우선 BFS, DFS를 알기 전 Tree를 알아야 하는게 먼저더라.
Tree
트리란, 부모 자식 관계를 나타낼 수 있는 자료 구조다.
다음 그림이 트리라고 말 할 수 있다.

- 노드 하나에 한개의 Parent 노드가 있을 수 있다.
- 노드 하나에 여러개의 Child 노드가 있을 수 있다.
이런 유형의 자료구조는 실생활에서도 너무 많이 접해볼 수 있다.
- 회사 조직도
- 가족 관계도
- File System
이런 트리 중 특별한 트리가 있는데 'Binary Tree'라는 게 있다.
Binary Tree
한 노드에 Child 노드가 최대 2개까지만 있는 트리를 Binary Tree라고 한다.
위 그림은 그럼 Binary Tree라고 할 수 없다. 왜냐하면, 한 노드(Node 1)가 Child Node를 3개까지도 가지고 있으니까.
Binary Tree는 Linked List와 굉장히 유사하게 생겼다. Linked List의 구조는 다음과 같다.

그리고 이 Linked List의 한 노드를 코드로 표현한다면 다음처럼 표현할 수 있겠다.
struct Node {
int value;
struct Node *next;
}
그럼 바이너리 트리는 여기에 자식이 하나씩 더 있을 수도 있는것뿐.
다음 그림이 Binary Tree라고 표현할 수 있다.

이 Binary Tree의 한 노드를 코드로 표현한다면 다음처럼 작성할 수 있다.
struct Node {
int value;
struct Node *left_child;
struct Node *right_child;
}
그래서, 이 바이너리 트리 구조를 메모리 상에서 어떻게 표현될지를 봐보자.


하나에 4 Byte 메모리 구조를 보자.
Node 1은 값으로 1을 가지고 있고, left_child, right_child에 대한 각각의 주소를 가리키는 포인터를 가지고 있다.
Node 1의 left_child가 가리키는 주소를 따라가면 Node 2가 가진 값 2가 나온다.
Node 1의 right_child가 가리키는 주소를 따라가면 Node 3가 가진 값 3이 나온다.
Node 3은 자식이 없기 때문에 가리키는 포인터도 없다.
Node 2는 하나의 자식을 left_child가 가리키고 있고 그 주소를 따라가면 Node 4가 가지고 있는 값 4가 나온다.
Node 4도 자식이 없기 때문에 가리키는 포인터도 없다.
Tree, Binary Tree 둘 다 뭔지 알겠다. 그럼 이 트리를 어떻게 탐색할까? 이 탐색하는 방법이 앞에서 말한 DFS, BFS가 된다.
DFS (Depth First Search)
트리를 탐색하는 가장 일반적인 방법 중 하나인 깊이 우선 탐색(DFS)가 있다.
다음 트리를 보자.
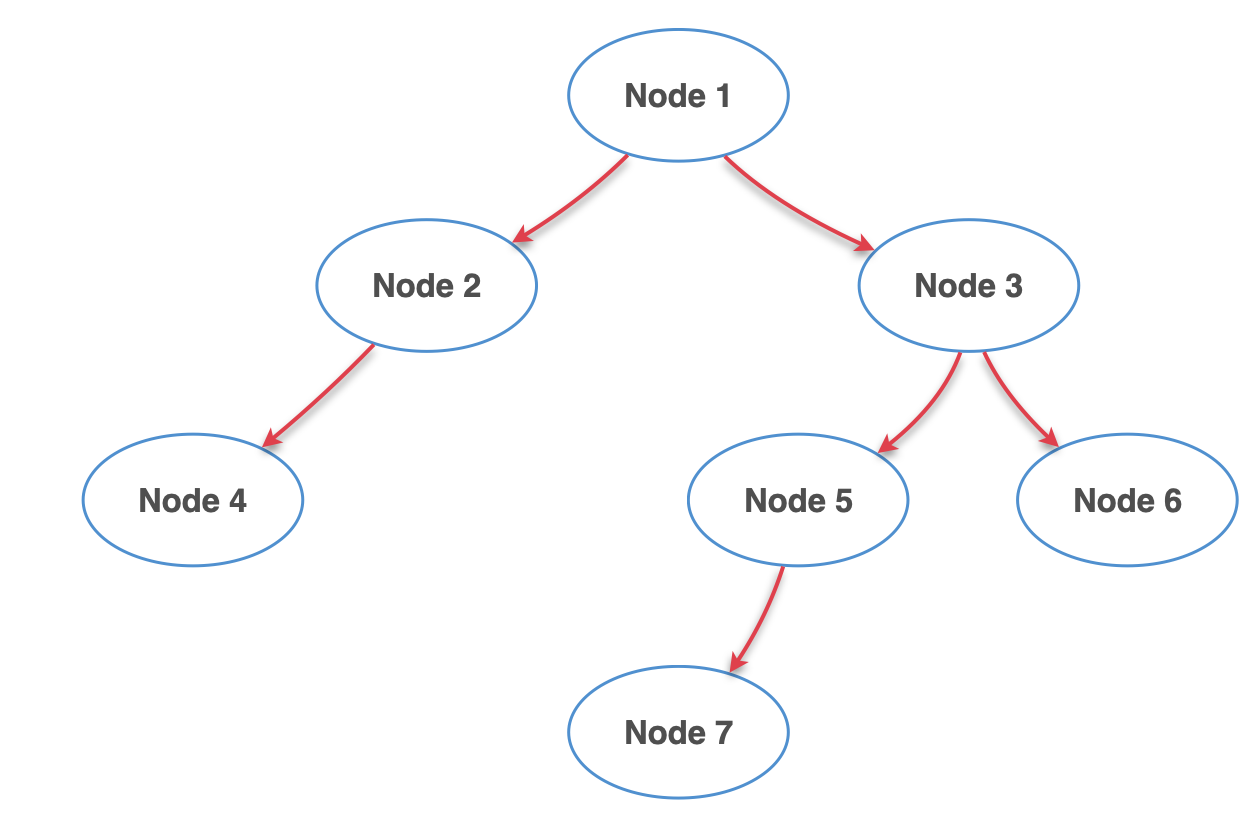
DFS는 깊이 우선 탐색, 즉 한쪽 방향으로 탐색을 시작했으면 더 내려갈 수 없을때까지 아래로 내려가서 확인하는 것을 말한다.
그래서 Node1 부터 탐색을 시작하고 왼쪽 또는 오른쪽으로 하나 방향을 잡은 후 그 방향의 가장 하단까지 쭉 검색하고 다시 반대편으로 돌아오는 방식이라고 생각하면 된다.
예시
1단계

