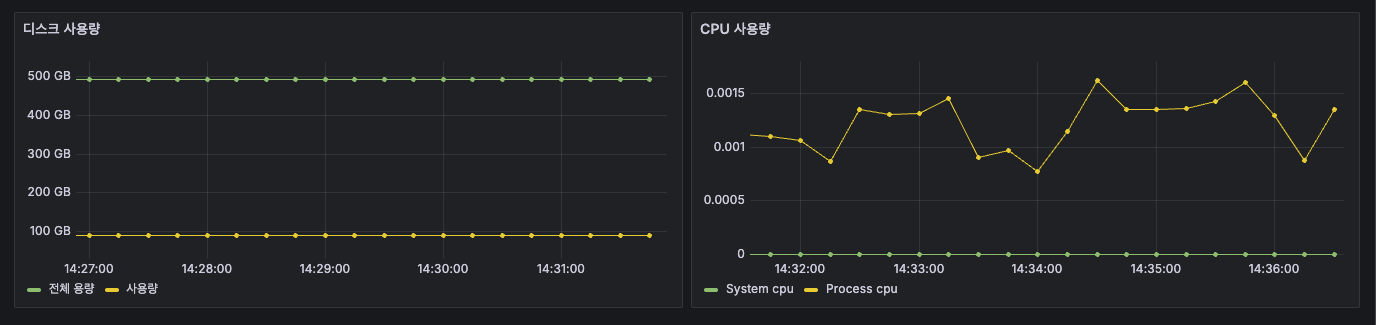
이렇게 이쁘게 하나하나 꾸며서 만들면 이제 시각적으로 메트릭 정보를 얻을 수 있게 됐다.
근데, 프로젝트 할 때마다 이렇게 하나 하나 만드는 것도 여간 귀찮은 일이 아니다. 그러면? 이미 만들어둔 대시보드를 가져다가 사용할 수 있는 기능을 제공한다. 그것도 아주 잘 만들어 놓은. 그것을 사용해보자.
그라파나 공유 대시보드 활용
사람들이 자기가 만든 대시보드를 공유하는 사이트가 있다.
Grafana dashboards | Grafana Labs
No results found. Please clear one or more filters.
grafana.com
위 링크에 접속하면 여러 대시보드가 있는데, 여기에 "Spring"이라고 쳐보자.
그럼 아래처럼 여러개가 나온다. 저기 JVM (Micrometer)와 Spring Boot 2.1 System Monitor 이 두 개는 엄청 유명하다.