2단계

3단계
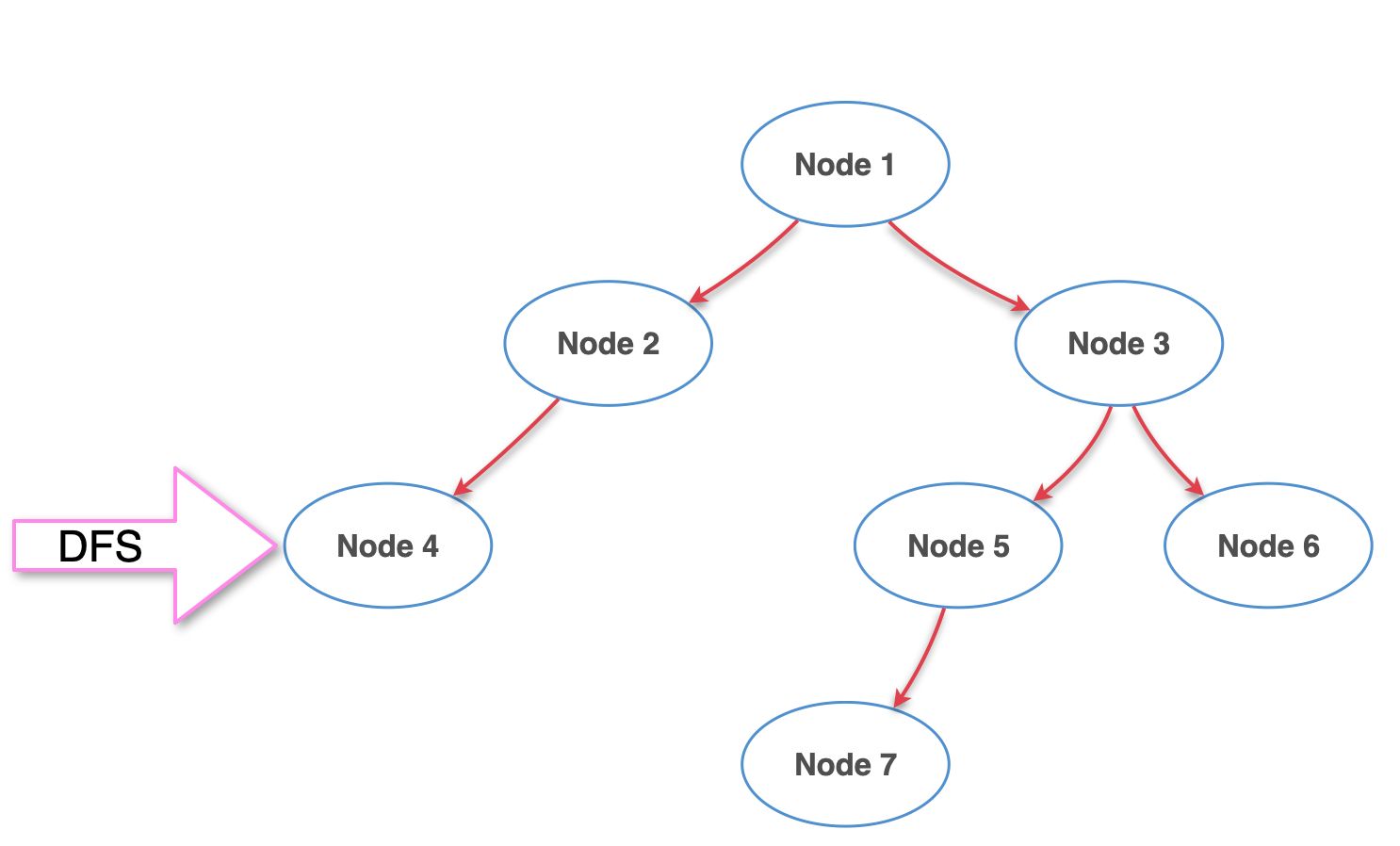
3단계가 끝나고 더 내려갈 수 없을 만큼 내려왔으니 다시 Node 1으로 가서 왼쪽을 다 털었으니 오른쪽으로 털기 시작한다.
4단계