Spring Boot 2.1 System Monitor
Spring Boot 2.1 System Monitor 이거를 사용해보자. 클릭해서 들어가보면 다음과 같이 보여진다.
여기서 우측에 Copy ID to clipboard 버튼 클릭
그리고 다시 그라파나로 돌아오자. 그래서 대시보드에 새로운 대시보드를 만들어보자.
Dashboards > New > Import 클릭
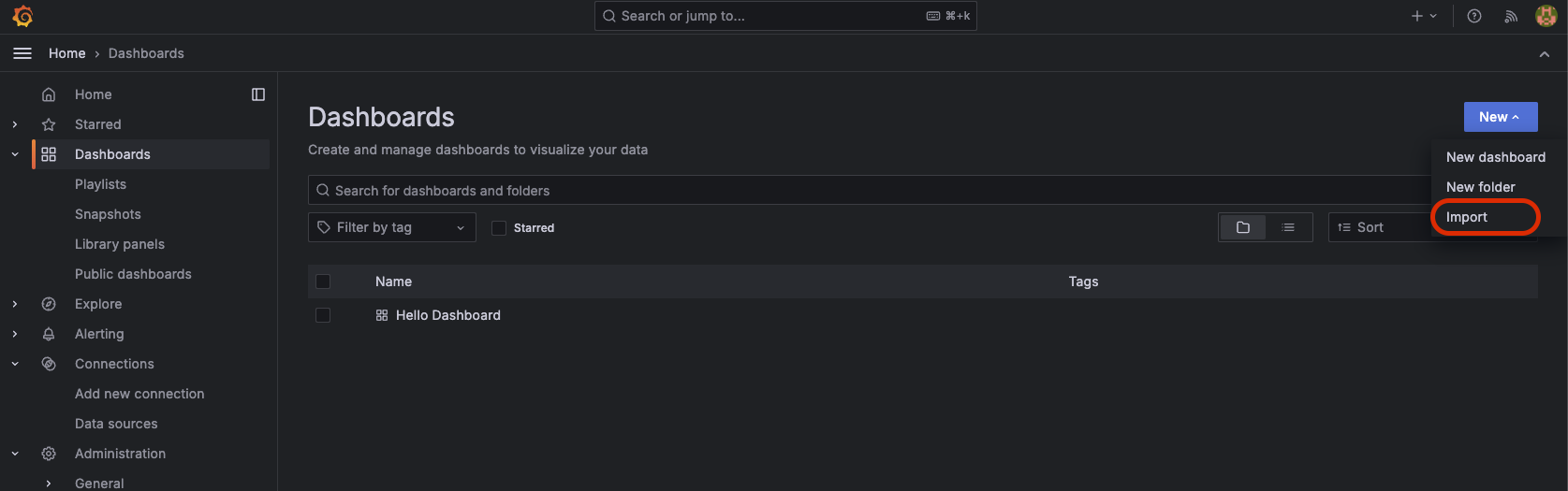
여기에 아까 복사한 ID를 넣고 Load 클릭
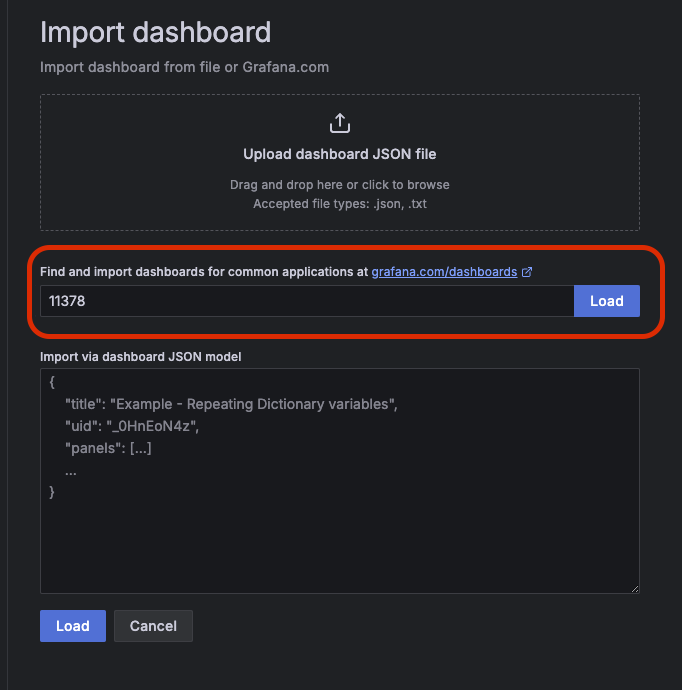
그럼 이런 화면이 나오는데 다른건 손댈게 없고 데이터소스만 프로메테우스로 잘 선택해주자. 그리고 Import 클릭
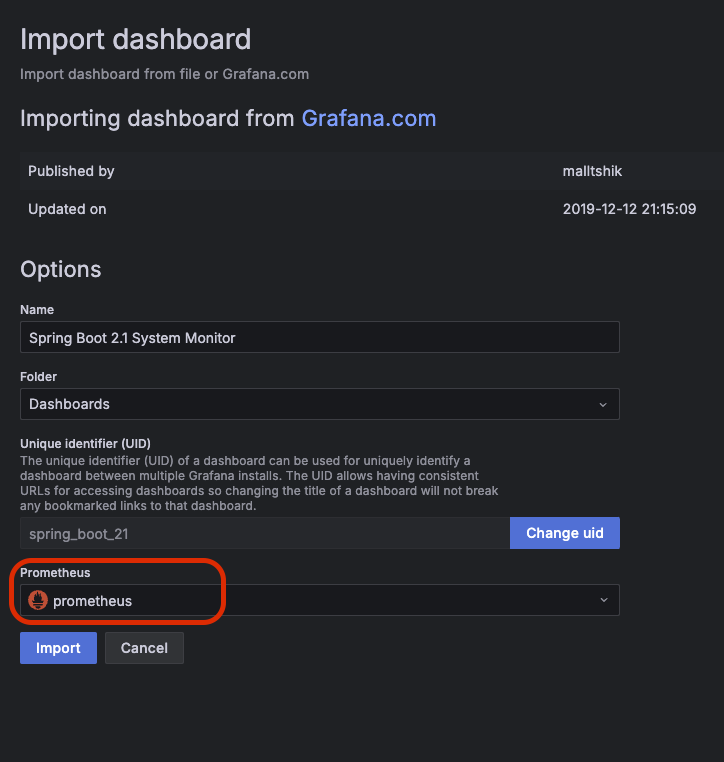
그럼 짜잔! 아름다운 대시보드가 만들어진다. 아래로 내리면 끝도 없이 많다!

이 대시보드를 수정할 수도 있다. 위에 설정 버튼을 눌러보자.
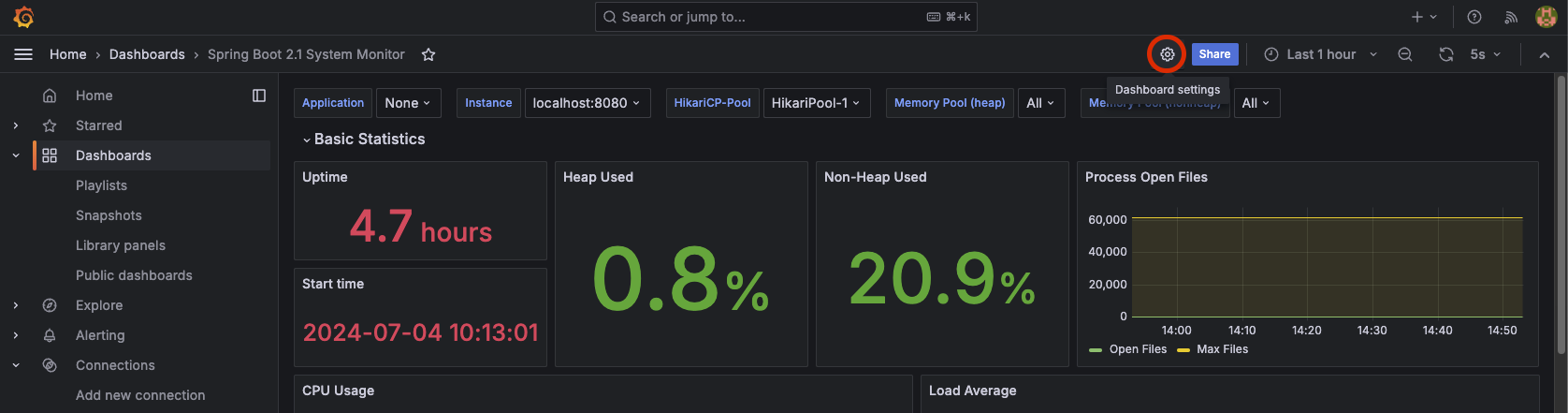
그럼 이 화면에서 Make editable 버튼 클릭
그럼 대시보드 들어가서 이렇게 어떤 쿼리를 쓴건지도 확인 가능하고 수정도 할 수 있다.

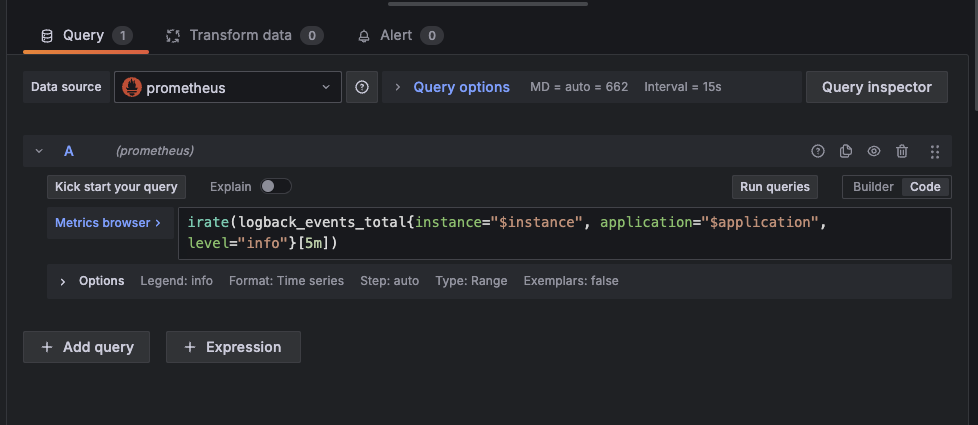
저기 쿼리에서 보면 instance, application은 딱 보니 변수로 받는거 같다. 이 변수 어디서 오는걸까?
이 대시보드가 여러 인스턴스나 애플리케이션으로 적용할 수가 있다. 그래서 맨 위로 가보면 이런게 있다.

여기서 어떤 인스턴스나 애플리케이션을 선택하느냐에 따라 저 값을 동적으로 바꿀 수 있게 변수로 받고 있다.
정말 유용한거 같다! 근데 다 좋은데 우리의 스프링 부트는 톰캣으로 띄워지는데 톰캣에 대한 정보가 없는게 아쉽다. 그래서 변경해보자.
지금 데이터가 거의 없는 패널이 있다. 바로 Jetty Statistics 패널이다.

이걸 톰캣으로 바꿔보자.


그 다음에 Thread Config Max를 톰캣으로 변경해보자.