5단계
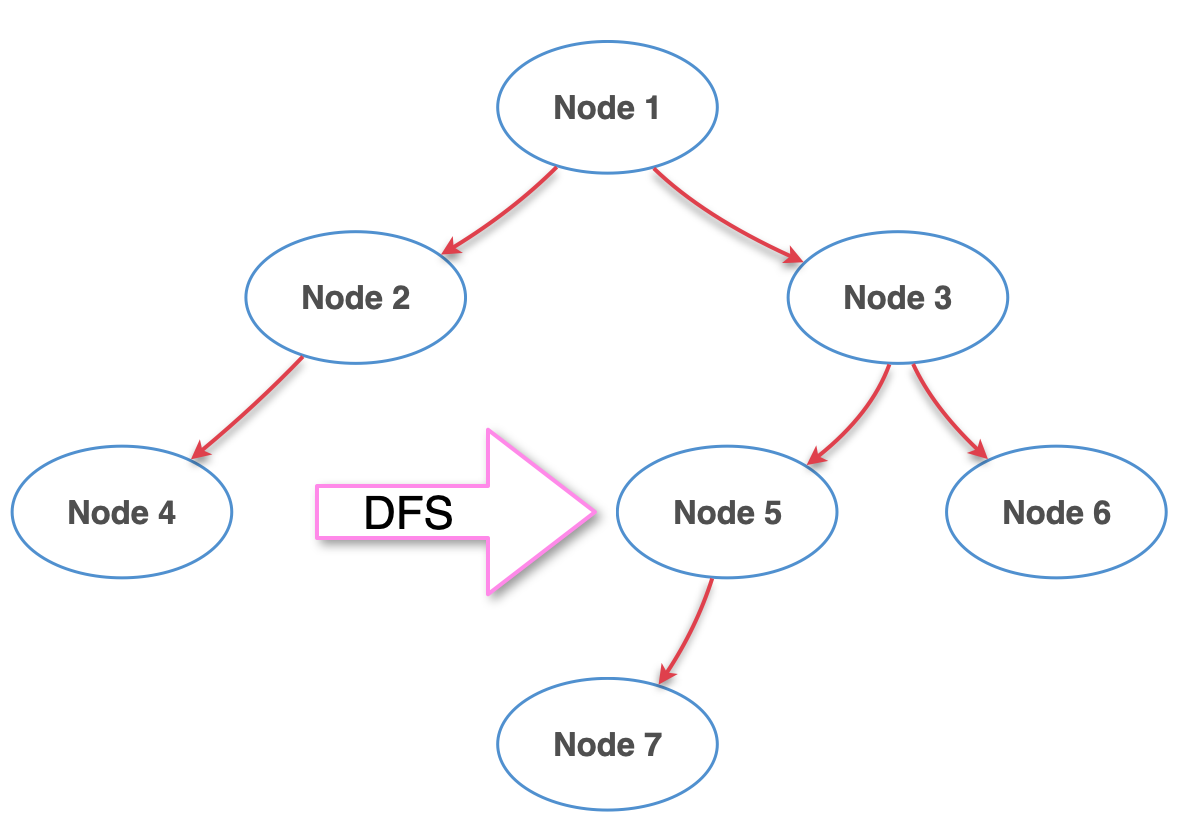
6단계
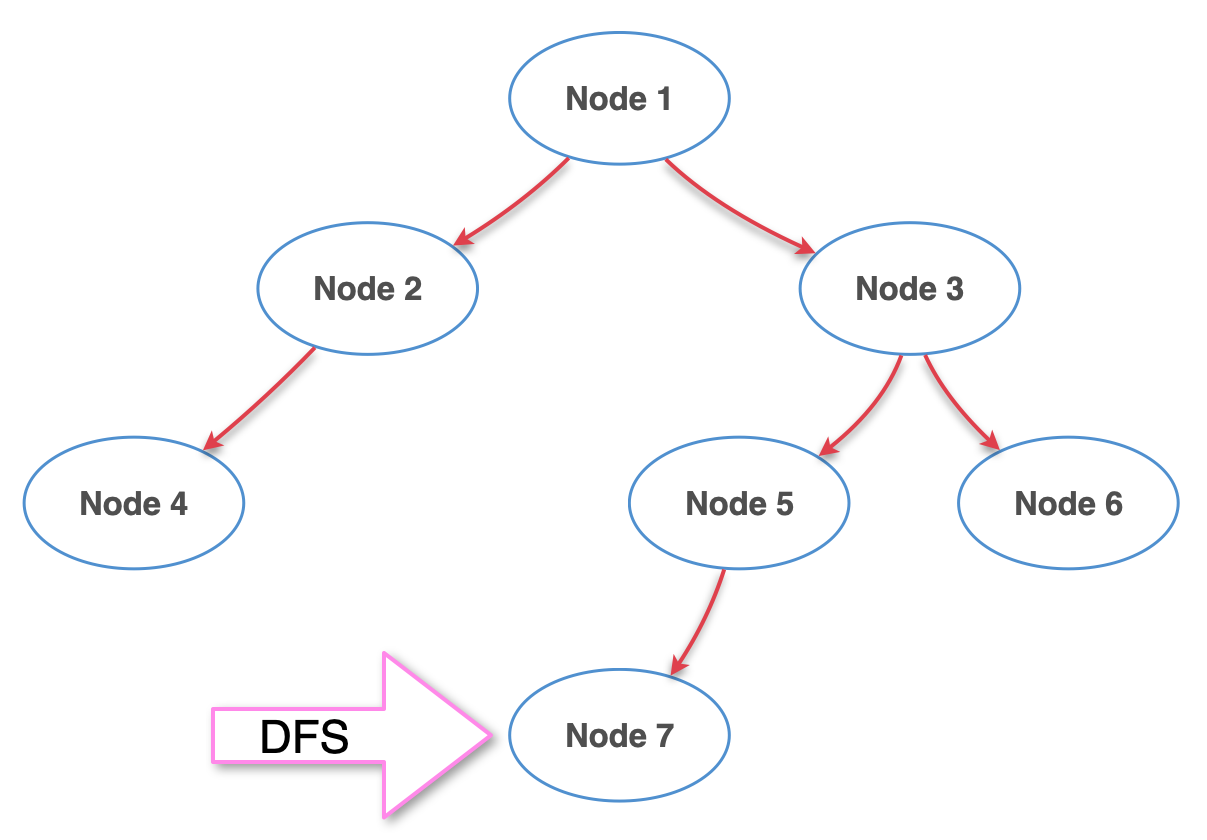
Node 3을 기준으로 왼쪽 끝까지 갔으니 이제 다시 Node 3의 오른쪽을 털면 된다.
7단계