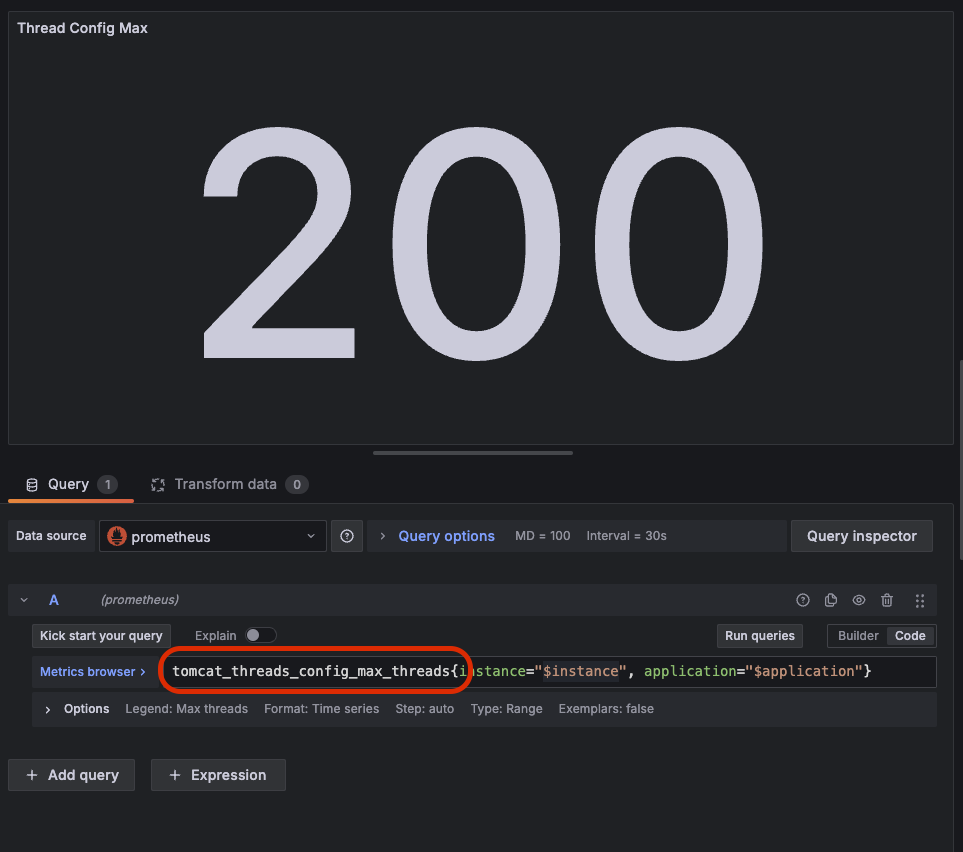
그리고 쿼리를 이렇게 변경해주자. 그럼 200개로 나온다. 톰캣은 기본 쓰레드 최대수가 200이다.
그런 다음, 지금 현재 사용중인 쓰레드 개수를 보고 싶다. 그래서 이 부분을 수정하자. 지금은 전부 Jetty로 되어 있어서 데이터가 안 나온다.

그래서 딱 이 두개의 쿼리를 적용해보자.
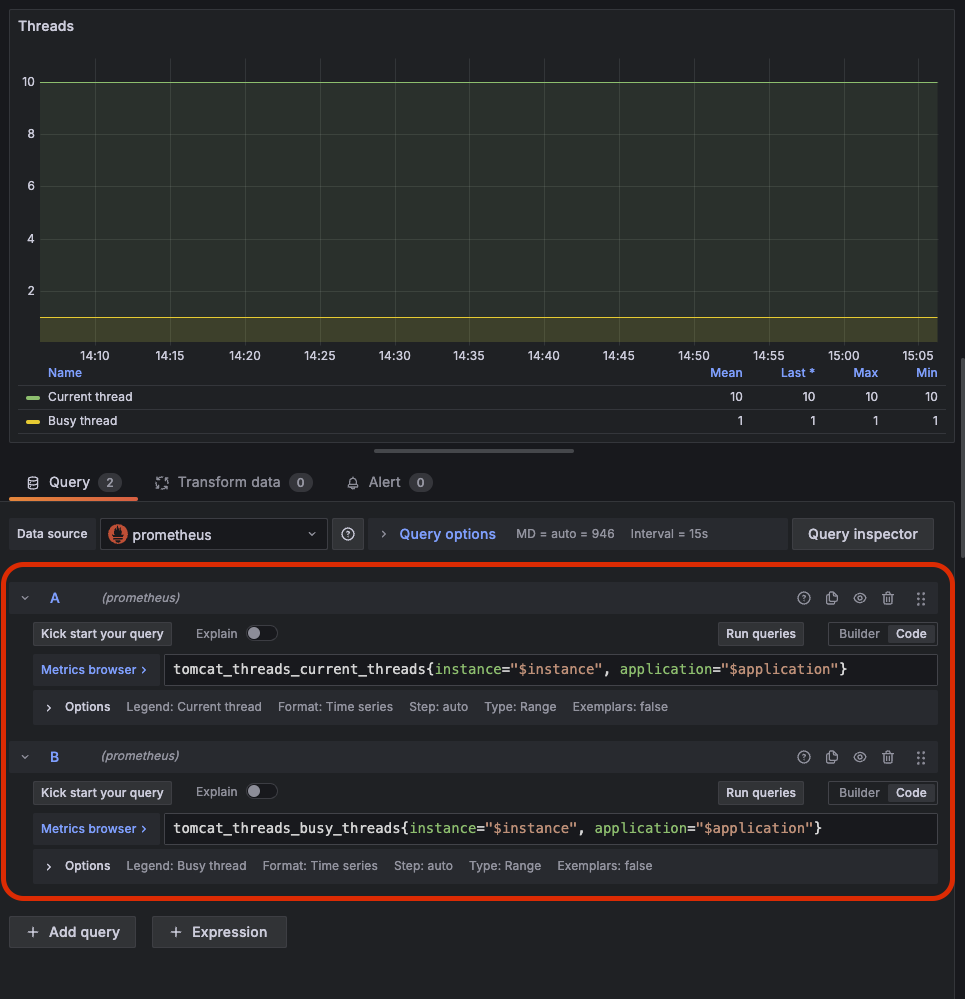
tomcat_threads_current_threads는 현재 톰캣에서 확보해 둔 쓰레드 개수를 의미하고
tomcat_threads_busy_threads는 지금 사용중인 쓰레드 수를 의미한다. 만약, 이 busy 쓰레드가 200개가 되면 애플리케이션이 죽을거다. 최대가 200개니까. 여튼 이렇게 하고 Apply 버튼 클릭하면 이제 잘 보여진다.
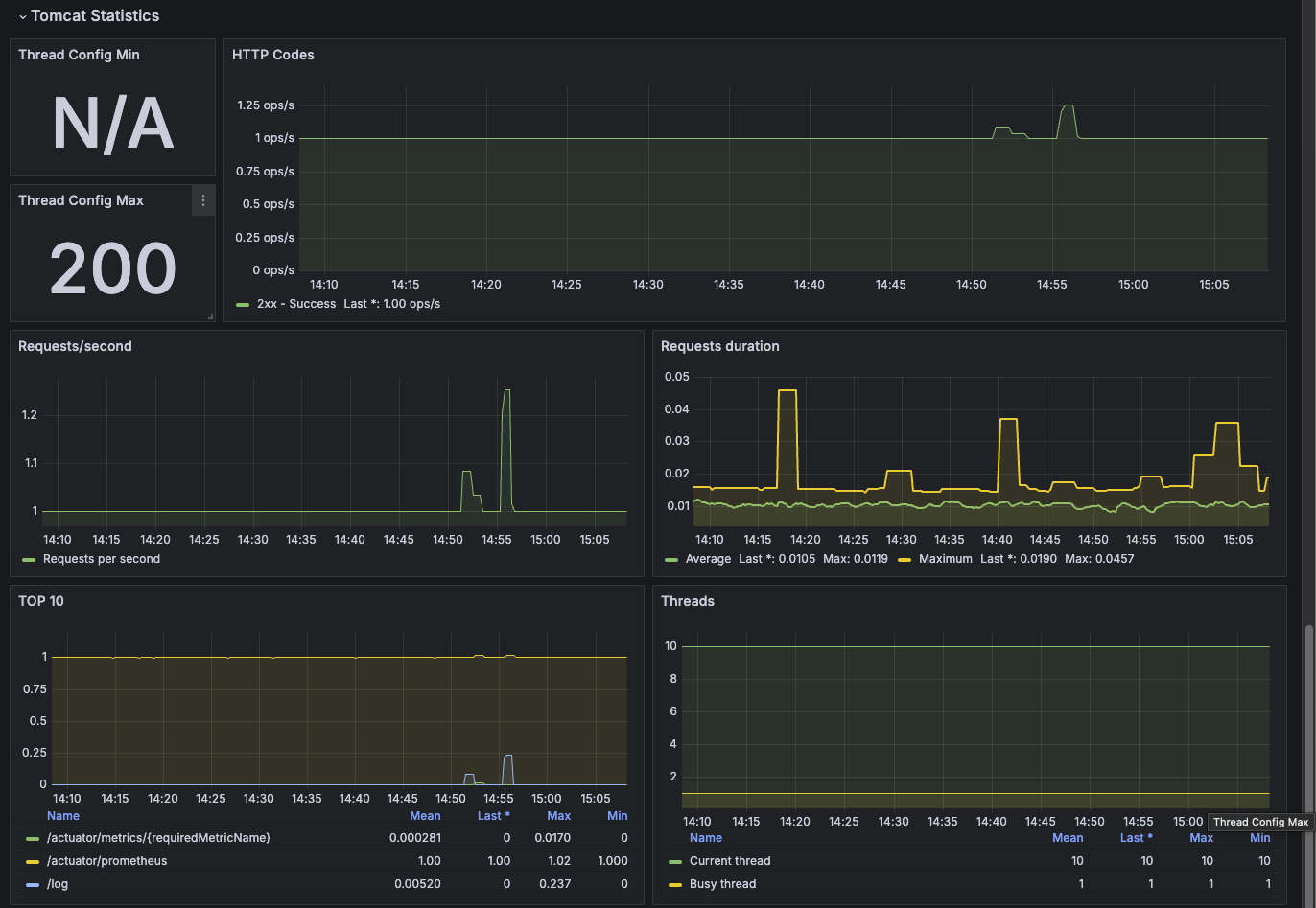
JVM (Micrometer)
이번엔 또 유명하다고 했던 JVM (Micrometer) 이거를 사용해보자.