그럼, DFS는 코드로 어떻게 구현할 수 있을까?
DFS 코드로 구현하기
DFS(Depth First Search)는 Recursion(자기 자신 참조)으로 간단하게 구현할 수 있다.
난 JAVA를 좋아하니까 JAVA로 구현해보겠다.
TreeNode
package dfs.binarytree;
public class TreeNode {
private final int value;
private TreeNode left;
private TreeNode right;
public TreeNode(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public TreeNode getLeft() {
return left;
}
public TreeNode getRight() {
return right;
}
public void setLeft(TreeNode left) {
this.left = left;
}
public void setRight(TreeNode right) {
this.right = right;
}
}
BinaryTree
package dfs.binarytree;
public class BinaryTree {
public static void dfs(TreeNode root) {
if (root == null) {
return;
}
System.out.println("node Value = " + root.getValue());
dfs(root.getLeft());
dfs(root.getRight());
}
}
Main
package dfs.binarytree;
public class Main {
public static void main(String[] args) {
TreeNode nodeOne = new TreeNode(10);
TreeNode nodeTwo = new TreeNode(20);
TreeNode nodeThree = new TreeNode(30);
TreeNode nodeFour = new TreeNode(40);
TreeNode nodeFive = new TreeNode(50);
TreeNode nodeSix = new TreeNode(60);
TreeNode nodeSeven = new TreeNode(70);
nodeOne.setLeft(nodeTwo);
nodeOne.setRight(nodeThree);
nodeTwo.setLeft(nodeFour);
nodeThree.setLeft(nodeFive);
nodeThree.setRight(nodeSix);
nodeFive.setLeft(nodeSeven);
BinaryTree.dfs(nodeOne);
}
}실행결과:
node Value = 10
node Value = 20
node Value = 40
node Value = 30
node Value = 50
node Value = 70
node Value = 60
코드를 보면 굉장히 간단하지만 이 코드가 DFS를 구현한 코드이다.
아래 그림을 가지고 위 코드를 돌려보는 시뮬레이션을 해보자.
1. [root = Node 1], root는 NULL이 아니니까 다음 라인으로 가서 printf호출 후 자기 자신을 호출하는데 주는 파라미터가 왼쪽 Child.
2. [root = Node 2], root는 NULL이 아니니까 다음 라인으로 가서 printf호출 후 자기 자신을 호출하는데 주는 파라미터가 왼쪽 Child.
3. [root = Node 4], root는 NULL이 아니니까 다음 라인으로 가서 printf호출 후 자기 자신을 호출하는데 주는 파라미터가 왼쪽 Child.
4. [root = NULL], root가 NULL이므로 return
5. 3으로 돌아옴. 자기 자신을 호출하는데 주는 파라미터가 오른쪽 Child.
6. [root = NULL], root가 NULL이므로 return
7. 3번으로 돌아옴 모든 라인이 끝났으니 return
8. 2번으로 돌아옴. 자기 자신을 호출하는데 주는 파라미터가 오른쪽 Child.
9. [root = NULL] root가 NULL이므로 return
10. 2번으로 돌아옴. 모든 라인이 끝났으니 return
11. 1번으로 돌아옴. 자기 자신을 호출하는데 주는 파라미터가 오른쪽 Child.
12. [root = Node 3], root는 NULL이 아니니까 다음 라인으로 가서 printf 호출 후 자기 자신을 호출하는데 주는 파라미터가 왼쪽 Child.
13. [root = Node 5], root는 NULL이 아니니까 다음 라인으로 가서 printf 호출 후 자기 자신을 호출하는데 주는 파라미터가 왼쪽 Child.
14. [root = Node 7], root는 NULL이 아니니까 다음 라인으로 가서 printf 호출 후 자기 자신을 호출하는데 주는 파라미터가 왼쪽 Child.
15. [root = NULL], root가 NULL이므로 return
16. 14번으로 돌아옴 자기 자신을 호출하는데 주는 파라미터가 오른쪽 Child.
17. [root = NULL], root가 NULL이므로 return
18. 14번으로 돌아옴. 모든 라인이 끝났으니 return
19. 13번으로 돌아옴. 자기 자신을 호출하는데 주는 파라미터가 오른쪽 Child.
20. [root = NULL], root가 NULL이므로 return
21. 13번으로 돌아옴. 모든 라인이 끝났으니 return
22. 12번으로 돌아옴. 자기 자신을 호출하는데 주는 파라미터가 오른쪽 Child.
23. [root = Node 6], root는 NULL이 아니니까 다음 라인으로 가서 printf 호출 후 자기 자신을 호출하는데 주는 파라미터가 왼쪽 Child.
24. [root = NULL], root가 NULL이므로 return
25. 23번으로 돌아옴. 자기 자신을 호출하는데 주는 파라미터가 오른쪽 Child.
26. [root = NULL], root가 NULL이므로 return
27. 23번으로 돌아옴. 모든 라인이 끝났으니 return
28. 12번으로 돌아옴. 모든 라인이 끝났으니 return
29. 1번으로 돌아옴. 모든 라인이 끝났으니 return
끝
이렇게 Recursion을 통해 DFS를 구현할 수 있다. 이제 BFS를 알아보자.
BFS (Breadth First Search)
BFS(Breadth First Search)는 넓이 우선 탐색으로 이것 역시 트리를 검색하는 방법 중 대표적인 하나이다.
이건 DFS랑 어떻게 다른지 그림을 통해 알아보자.
0단계

가장 최상위 노드인 Node 1을 검색한 후 다음 한 칸 밑에 있는 모든 노드를 쭉 털고, 그 다음 한 칸 밑에 있는 모든 노드를 쭉 털고, 이렇게 한 라인을 쭉 터는식으로 검색하는 방식이다.
1단계