똑같이 임포트를 해보면 다음과 같이 생겼다.
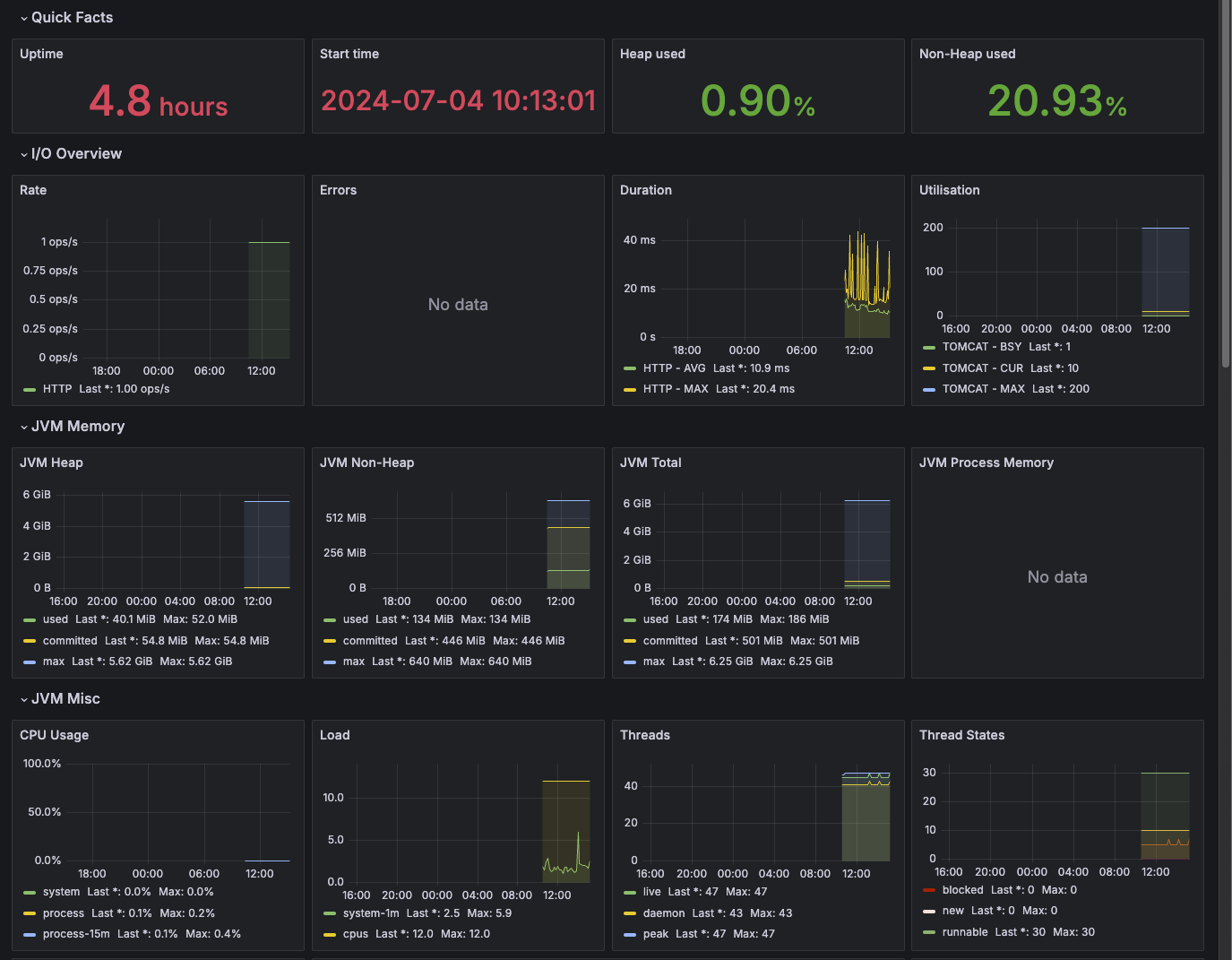
이렇게, JVM 쪽에 좀 더 초점을 둔 여러 데이터를 가시화했다. 둘 다 유용하게 사용할 수 있다.