2단계

3단계

4단계
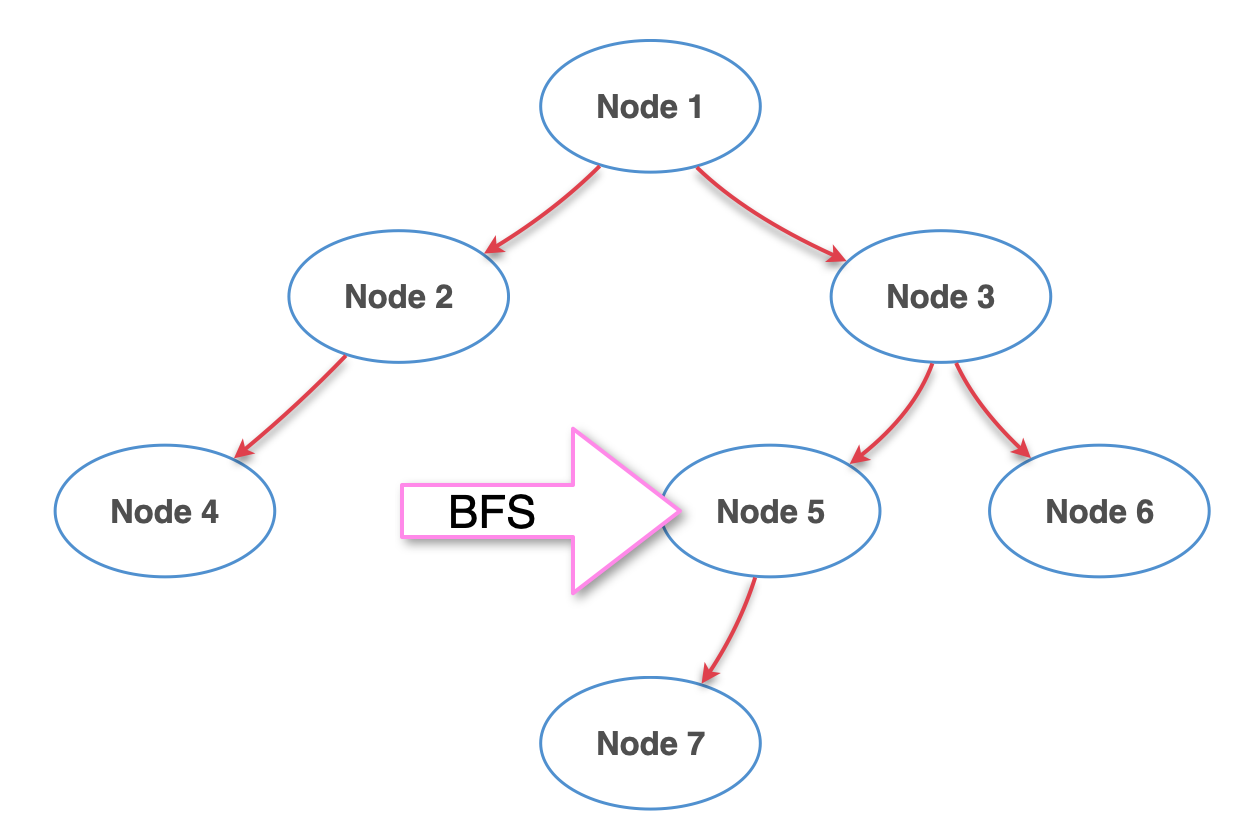
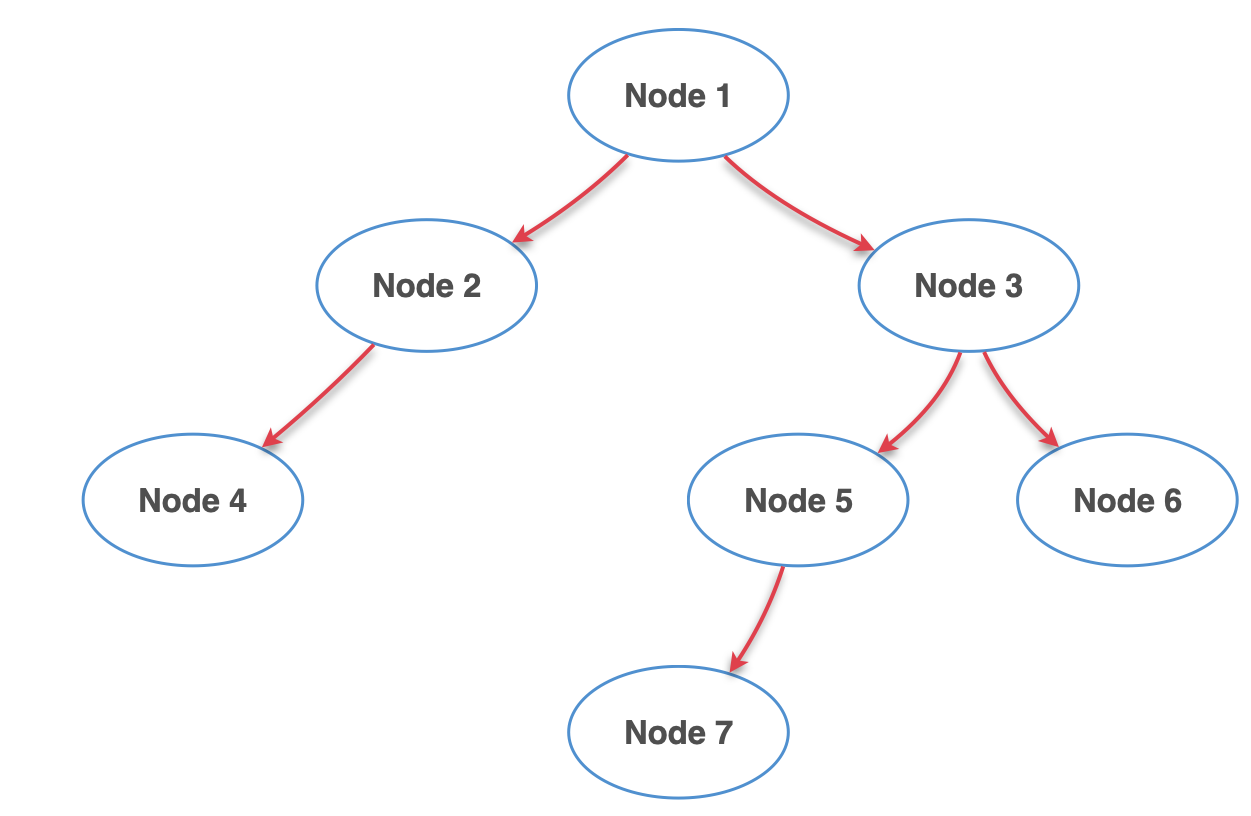
5단계
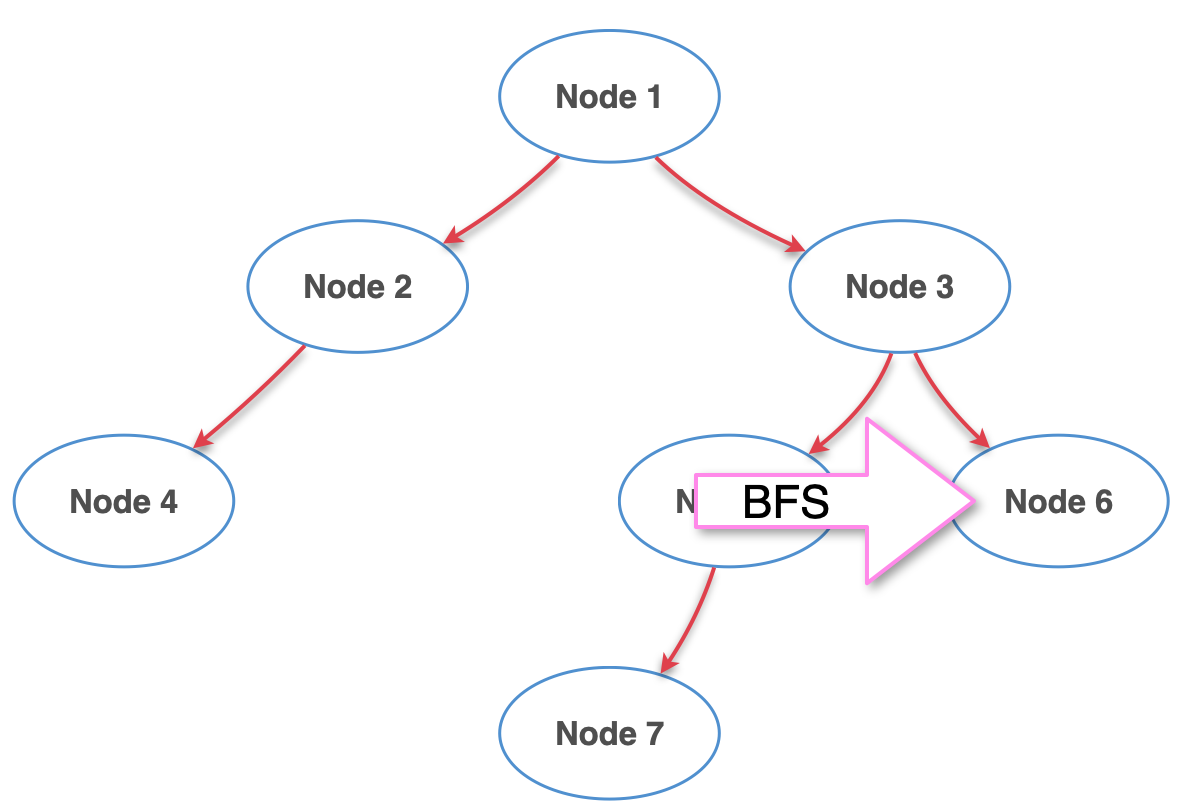
6단계
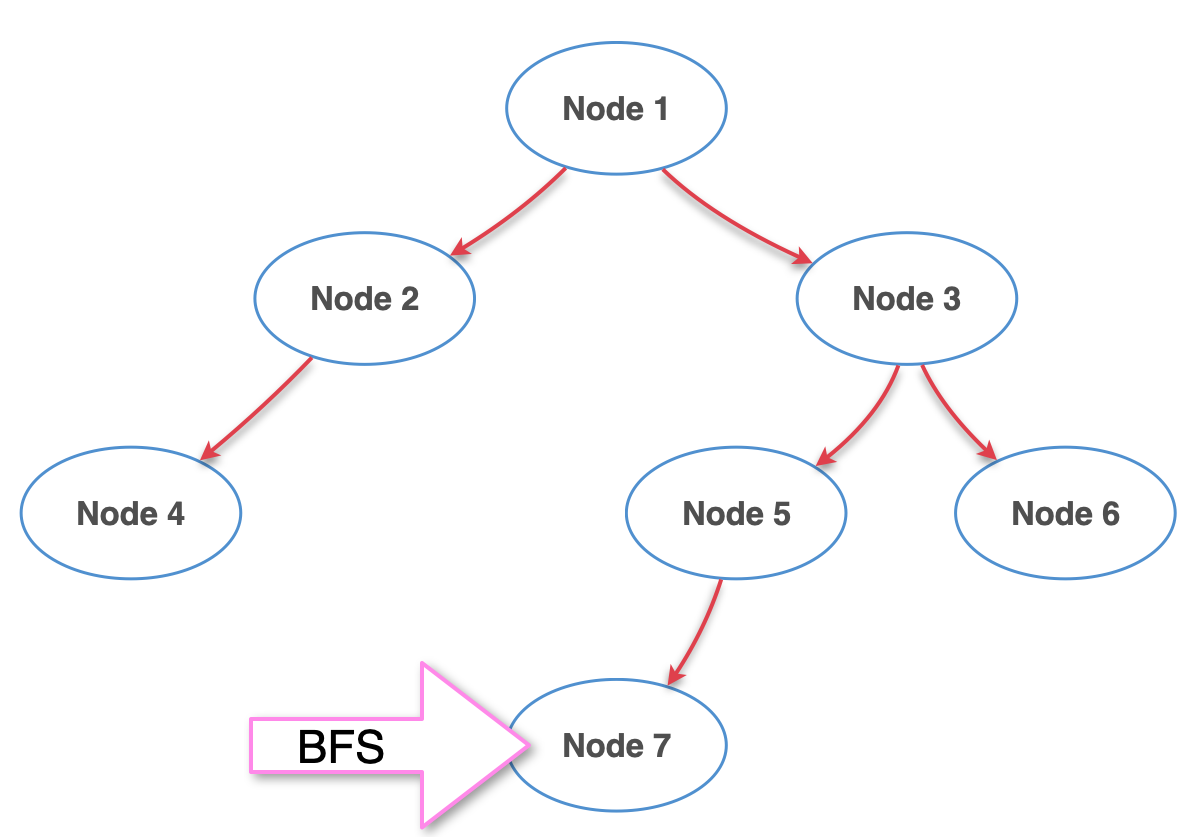
이렇게 트리의 한 라인 한 라인을 쭉 터는 방식으로 검색하는게 BFS라고 생각하면 된다.
이 BFS는 코드로 어떻게 구현할까?
BFS 코드로 구현하기
BFS(Breadth First Search)는 Queue로 간단하게 구현할 수 있다.
Queue는 저번 포스팅에서 배웠지만 FIFO구조. 그리고 Queue는 처음과 끝을 알아야하는 자료구조이다.
코드로 어떻게 구현하는지 살펴보자.
void bfs(struct Node* root) {
if (root == NULL) {
return;
}
struct TreeNode* queue[10000];
int front = 0;
int rear = 0;
queue[rear++] = root;
while (front != rear) {
struct TreeNode* curr = queue[front++];
printf("%d ", curr->val); // 실제 작업을 여기서 하면됨, 지금은 예제니까 출력을 함
if (curr->left != NULL) {
queue[rear++] = curr->left;
}
if (curr->right != NULL) {
queue[rear++] = curr->right;
}
}
}예제에서 Queue 사이즈는 어느정도 크게 설정했다. 어떤 문제를 푸냐에 따라 달라지겠지만 지금으로선 10000으로 충분하기 때문에.
이것도 그림과 같이 한단계씩 알아보자.
[root = Node 1]. root는 NULL이 아니다.
- queue를 만든다.

- Queue를 만들고 rear에 root(Node1)를 넣고 rear를 하나 추가한다.

- front와 rear는 같지 않기 때문에 while 루프를 돌기 시작한다.
- 여기서 queue의 front값인 Node1을 curr에 넣고, front를 하나 추가한다.
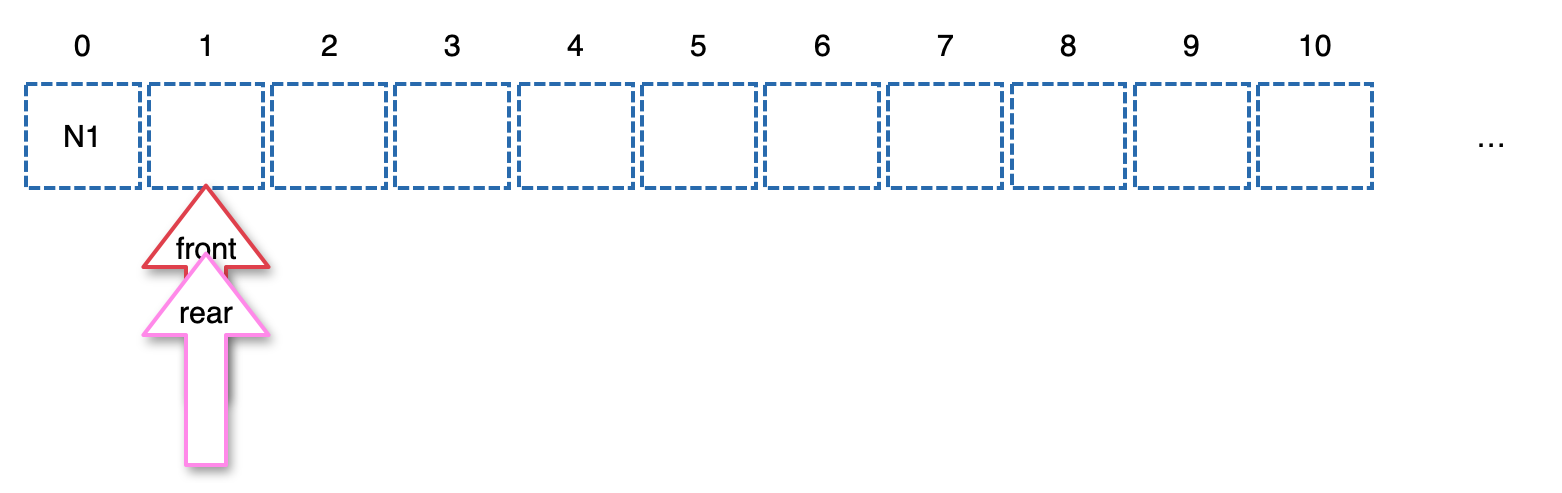
- curr의 값 1을 찍는다.
- Node1의 left child(Node2)가 NULL이 아니니까 rear 자리에 left child를 넣고 rear를 하나 추가한다.
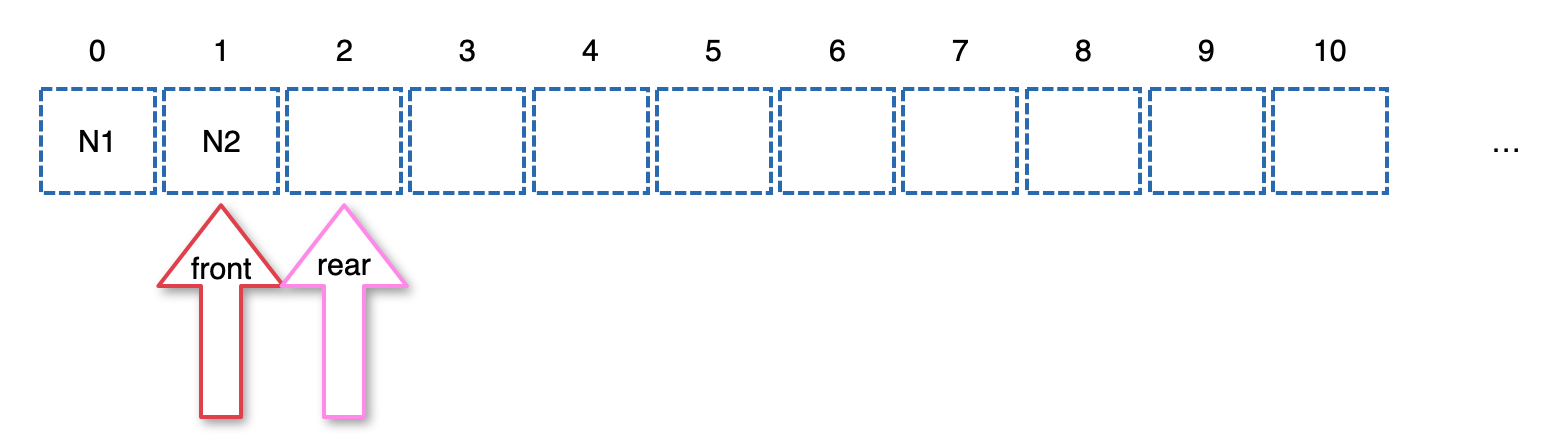
- Node1의 right child(Node3)가 NULL이 아니니까 rear자리에 right child를 넣고 rear를 하나 추가한다.

- 루프가 끝나고 역시 front와 rear는 다르니까 계속 돈다.
- curr에 front가 가리키는 Node2를 넣고 front를 하나 추가한다.

- curr의 값 2를 찍는다.
- Node2의 left child(Node4)가 NULL이 아니니까 rear 자리에 left child를 넣고 rear를 하나 추가한다.

- Node2의 right child는 NULL이니까 아무것도 하지 않고 루프가 끝난다.
- front와 rear가 다르니까 루프는 계속된다.
- 현재 front의 node(Node3)를 curr에 넣고 front를 하나 추가한다.

- curr의 값 3을 찍는다.
- Node3의 left child(Node5)가 NULL이 아니니까 rear에 left child를 넣고 rear를 추가한다.
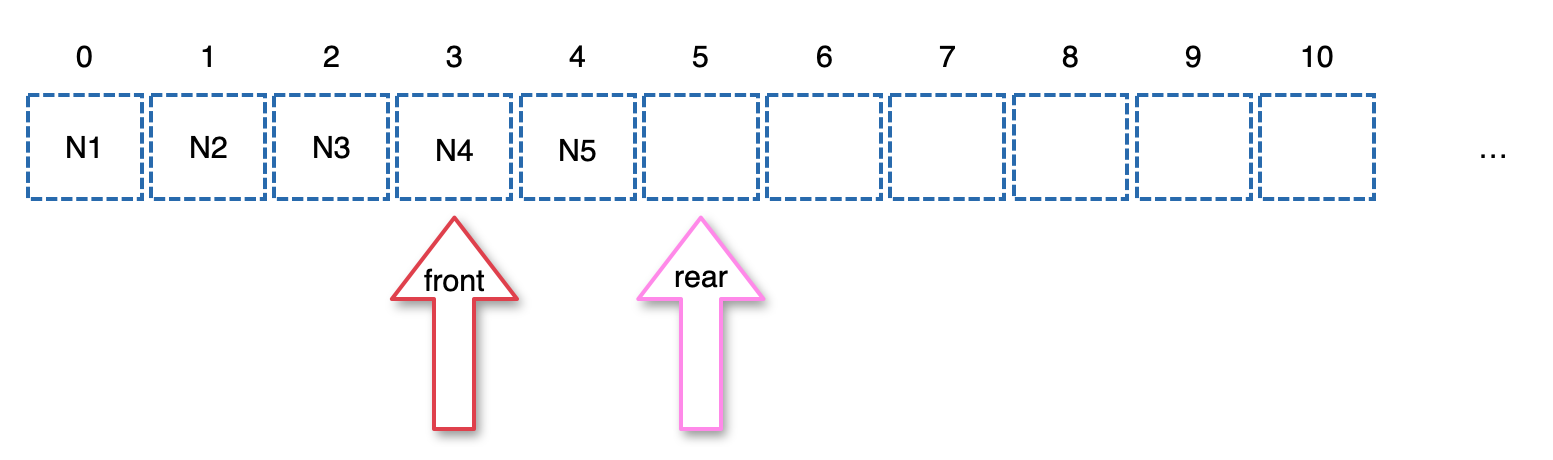
- Node3의 right child(Node6)가 NULL이 아니니까 rear에 right child를 넣고 rear를 추가한다.