대시보드 테스트 해보기
대시보드를 깔끔하게 다 구성했으니, 실제로 JVM 메모리라던가, CPU 사용량에 급격한 과부하를 줘서 어떻게 대시보드가 표현되는지 파악해보자. 우선 CPU 사용량을 급격하게 늘리기 위해 다음과 같은 코드를 짜보자.
TrafficController
package hello.controller;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
@Slf4j
@RestController
public class TrafficController {
@GetMapping("/cpu")
public String cpu() {
log.info("cpu");
long value = 0;
for (int i = 0; i < 10000000000000L; i++) {
value++;
}
return String.valueOf(value);
}
}다음과 같이 연산을 아주 아주 많이 반복해서 실행하면 CPU 사용량이 급격하게 올라갈거다. 이 컨트롤러를 호출해보자.
그럼 이러한 결과를 볼 수 있다. 갑자기 팍 치솟는 구간이 생긴다.

이번엔 JVM 메모리를 OOM 내보자. 이런 코드를 짜보자.
TrafficController
package hello.controller;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
@Slf4j
@RestController
public class TrafficController {
private List<String> list = new ArrayList<>();
@GetMapping("/jvm")
public String jvm() {
log.info("jvm");
for (int i = 0; i < 10000000; i++) {
list.add("hello jvm!" + i);
}
return "ok";
}
}리스트에 계속 계속 뭘 담아보자. 그럼 이러한 대시보드의 변화를 볼 수 있다.
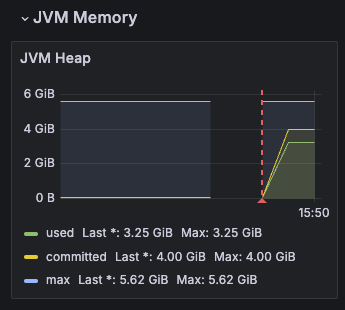
보면 JVM Memory의 최대치에 거의 근접해가는 사용량을 확인할 수 있다. 그리고 이 최대치에 도달하면? OOM이 터진다.
실제로 터져버려서 이런 에러가 뜬다. 대시보드에 적용되기도 전에 터져서 대시보드엔 보이지 않지만.

이번엔 커넥션 풀에 커넥션을 계속 사용해보자. 어떻게 될까?
TrafficController
package hello.controller;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
@Slf4j
@RestController
public class TrafficController {
@Autowired
DataSource dataSource;
@GetMapping("/jdbc")
public String jdbc() throws SQLException {
Connection connection = dataSource.getConnection();
log.info("connection info = {} ", connection);
// connection.close(); 원래는 이렇게 닫아야한다.
return "ok";
}
}이런 코드를 짜보자. 원래는 사용한 커넥션은 반납을 해야 한다. 그렇지 않으면 큰일난다. 근데 큰일을 내보자.
그리고 계속 호출해보자. 10번까지. (기본이 10개다)
그리고 일단 한 3번 호출해보자. 그럼 대시보드에 이렇게 보여진다.
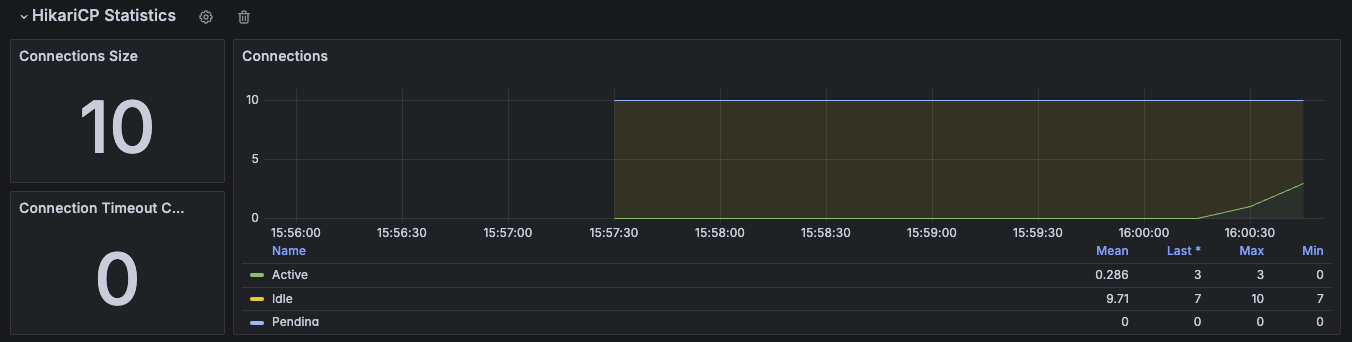
Active가 3개, 전체는 10개다. 이제 10개를 넘겨보자.
그럼 다음과 같이 Pending 커넥션이 생기게 된다. 계속 기다리고 있게 된다. 커넥션을 반납하지 않고 있기 때문에.
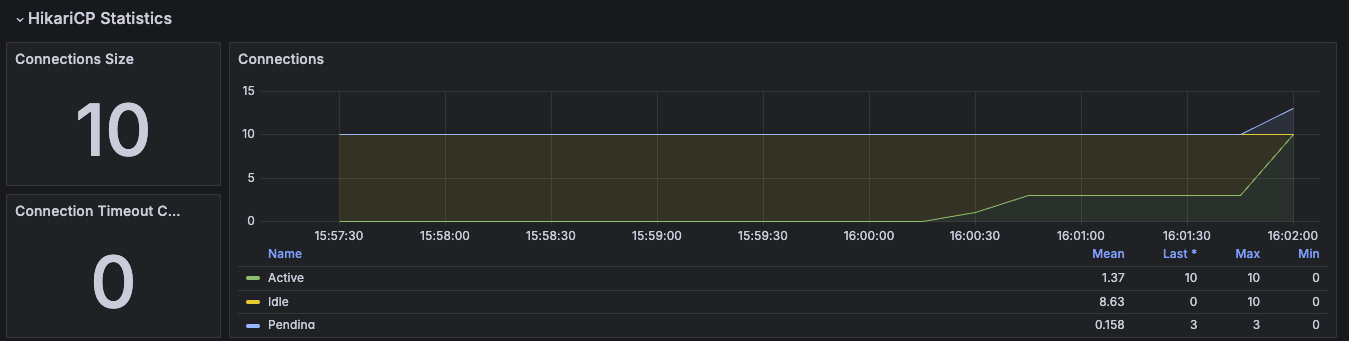
이런 모습이 보인다면, "큰일났다!" 라고 생각하면 된다. 그리고 이런 에러 로그가 보일거다.

이번엔 에러 로그를 계속 찍어보자. 이것도 확인이 되면 "어 뭐가 문제가 생긴것 같다!" 라고 느껴야 한다.
TrafficController
package hello.controller;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
@Slf4j
@RestController
public class TrafficController {
@GetMapping("/error-log")
public String errorLog() {
log.error("error!");
return "ok";
}
}이 컨트롤러를 계속 호출하면 대시보드에 이렇게 보여진다.
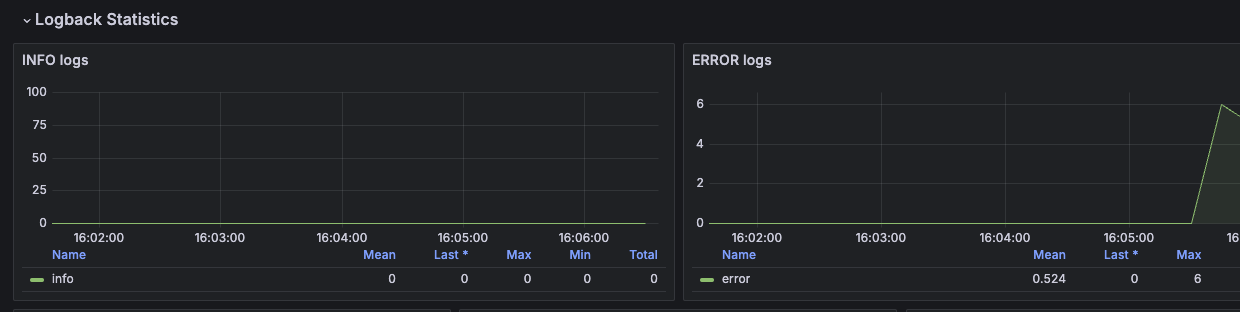
그럼 대시보드만 봐도 "어? 뭐지?" 싶은 생각이 들면 된다.
정리
이렇게 메트릭을 통해 대략적인 값과 추세를 확인해서 현재 시스템의 상태가 어떤지 판단하고 지속적인 경계를 해서 좋은 운영을 해보자.
이런 말이 있다. "전투에서 실패한 지휘관은 용서할 수 있다. 그러나 경계에서 실패한 지휘관은 용서할 수 없다."
'Spring, Apache, Java' 카테고리의 다른 글
| [프로덕션 준비] 모니터링 Part.3 커스텀 메트릭 등록하기 (0) | 2024.07.04 |
|---|---|
| [프로덕션 준비] 모니터링 Part.1 Actuator 사용하기 (0) | 2024.06.30 |
| 로컬 환경과 운영 환경에 구분될 빈 등록하는 방법 (0) | 2024.06.30 |
| 외부설정 사용 (0) | 2024.06.16 |
| 외부 설정과 프로필 관리 Part.2 (0) | 2024.06.14 |