- 루프가 끝나고 다시 front와 rear는 다르기 때문에 또 돈다.
- 현재 front가 가리키는 Node4를 curr에 집어넣고 front를 하나 추가한다.
- curr의 값 4를 찍는다.
- curr의 left child와 right child모두 NULL이니까 아무것도 하지 않고 다음 루프로 간다.
- front와 rear는 다르니까 루프가 계속된다.
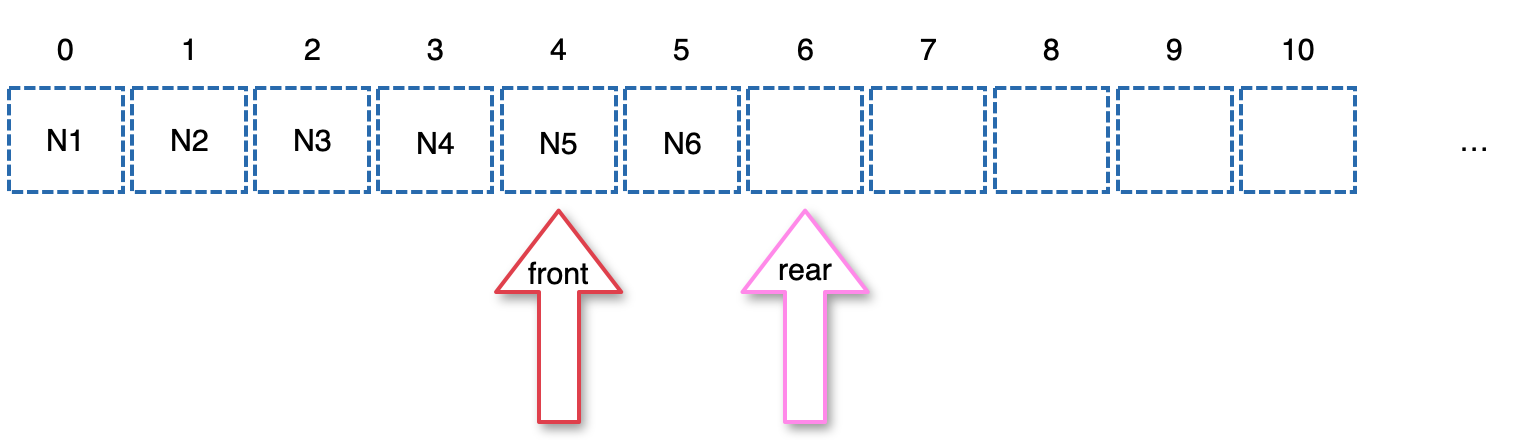
- 현재 front에 담긴 Node5를 curr에 담고 front를 하나 추가한다.
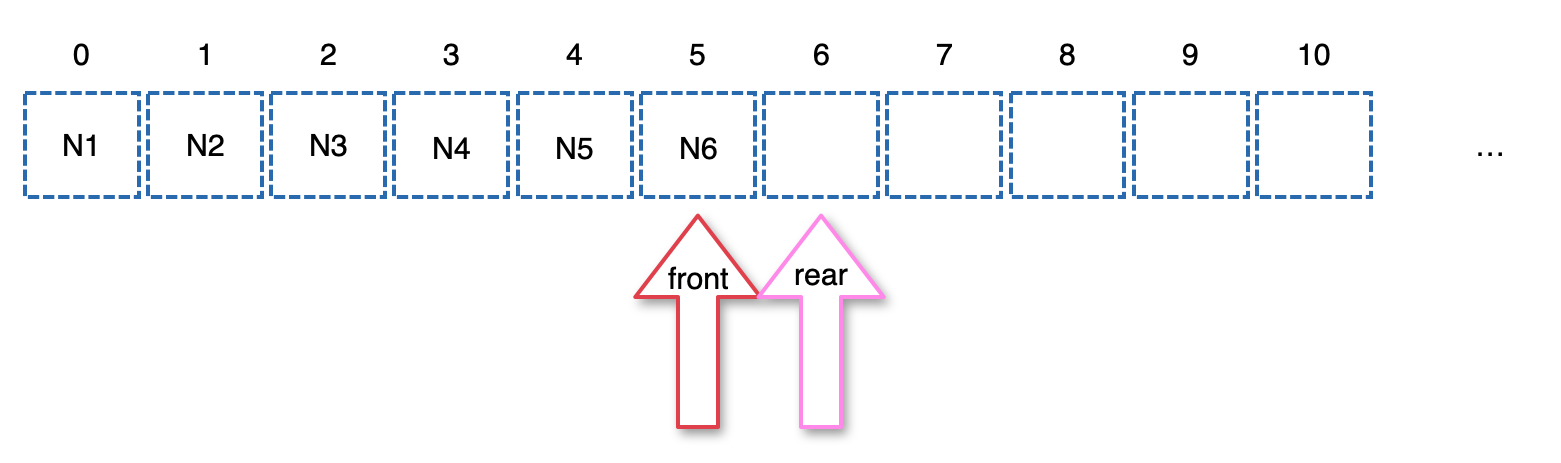
- curr의 값 5를 찍는다.
- curr의 left child(Node7)는 NULL이 아니니까 rear에 넣고 rear를 하나 추가한다.

- curr의 right child는 NULL이니까 다음 루프로 간다.
- 여전히 front와 rear는 다르니까 루프는 계속된다.
- 현재 프론트에 담긴 Node6을 curr에 담고 front를 하나 증가시킨다.

- curr의 값 6을 찍는다.
- curr의 left, right child가 모두 NULL이므로 아무것도 하지않고 다음 루프로 간다.
- 여전히 front와 rear는 다르기 때문에 루프는 계속된다.
- 현재 front가 가리키는 Node7을 curr에 넣고 front를 하나 추가한다.

- curr의 값 7을 찍는다.
- curr의 left, right child 모두 NULL이니까 루프가 끝난다.
- 루프의 조건 front != rear를 만족하지 않으므로 루프는 끝난다.
정리
DFS, BFS 모두 트리를 탐색할 때 방법 중 하나이다. DFS(Depth First Search)는 깊이 우선 탐색, BFS(Breadth First Search)는 넓이 우선 탐색의 줄임말로 둘 다 어떻게 탐색하는지 꼭 알아두면 좋을것같다.
'자료구조' 카테고리의 다른 글
| Hash Table (2) | 2024.04.16 |
|---|---|
| Binary Search Tree (0) | 2024.04.16 |
| Stack (0) | 2024.04.15 |
| Queue (0) | 2024.04.15 |
| Array vs Linked List (0) | 2024.04.15 |